Next: Mixture of Bernoulli Up: Clustering Analysis Previous: K-means clustering
In K-means clustering, each sample point  is assigned to
one of the
is assigned to
one of the  clusters if it has the minimum Euclidean distance
to the mean of the cluster. But here the distribution of the data
samples in the cluster represented by the covariance is not taken
into consideration.
clusters if it has the minimum Euclidean distance
to the mean of the cluster. But here the distribution of the data
samples in the cluster represented by the covariance is not taken
into consideration.
This issue can be addressed by the method of
Gaussian mixture model (GMM) based on the assumption
that each of the clusters
 in the given
dataset can be modeled by a Gaussian distribution
in the given
dataset can be modeled by a Gaussian distribution
 in
terms of both the mean vector
in
terms of both the mean vector  and covariance matrix
and covariance matrix
 . The overall distribution of the entire dataset
. The overall distribution of the entire dataset
![${\bf X}=[{\bf x}_1,\cdots,{\bf x}_N]$](img9.svg) is the weighted sum of the
Gaussian distributions:
is the weighted sum of the
Gaussian distributions:
 is the weight for the kth Gaussian
is the weight for the kth Gaussian
 , satisfying
, satisfying
 |
(210) |
 are estimated based on the given dataset, and then each sample in the
dataset is assigned to one of the clusters.
are estimated based on the given dataset, and then each sample in the
dataset is assigned to one of the clusters.
We note that the GMM model in Eq. (209) is actually the same
as Eq. (11) in the naive Bayes classification. These two
methods are similar in the sense that each cluster or classe  is modeled by a Gaussian
is modeled by a Gaussian
 ,
weighted by , and the model parameters and
,
as well as , are to be estimated based on the given dataset.
However, the two methods are different in that the dataset
,
weighted by , and the model parameters and
,
as well as , are to be estimated based on the given dataset.
However, the two methods are different in that the dataset  in the supervised naive Bayes method is labeled by
in the supervised naive Bayes method is labeled by  , while
in GMM such a labeling vector is not available. Instead, here we
will introduce a latent or hidden variable
, while
in GMM such a labeling vector is not available. Instead, here we
will introduce a latent or hidden variable
![${\bf z}=[z_1,\cdots,z_K]^T$](img784.svg) as the cluster labeling of the samples in the given dataset .
This latent variable
as the cluster labeling of the samples in the given dataset .
This latent variable  is binary vector, of which each component
is a binary random variable
is binary vector, of which each component
is a binary random variable
 . Only one of these
components is 1, e.g.,
. Only one of these
components is 1, e.g.,  , indicating a sample in the
dataset belongs to the kth cluster , while all others are 0, i.e.,
these binary variables add up to 1,
, indicating a sample in the
dataset belongs to the kth cluster , while all others are 0, i.e.,
these binary variables add up to 1,
 .
.
We further introduce the following probabilities for each of the
clusters
 :
:
 in the dataset to belong to , represented
by :
These prior probabilities add up to 1, i.e, the events
in the dataset to belong to , represented
by :
These prior probabilities add up to 1, i.e, the events
 are mutually exclusive and complementary,
as any sample belongs to one and only one of the
clusters.
are mutually exclusive and complementary,
as any sample belongs to one and only one of the
clusters.
, assumed
to be a Gaussian:
and :
 , we get the Gaussian mixture model, the distribution
, we get the Gaussian mixture model, the distribution
 of any sample regardless to which cluster
it belongs:
Note that Eqs. (211) through (214) are the
same as Eqs. (8) through (11) in the naive
Bayes classifier, respectively.
of any sample regardless to which cluster
it belongs:
Note that Eqs. (211) through (214) are the
same as Eqs. (8) through (11) in the naive
Bayes classifier, respectively.
