Next: AdaBoost Up: ch9 Previous: K Nearest Neighbor and
The method of naive Bayes (NB) classification is a classical
supervised classification algorithm, which is first trained by a
training set of  samples
samples
![${\bf X}=[{\bf x}_1,\cdots,{\bf x}_N]$](img9.svg) and their corresponding labelings
and their corresponding labelings
![${\bf y}=[ y_1,\cdots,y_N]^T$](img10.svg) ,
and then used to classify any unlabeled sample
,
and then used to classify any unlabeled sample  into
class
into
class  with the maximumm posterior probability. As
indicated by the name, naive Bayes classification is based on
Bayes' theorem:
with the maximumm posterior probability. As
indicated by the name, naive Bayes classification is based on
Bayes' theorem:
 is the prior probability that any data sample
belongs to class without observing its values, more briefly
denoted by
is the prior probability that any data sample
belongs to class without observing its values, more briefly
denoted by  , which can be estimated by
where
, which can be estimated by
where  is the number of data samples in the training set
labeled to belong to class . This estimation is based on
the assumption that the training samples are evenly drawn from
the entire population, and are therefore a fair representation
of all
is the number of data samples in the training set
labeled to belong to class . This estimation is based on
the assumption that the training samples are evenly drawn from
the entire population, and are therefore a fair representation
of all  classes.
classes.
 is the likelihood for
any observed to belong to class , which is the
conditional probability of given that
is the likelihood for
any observed to belong to class , which is the
conditional probability of given that
 ,
assumed to be a
Gaussian
in
terms of the mean vector
,
assumed to be a
Gaussian
in
terms of the mean vector  and covariance matrix
and covariance matrix
 :
This assumption is based on the fact that the Gaussian distribution
has the maximum entropy (uncertainty) among all probability density
functions with the same covariance, i.e., it imposes the least amount
of unsupported constraint on the model for the dataset.
:
This assumption is based on the fact that the Gaussian distribution
has the maximum entropy (uncertainty) among all probability density
functions with the same covariance, i.e., it imposes the least amount
of unsupported constraint on the model for the dataset.
 is the joint probability of and :
is the joint probability of and :
 is the distribution of any data sample in the dataset,
independent of its classe identity, the weighted sum of all
likelihood
is the distribution of any data sample in the dataset,
independent of its classe identity, the weighted sum of all
likelihood
 for
for
 , i.e., the joint
probability
marginalized over all classes:
, i.e., the joint
probability
marginalized over all classes:
 is the posterior probability that a data sample
belongs to class based on the observed values in
is the posterior probability that a data sample
belongs to class based on the observed values in
![${\bf x}=[x_1,\cdots,x_d]^T$](img3.svg) .
.
Based on Bayes' theorem discussed above, the naive Bayes method
classifies an unlabeled data sample to class with
the maximum posterior probability (maximum a posteriori (MAP)):
is common to all classes (independent of
 ), it plays no role in the relative comparison among the
classes, and can therefore be dropped, i.e., is classified
to with maximal
), it plays no role in the relative comparison among the
classes, and can therefore be dropped, i.e., is classified
to with maximal
 .
.
The naive Bayes classifier is an optimal classifier in the sense
that the classification error is minimum. To illustrate this,
consider an arbitrary boundary between two classes  and
and  that partitions the 1-D feature space into two regions
that partitions the 1-D feature space into two regions  and
and
 , as shown below. The probability of a misclassification is
the joint probability
, as shown below. The probability of a misclassification is
the joint probability
 for a sample
for a sample
 but falling in
but falling in  . The total
probability of error due to misclassification can be expressed as:
. The total
probability of error due to misclassification can be expressed as:
 |
 |
 |
|
|
 |
||
|
 |
(13) |
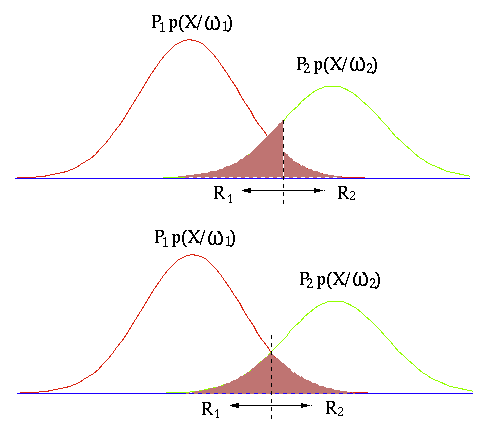
It is obvious that the Bayes classifier is indeed optimal, due to
the fact that its boundary
 between classes
between classes  and
and  (the bottom plot) guarantees the
classification error (shaded area) to be minimum.
