Next: Monte Carlo (MC) Algorithms Up: Introduction to Reinforcement Learning Previous: Model-Based Planning
The previously discussed dynamic programming methods find
the optimal policy based on the assumption that the MDP
model of the environment is completely available, i.e.,
the dynamics of MDP in terms of its state transition and
reward mechanism are known. A given policy  can then
be evaluated based the transition probabilities
can then
be evaluated based the transition probabilities  ,
and improved based on greedy action selection at each
state. Such a model-based optimization problem, called
planning, involves no learning of the environment.
,
and improved based on greedy action selection at each
state. Such a model-based optimization problem, called
planning, involves no learning of the environment.
Now we consider the optimization problem with an unknown MDP model of the environment. In this model-free problem, called control, the state transition and reward probabilities of the MDP model are unknown, the value functions can no longer be calculated directly based on Eqs. (21) and (22) as in model-based planning. Instead, now we need to learn the MDP model by sampling the environment, i.e., by repeatedly running a large number of episodes of the stochastic process of the environment while following some given policy, and estimate the value functions as the average of the actual returns received during the sampling process. This method is generally referred to as Monte Carlo (MC) method. At the same time, the given policy can also be improved to gradually approach optimality.
This approach is called general policy iteration (GPI), as illustrated in Eq. (40) below, similar to the policy iteration (PI) algorithm for model-based planning illustrated in Eq. (37). In general, all model-free control algorithms are based on GPI by which the two alternating processes of policy evaluation and policy imprvement are carried out iteratively. This GPI can also be similarly illustrated in Fig. 1.3 for the GI.
While GPI and GI illustrated in respectively in Eqs. (40) and (37) may look similar to each other, there are some essential differences between the two, as listed below.
 , instead
of the state value function
, instead
of the state value function  in model-based
planning. This is because without the a specific MDP
model the state value function can no longer be calculated,
while the action value function can still be estimated
based on the actual rewards received while sampling the
environment. Similar to how we improve the policy by
taking a greedy action to achive a higher state value
in model-based planning, here we improve the policy by
taking an action different from that dictated by the
given policy to achieve a higher action value based
on some
in model-based
planning. This is because without the a specific MDP
model the state value function can no longer be calculated,
while the action value function can still be estimated
based on the actual rewards received while sampling the
environment. Similar to how we improve the policy by
taking a greedy action to achive a higher state value
in model-based planning, here we improve the policy by
taking an action different from that dictated by the
given policy to achieve a higher action value based
on some  -greedy method, as discussed below.
-greedy method, as discussed below.
 (Eq. (27))
during policy improvement. However, here in model-free
control, we have to learn the action value
, as
a function of action
(Eq. (27))
during policy improvement. However, here in model-free
control, we have to learn the action value
, as
a function of action  as well as state
as well as state  by
sampling the environment. Such an estimated action value
based only on some partial sample data is inevitably noisy,
especially in the early stage of learning when many of the
states have not yet been visited yet. We therefore need to
explore all actions at each state to better learn
the value function, as well as to exploit the greedy
action to improve the policy.
by
sampling the environment. Such an estimated action value
based only on some partial sample data is inevitably noisy,
especially in the early stage of learning when many of the
states have not yet been visited yet. We therefore need to
explore all actions at each state to better learn
the value function, as well as to exploit the greedy
action to improve the policy.
This issue of exploration versus exploitation
can be addressed by the -greedy method
to make a proper trade-off between the exploitation of
the greedy action and the exploration of other non-greedy
actions, so that the agent can be exposed to all possible
state-action pairs and gradually learn the action value
function while at the same time also improve the policy
being followed. In this method, we define
![$\epsilon\in[0,\;1]$](img200.svg) as the probability to explore any randomly chosen action
as the probability to explore any randomly chosen action
 out of all actions available in state ,
each with an equal probability
out of all actions available in state ,
each with an equal probability
 , and
, and
 is the probability of taking the greedy
action as one of the
is the probability of taking the greedy
action as one of the  actions, with probability
actions, with probability
 .
.
For example, if
 and
and
 ,
the greedy action may be chosen with probability
,
the greedy action may be chosen with probability
 , while each of the remaining
three non-greedy actions may be chosen with probability
, while each of the remaining
three non-greedy actions may be chosen with probability
 . Such a policy describes the behavior
of the agent, and is therefore called behavior policy,
different from the policy being followed.
. Such a policy describes the behavior
of the agent, and is therefore called behavior policy,
different from the policy being followed.