All such probabilities defined for can be generalized to
for all clusters:
 |
 |
 |
(215) |
 |
|
 |
(216) |
 |
|
 |
(217) |
Given the dataset
containing
 i.i.d. samples, we introduce corresponding latent variables
in
i.i.d. samples, we introduce corresponding latent variables
in
![${\bf Z}=[{\bf z}_1,\cdots,{\bf z}_N]$](img801.svg) , of which the nth column
, of which the nth column
![${\bf z}_n=[z_{n1},\cdots,z_{nK}]^T$](img802.svg) is the labeling vector of
is the labeling vector of  ,
i.e., belongs to if
,
i.e., belongs to if  (while
(while  for all
for all  ). Note that here
is defined in the same way as
). Note that here
is defined in the same way as
![${\bf Y}=[{\bf y}_1,\cdots,{\bf y}_N]$](img806.svg) in
softmax regression, both as
the labeling of , with the only difference that
in
softmax regression, both as
the labeling of , with the only difference that  is
provided in the training data available for a supervised method, but
here
is
provided in the training data available for a supervised method, but
here  is a latent variable not part of the data provided for
unsupervised clustering. Now we have
is a latent variable not part of the data provided for
unsupervised clustering. Now we have
 |
(218) |
 to
be estimated can be expressed as:
as those that maximize
the likelihood function
to
be estimated can be expressed as:
as those that maximize
the likelihood function
 or its log function
or its log function
 , here we find the model parameters in
as those
that maximize the expectation of the log likelihood function above
with respect to the latent variables in in the following
two iterative steps of the EM method:
, here we find the model parameters in
as those
that maximize the expectation of the log likelihood function above
with respect to the latent variables in in the following
two iterative steps of the EM method:
We first find the posterior probability for an observed
to belong to cluster , indicated by (and
for all ):
has to belong to one of the clusters, these
posterior probabilities add up to 1, same ss the prior
probabilities
 :
:
 |
(222) |
 can be considered as the responsibility cluster takes
for . Once we have available all parameters on the
right-hand side of Eq. (221) for
can be considered as the responsibility cluster takes
for . Once we have available all parameters on the
right-hand side of Eq. (221) for  , it is used
to assign each sample to a cluster with the
maximun responsibility
, it is used
to assign each sample to a cluster with the
maximun responsibility
 .
.
We note that the definition of is similar to the
softmax function  with the only difference that here the weighted Gaussian function
are used instead of the softmax function used in softmax
regression.
with the only difference that here the weighted Gaussian function
are used instead of the softmax function used in softmax
regression.
We also note that the posterior probability defined above
represents a soft decision, in the sense that it is possible
for any to belong to any with probability
 for all
for all
 , instead of a hard decision, in the
sense that belongs to only one specific with
, instead of a hard decision, in the
sense that belongs to only one specific with
 , while
, while  for all , as in K-means clustering.
for all , as in K-means clustering.
We can now find the expectation of the log likelihood with respect
to the latent variables in :
 |
(224) |
We first set to zero the derivatives of the expectation of
the log likelihood with respect to each of the parameters in
 ,
and then solve the resulting equations to get the optimal parameters.
,
and then solve the resulting equations to get the optimal parameters.
:
As all of 's need to satisfy the constraint
 , we first construct the Lagrangian function
composed of an extra Lagrange multiplier term for the constraint
as well as the log likelihood as the objective function:
, we first construct the Lagrangian function
composed of an extra Lagrange multiplier term for the constraint
as well as the log likelihood as the objective function:
![$\displaystyle L(\theta,\,\lambda)
=\sum_{n=1}^N \sum_{k=1}^K P_{nk}
\left[\log ...
...bf x}_n,{\bf m}_k,{\bf\Sigma}_k)\right]
+\lambda\left(\sum_{k=1}^K P_k-1\right)$](img836.svg) |
(225) |
to zero:
 |
|
![$\displaystyle \frac{\partial}{\partial P_k} \left[
\sum_{n=1}^N \sum_{k=1}^K P_...