(the bottom plot) guarantees the
classification error (shaded area) to be minimum.
To find the likelihood function
 , we need
to find and
based on the training set
, we need
to find and
based on the training set
 , based on the training samples
in class by the method of
maximum likelihood estimation:
, based on the training samples
in class by the method of
maximum likelihood estimation:
 |
(14) |
Once both  and
are available, the classifier is trained, and the posterior
can be calculated for the classification in
Eq. (12).
and
are available, the classifier is trained, and the posterior
can be calculated for the classification in
Eq. (12).
As the classification is based on the relative comparison of the
posterior
, any monotonic mapping of the posterior
can be equivalently used to simplify the computation, such as the
logarithmic function:
 |
|
![$\displaystyle \log \left[ p({\bf x}\vert C_k) P_k/p({\bf x}) \right]
=\log p({\bf x}\vert C_k) +\log P_k-\log p({\bf x})$](img108.svg) |
|
|
 |
(15) |
 and
and
 that are independent of the index and therefore play no role in
the comparison above, we get the quadratic discriminant function:
that are independent of the index and therefore play no role in
the comparison above, we get the quadratic discriminant function:
 |
(16) |
if then then |
(17) |
 |
(18) |
Geometrically, the feature space is partitioned into regions corresponding
to the classes by the decision boundaries between every pair of
classes and , represented by the equation
 ,
i.e.,
,
i.e.,
 |
|||
|
 |
(19) |
 |
(20) |
is classified into either of
the two classes and based on whether it is on the positive
or negative side of the surface::
We further consider several special cases:
 |
(23) |
 is zero, and we have
is zero, and we have
 |
(24) |
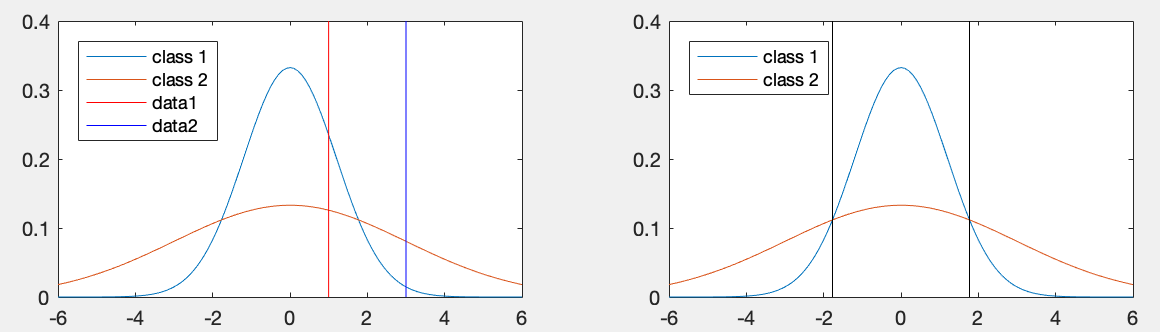
We can reconsider Example 2 in the previous section but now based on
the negative of the discriminant function above treated as a distance
 , and get
, and get
 |
(25) |
 is classified into class , while
is classified into class , while  into ,
as desired. The misclassification of to by the Mahalanobis
distance, the first term, is corrected, due to the addition of the second
term
into ,
as desired. The misclassification of to by the Mahalanobis
distance, the first term, is corrected, due to the addition of the second
term
 . The plot below shows the partitioning of the 1-D
space for the two classes and :
. The plot below shows the partitioning of the 1-D
space for the two classes and :
 ,
the discriminant function becomes:
,
the discriminant function becomes:
 |
(26) |
 are the same and the second term is dropped,
becomes the negative Mahalanobis distance.
are the same and the second term is dropped,
becomes the negative Mahalanobis distance.