...{\bf m}_k,{\bf\Sigma}_k)\right]
+\lambda\left(\sum_{k=1}^K P_k-1\right) \right]$](img838.svg) |
|
|
 |
(226) |
, we get
where we have defined
that satisfies
 |
(229) |
, we get
 |
(230) |
 back into Eq. (227),
we get the expression for the prior
This is actually the same as the prior in Eq. (8)
in naive Bayes classification, but here
back into Eq. (227),
we get the expression for the prior
This is actually the same as the prior in Eq. (8)
in naive Bayes classification, but here  defined in
Eq. (228) is the sum of the probabilities for all
data samples to belong to , instead of the number of data
samples in (unknown in this unsupervised case).
defined in
Eq. (228) is the sum of the probabilities for all
data samples to belong to , instead of the number of data
samples in (unknown in this unsupervised case).
:
 indicates that we have neglected
the scaling coefficient
indicates that we have neglected
the scaling coefficient
 of
the Gaussian, which is independent of . Multiplying
of
the Gaussian, which is independent of . Multiplying
 on both sides, we get
on both sides, we get
 |
(233) |
we get
:
 |
(236) |
on both sides of the equation above
we get
 |
(237) |
, we get
 found
respectively in Eqs. (231), (234), and
(238) in the M-step depend on in Eq. (221)
in the E-step, which in turn is a function of these parameters, i.e.,
the E-step and M-step need to be carried out in an alternative and
iterative fashion from some initial values of the parameters until
convergence.
found
respectively in Eqs. (231), (234), and
(238) in the M-step depend on in Eq. (221)
in the E-step, which in turn is a function of these parameters, i.e.,
the E-step and M-step need to be carried out in an alternative and
iterative fashion from some initial values of the parameters until
convergence.
In summary, here is the EM clustering algorithm based on Gaussian mixture model:
, covariance
and
coefficient .
Find the responsibility for all data points and all
clusters and then :
 |
(239) |
Recalculate the parameters that maximize the likelihood function:
 |
|
 |
|
 |
|
 |
|
 |
|
 |
(240) |
to belong to cluster
 is
is
 , and it is therefore
assigned to if
, and it is therefore
assigned to if
 .
.
We can show that the K-means algorithm is actually a special case
of the EM algorithm, when all covariance matrices are the same
 , where
, where
 is a
scaling factor which appraoches to zero. In this case we have:
is a
scaling factor which appraoches to zero. In this case we have:
 |
(241) |
 to belong to cluster
is:
to belong to cluster
is:
 |
(242) |
 , all terms in the denominator approach
to zero, but the one with minimum
, all terms in the denominator approach
to zero, but the one with minimum
 approaches
to zero most slowly, and becomes the dominant term of the denominator.
If the numerator happens to be this term as well, then ,
otherwise the numerator approaches zero and
approaches
to zero most slowly, and becomes the dominant term of the denominator.
If the numerator happens to be this term as well, then ,
otherwise the numerator approaches zero and  . Now
defined above becomes:
. Now
defined above becomes:
 |
(243) |
defined in Eq.
(221) for a soft decision becomes a binary value
 for a hard binary decision to assign
to with the smallest distance. Also
for a hard binary decision to assign
to with the smallest distance. Also
 defined in Eq. (228)
as the sum of the posterior probabilities for all data
points to belong to becomes as the number of
data samples assigned only to . In other words, now
the probabilistic EM method based on both
defined in Eq. (228)
as the sum of the posterior probabilities for all data
points to belong to becomes as the number of
data samples assigned only to . In other words, now
the probabilistic EM method based on both  and
and
 becomes the deterministic K-means method based
on only.
becomes the deterministic K-means method based
on only.
We can also make a comparison between the GMM method for
unsupervised clustering and the softmax regression for
supervised classification. First, the latent variables
in GMM play a similar
role as the labeling
in
softmax regression
for
multi-class classificatioin. However, the difference is that
is explicitely given in the training set for a supervised
classification, while is hidden for an unsupervised
cllustering analysis. Second, we note that the probability
given in Eq. (221)
is similar to the softmax function
 in the softmax method in terms of their form, with the only
difference that the Gaussian function is used for GMM while the
exponential function is used for solfmax.
in the softmax method in terms of their form, with the only
difference that the Gaussian function is used for GMM while the
exponential function is used for solfmax.
Examples
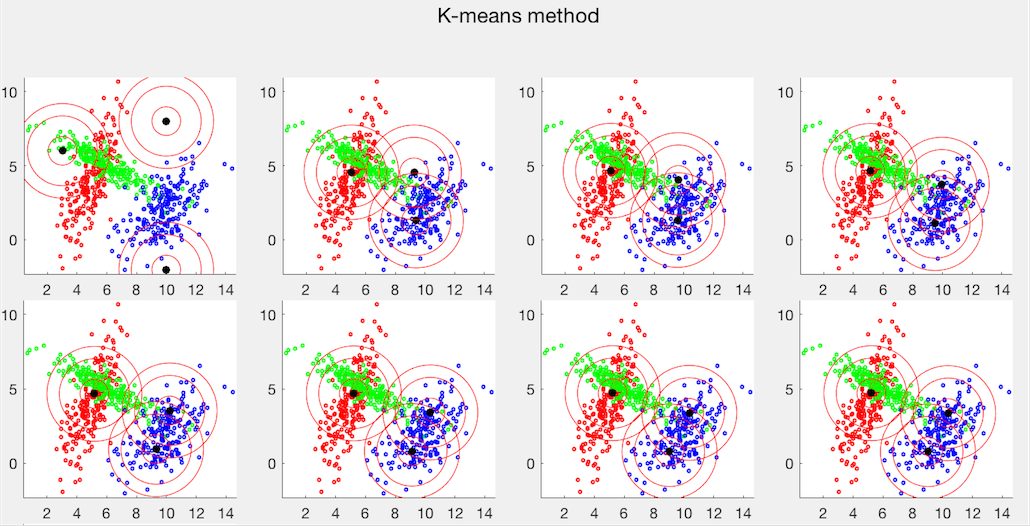
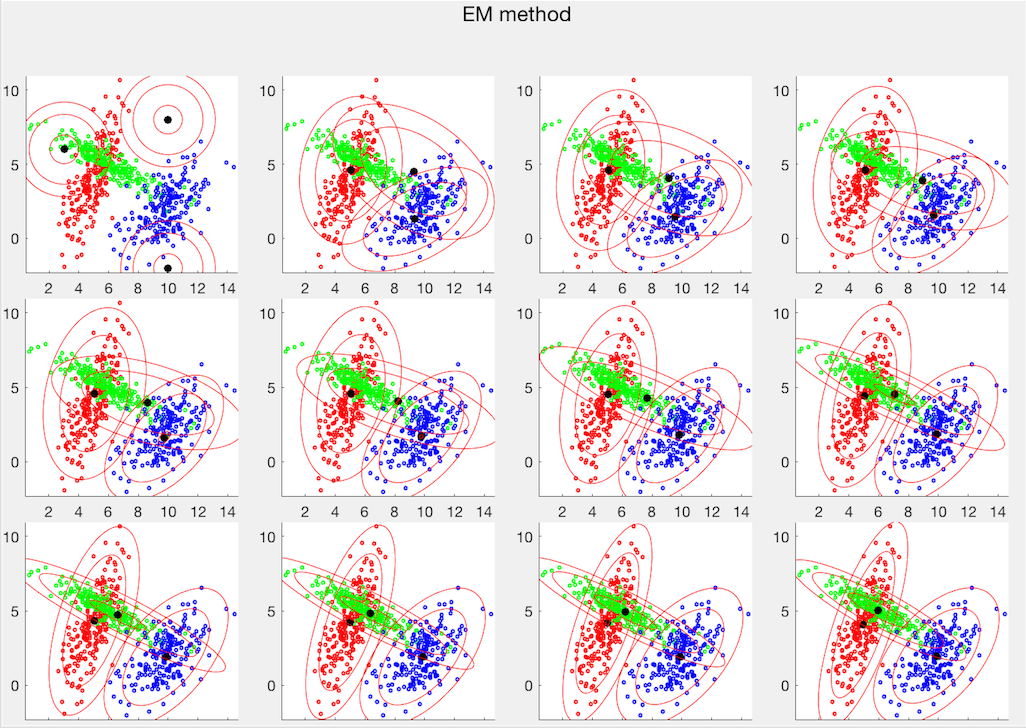
The same dataset is used to test both the K-means and EM clustering methods. The first panel shows 10 iterations of the K-means method, while the second panel shows 16 iterations of the EM method. In both cases, the iteration converges to the last plot. Comparing the two clustering results, we see that the K-means method cannot separate the red and green data points from two different clusters, both normally distributed with similar means but very different covariance matrices, while the blue data points all in the same cluster are separated into two clusters. But the EM method based on the Gaussian mixture model can correctly identified all three clusters.