The boundary equation
between and
becomes
 |
(27) |
 on both sides
of the equation are the same, it becomes a linear equation:
where
on both sides
of the equation are the same, it becomes a linear equation:
where
 |
(29) |
 |
(30) |
 and
and  and perpendicular to the straight line
and perpendicular to the straight line
 (the straight line
(the straight line
 rotated by matrix
rotated by matrix
 ).
).
![$\displaystyle {\bf\Sigma}_i={\bf\sigma}^2\,{\bf I}=diag[\sigma^2,\cdots,\sigma^2]$](img147.svg) |
(31) |
 and
becomes
and
becomes
 |
(32) |
 has been dropped from the original
expression of
as it is now the same for all classes.
has been dropped from the original
expression of
as it is now the same for all classes.
The boundary equation
becomes:
 |
(33) |
 |
(34) |
 |
(35) |
and and perpendicular to the straight line passing through these
points.
,
becomes
 |
(36) |
is equivalent to minimizing
 .
.
The Matlab functions for training and testing are listed low:
function [M S P]=NBtraining(X,y) % naive Bayes training
[d N]=size(X); % dimensions of dataset
K=length(unique(y)); % number of classes
M=zeros(d,K); % mean vectors
S=zeros(d,d,K); % covariance matrices
P=zeros(1,K); % prior probabilities
for k=1:K
idx=find(y==k); % indices of samples in kth class
Xk=X(:,idx); % all samples in kth class
P(k)=length(idx)/N; % prior probability
M(:,k)=mean(Xk'); % mean vector of kth class
S(:,:,k)=cov(Xk'); % covariance matrix of kth class
end
end
function yhat=NBtesting(X,M,S,P) % naive Bayes testing
[d N]=size(X); % dimensions of dataset
K=length(P); % number of classes
for k=1:K
InvS(:,:,k)=inv(S(:,:,k)); % inverse of covariance matrix
Det(k)=det(S(:,:,k)); % determinant of covariance matrix
end
for n=1:N % for each of N samples
x=X(:,n);
dmax=-inf;
for k=1:K
xm=x-M(:,k);
d=-(xm'*InvS(:,:,k)*xm)/2;
d=d-log(Det(k))/2+log(P(k)); % discriminant function
if d>dmax
yhat(n)=k; % assign nth sample to kth class
dmax=d;
end
end
end
end
The classification result in terms of the estimated class identity
 of the training samples compared with the ground
truth class labeling
of the training samples compared with the ground
truth class labeling  can be represented in the form of
a
can be represented in the form of
a  confusion matrix, of which the element in the ith
row and jth column is the number of training samples labeled as
a member of the ith class but actually classified into the jth
class. For an ideal classifier that classifies all data samples
correctly, this confussion matrix should be a diagonal matrix.
But for a nonideal classifier, its error rate can be found as
the percentage of the number of misclassified samples (sum of all
off-diagonal elements) out of the total number of samples. The
code below shows the function that generates such a confussion
matrix based on the estimated class identity
and
the ground truth labeling :
confusion matrix, of which the element in the ith
row and jth column is the number of training samples labeled as
a member of the ith class but actually classified into the jth
class. For an ideal classifier that classifies all data samples
correctly, this confussion matrix should be a diagonal matrix.