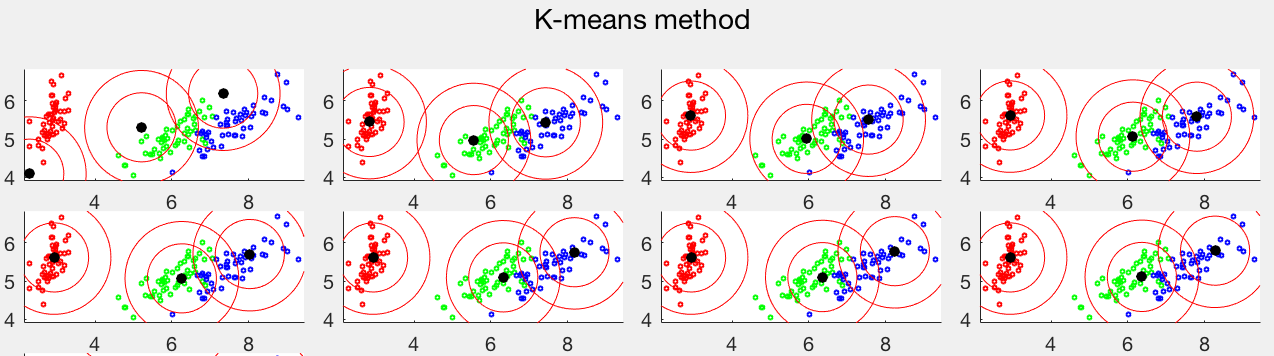
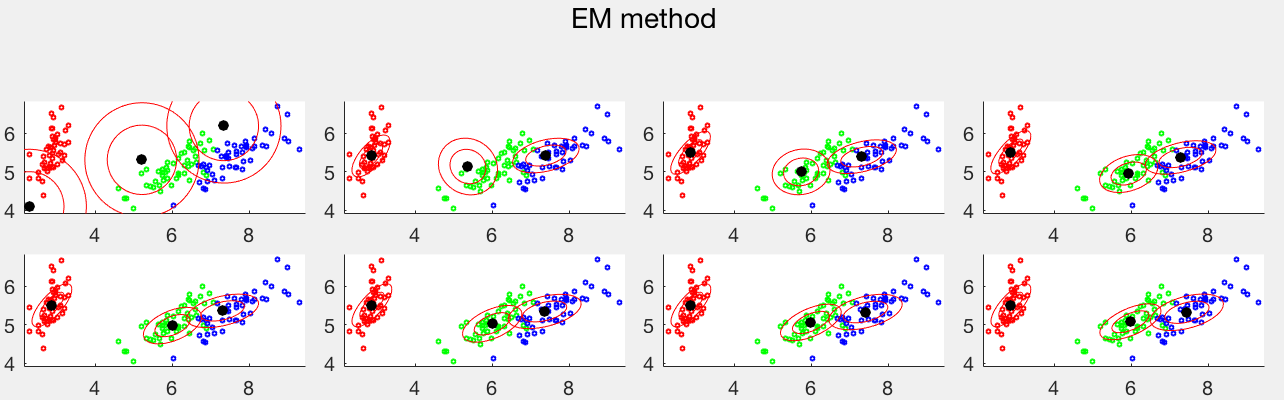
The two clustering methods are also applied to the Iris dataset, which has three classes each of 50 4-dimensional sample vectors. The PCA method is used to visualize the first two principal compnents, as shown below. Also, as can be seen from their c onfussion matrices, the error rate of the K-means method is 18/150, while that of the EM method is 5/150.
 |
(244) |
![$\displaystyle p({\bf x})=\sum_{k=1}^K P_k {\cal N}({\bf x}; {\bf m}_k,{\bf\Sigm...