But for a nonideal classifier, its error rate can be found as
the percentage of the number of misclassified samples (sum of all
off-diagonal elements) out of the total number of samples. The
code below shows the function that generates such a confussion
matrix based on the estimated class identity
and
the ground truth labeling :
function [Cm er]=ConfusionMatrix(yhat,ytrain)
N=length(ytrain); % number of test samples
K=length(unique(ytrain)); % number of classes
Cm=zeros(K); % the confussion matrixxs
for n=1:N
i=ytrain(n);
j=yhat(n);
Cm(i,j)=Cm(i,j)+1;
end
er=1-sum(diag(Cm))/N; % error percentage
end
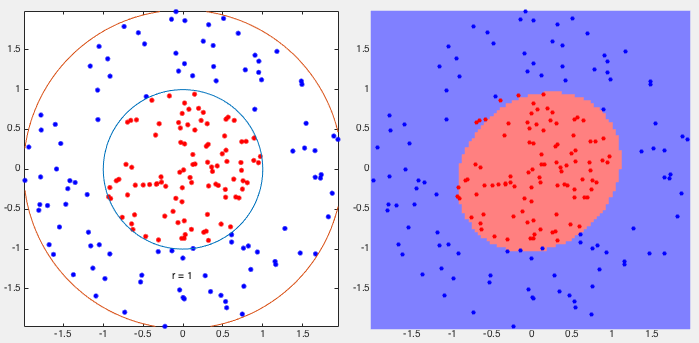
Example 1:
This example shows the classification of two cocentric classes with one
surrounding the other. They are separated by an ellipse with 9 out of
200 samples misclassified, i.e., the error rate of
 . The
confusion matrix is shown below:
. The
confusion matrix is shown below:
![$\displaystyle \left[\begin{array}{rrr}
92 & 8 \\
1 & 99 \\
\end{array}\right]$](img158.svg) |
(37) |
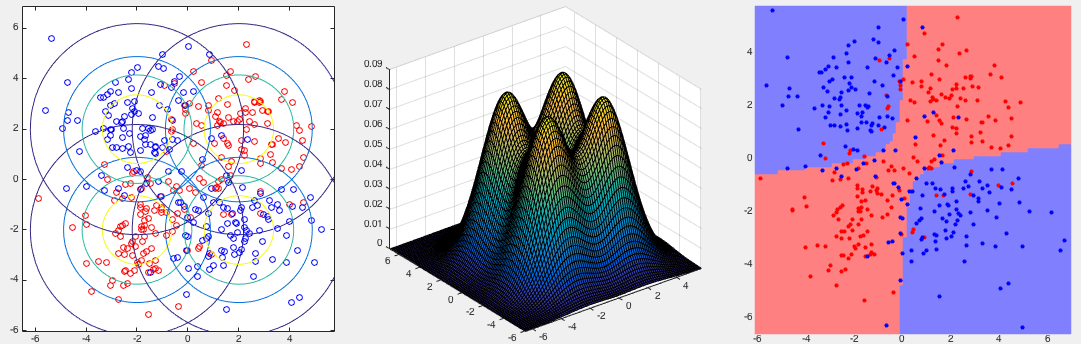
Example 2:
This example shows the classification of a 2-class exclusive-or (XOR)
data set with significant overlap, in terms of the confusion matrix and
the error rate of
 . Note that the decision boundaries
are a pair of hyperbolas. The confusion matrix is
. Note that the decision boundaries
are a pair of hyperbolas. The confusion matrix is
![$\displaystyle \left[\begin{array}{rrr}
175 & 25 \\
36 & 164 \\
\end{array}\right]$](img160.svg) |
(38) |
Example 3:
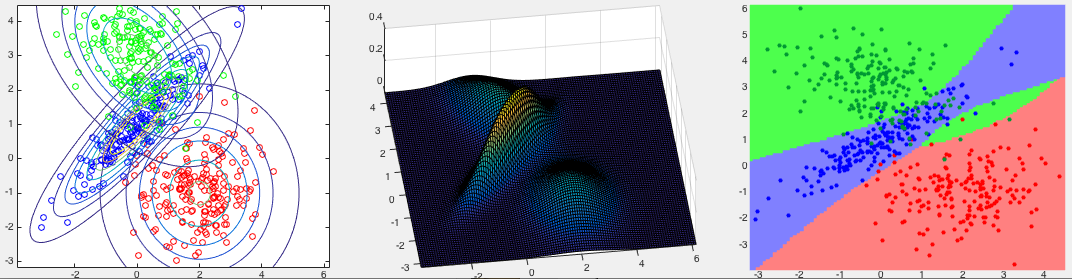
The first two panels in the figure below show three classes in the 2-D
space, while the third one shows the partitioning of the space corresponding
to the three classes. Note that the boundaries between the classes are all
quadratic. The confusion matrix of the classification result is shown below,
with the error rate
 .
.
![$\displaystyle \left[\begin{array}{rrr}
196 & 3 & 1 \\
0 & 191 & 9 \\
3 & 33 & 164 \\
\end{array}\right]$](img162.svg) |
(39) |
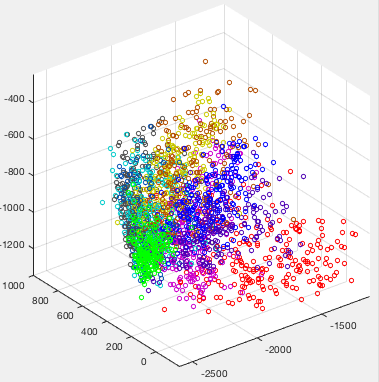
Example 4
The figure below shows some sub-samples of ten sets digits from 0 to 9, each is hand-written 224 times by different students. Each hand-written digit is represented as an 16 by 16 image containing 256 pixels, treated as a 256 dimensional vector.

The dataset can be visualized by applying the KLT transform to map all data points in the 256-D space into a 3-D space spanned by the three eigenvectors corresponding to the three greatest eigenvalues of the covariance matrix of the dataset, as shown below:
The naive Bayes classifier is applied to the dataset of handwritten
digits from 0 to 9, of which each data sample is a 256-dimensional
vector composed of
 pixels of an image for the
handwritten of a digit. The dataset contains 224 samples per class
and
pixels of an image for the
handwritten of a digit. The dataset contains 224 samples per class
and  in total for all
in total for all  classes.
classes.
We note that the 256-dimensional covariance matrix
for each of the classes is estimated by the 224 samples in
the class, i.e., the estimated covariance matrix does not have a
full rank and is not invertible. This issue can be resolved by
applying KLT to the dataset to reduce its dimensionality from
256 to some value smaller than 224, such as 100.
The classifier is trained on half of
the dataset of 1120 randomly selected samples and then tested on the
remaining 1120 samples. The classification results are given below
in terms of the confusion matrices of the traing samples (left) and
the testing samples (right). All 1120 training samples are correctly
classfied, while out of the remaining 1120 test samples, 198 are
misclassified ( error).
error).
![$\displaystyle \left[ \begin{array}{rrrrrrrrrr}
107 & 0 & 0 & 0 & 0 & 0 & 0 & 0 ...
... 18 & 109 & 9 \\
0 & 3 & 0 & 0 & 2 & 0 & 0 & 2 & 0 & 90 \\
\end{array}\right]$](img167.svg) |
(40) |

 satisfying
satisfying
![$\displaystyle p({\bf x}\vert C_k)=N({\bf x},{\bf m}_k,{\bf\Sigma}_k)
=\frac{1}{...
...[-\frac{1}{2}({\bf x}-{\bf m}_k)^T{\bf\Sigma}_k^{-1}
({\bf x}-{\bf m}_k)\right]$](img82.svg)

![$\displaystyle p({\bf x})=\sum_{k=1}^K p({\bf x},C_k)=\sum_{k=1}^K P_k \,p({\bf ...
...1}{2}({\bf x}-{\bf m}_k)^T{\bf\Sigma}_k^{-1}
({\bf x}-{\bf m}_k)\right) \right]$](img87.svg)
 then
then






 then
then