...{1}{2}({\bf x}-{\bf m}_k)^T
{\bf\Sigma}_k^{-1}({\bf x}-{\bf m}_k)\right)\right]$](img779.svg)
 satisfying
satisfying




![$\displaystyle p({\bf X},{\bf Z}\vert\theta)
=p\left([{\bf x}_1,\cdots,{\bf x}_N...
...}_1,\cdots,{\bf z}_N]\bigg\vert{\bf m}_k,{\bf\Sigma}_k,P_k(k=1,\cdots,K)\right)$](img811.svg)


![$\displaystyle \log p({\bf X},{\bf Z}\vert\theta)
=\log \left[ \prod_{n=1}^N \pr...
...}^K
\left(P_k{\cal N}({\bf x}_n,{\bf m}_k,{\bf\Sigma}_k)\right)^{z_{nk}}\right]$](img814.svg)
![$\displaystyle \sum_{n=1}^N \sum_{k=1}^K z_{nk}
\left[\log P_k+\log {\cal N}({\bf x}_n,{\bf m}_k,{\bf\Sigma}_k)\right]$](img815.svg)




![$\displaystyle E_Z\left[\sum_{n=1}^N \sum_{k=1}^K z_{nk}
\left[\log P_k+\log {\cal N}({\bf x}_n,{\bf m}_k,{\bf\Sigma}_k)\right]\right]$](img830.svg)
![$\displaystyle \sum_{n=1}^N \sum_{k=1}^K E_Z(z_{nk})
\left[\log P_k+\log {\cal N}({\bf x}_n,{\bf m}_k,{\bf\Sigma}_k)\right]$](img831.svg)
![$\displaystyle \sum_{n=1}^N \sum_{k=1}^K P_{nk}
\left[\log P_k+\log {\cal N}({\bf x}_n,{\bf m}_k,{\bf\Sigma}_k)\right]$](img832.svg)




![$\displaystyle \frac{\partial}{\partial{\bf m}_k}
\left[\sum_{n=1}^N \sum_{l=1}^...
...}
\left[\log P_l+\log {\cal N}({\bf x}_n,{\bf m}_l,{\bf\Sigma}_l)\right]\right]$](img847.svg)


![$\displaystyle \sum_{n=1}^N P_{nk}\frac{\partial}{\partial{\bf m}_k}
\left[-\frac{1}{2}({\bf x}_n-{\bf m}_k)^T{\bf\Sigma}_k^{-1}({\bf x}_n-{\bf m}_k)\right]$](img850.svg)



![$\displaystyle \frac{\partial}{\partial{\bf\Sigma}_k}
\left[\sum_{n=1}^N \sum_{l...
...}
\left[\log P_l+\log {\cal N}({\bf x}_n,{\bf m}_l,{\bf\Sigma}_l)\right]\right]$](img858.svg)

![$\displaystyle -\frac{1}{2}\sum_{n=1}^N P_{nk}
\left[\frac{\partial}{\partial{\b...
...\Sigma}_k}({\bf x}_n-{\bf m}_k)^T{\bf\Sigma}_k^{-1}({\bf x}_n-{\bf m}_k)\right]$](img860.svg)
![$\displaystyle -\frac{1}{2}\sum_{n=1}^N P_{nk}
\left[{\bf\Sigma}_k^{-1}-{\bf\Sig...
...1}
({\bf x}_n-{\bf m}_k)({\bf x}_n-{\bf m}_k)^T{\bf\Sigma}_k^{-1}\right]={\bf0}$](img861.svg)