We further note that a larger value of (close to
1) can be used to emphasize exploration at the early stage
of the iteration when many state-action pairs have not been
visited yet, while progressively smaller values
(approaching to 0) can be used to amphasize exploitation for
higher values in the later stage of the iteration when the
action value function has been more reliably learned. For
example, we can let
 be inversely proportional
to the current number of iterations
be inversely proportional
to the current number of iterations  , so that the larger
values at the early stage of the iteration allow
more sate-action pairs to be explored, while smaller
values in the later stage of the iteration
encourage exploitation of the greedy actions. To the limit
, so that the larger
values at the early stage of the iteration allow
more sate-action pairs to be explored, while smaller
values in the later stage of the iteration
encourage exploitation of the greedy actions. To the limit
 and
and
 , the
-greedy method approaches absolute greedy method.
, the
-greedy method approaches absolute greedy method.
Similar to how we proved the policy improvement theorem
in Eq. (30) stating that the greedy
policy  achieves state value
achieves state value
 no lower
than achieved by the original policy , i.e.,
no lower
than achieved by the original policy , i.e.,
 , here we can also prove the same policy
improvement theorem stating that the -greedy
policy
, here we can also prove the same policy
improvement theorem stating that the -greedy
policy  achieves action value
achieves action value
 no lower
than
by the original policy :
no lower
than
by the original policy :
 |
 |
 |
|
|
 |
||
 |
 |
(42) |
is no less than the average of action
values
over all weighted by some
normalized coefficients adding up to 1:
 |
(43) |
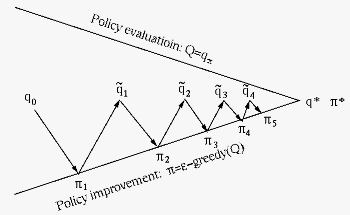
The iterative process of the GPI method for model-free
control is illustrated in the figure below, similar to
the PI method for model-based planning based planning
illustrated in Fig. 1.3, but with the state
value replaced by the action value
,
and the greedy method replaced by -greedy method.
Also, here the estimated action value  is
obtained with only one iteration for policy evaluation,
instead of a much more accurate estimate that could
otherwise be obtained if the iterative evaluation was
fully carried out to its convergence (the top line).
At the same the time, based on the estimated
policy improvement is carried out by the -greedy
method (the bottom line).
is
obtained with only one iteration for policy evaluation,
instead of a much more accurate estimate that could
otherwise be obtained if the iterative evaluation was
fully carried out to its convergence (the top line).
At the same the time, based on the estimated
policy improvement is carried out by the -greedy
method (the bottom line).
The main task in model-free control is to evaluate
the state and action-value functions given in
Eqs. (21) and (22)
while following a given policy without a specific
MDP model. This is done by sampling of the dynamic process
of the environment, and then estimating the value functions
as the average of the actual returns received by the agent.
Specifically, we run a large number of episodes (all assumed
to terminate) of the MDP model of the environment by taking
actions
 in each state
in each state
 :
:
 |
(45) |
 actually received from these episodes.
actually received from these episodes.

Such a sequence of states visited is called a trajectory, and the trajectories of different episodes are in general different from each another due to the random nature of the environment. In the following sections we will consider specific algoithms for the implementation of the general model-free control discussed above.
To prepare for specific discussion of the GPI methods, we
first consider a general problem of the estimation of the
value of a random variable  as the running average of
its samples beging collected in real time. Speicically
the average
as the running average of
its samples beging collected in real time. Speicically
the average  based on previous
based on previous  samples
samples
 is updated incrementally upon receiving
a new sample
is updated incrementally upon receiving
a new sample  :
:
 |
|
 |
|
|
 |
(46) |
| newEstimate | |
oldEstimate stepSize stepSize target target oldEstimate oldEstimate |
|
|
oldEstimatestepSize error error |
||
|
oldEstimateincrement |
(48) |
 between the old average and the latest
sample , and the second term is the gradient
between the old average and the latest
sample , and the second term is the gradient
 weighted by the step
size
weighted by the step
size
![$\alpha\in[0,\;1]$](img244.svg) , which controls how samples
are weighted differently. In the extreme case when
, which controls how samples
are weighted differently. In the extreme case when
 ,
,
 with no contribution
from any previous samples; on the other hand when
with no contribution
from any previous samples; on the other hand when
 is close to 0, , the most recent
samples has little contribution. We can therefore
properly adjust to fit our specific need.
For example, if we gradually reduce , then the
estimated average will become stabilized while enough
samples have been collected. On the other hand, if we
let
is close to 0, , the most recent
samples has little contribution. We can therefore
properly adjust to fit our specific need.
For example, if we gradually reduce , then the
estimated average will become stabilized while enough
samples have been collected. On the other hand, if we
let
 , the more recent samples are
weighted more heavily than the earlier ones. Such a
stratigy is suitable when estimating parameters of a
nonstationary system, such as an MDP with varying
behaviors when the policy is being modified continuously.
, the more recent samples are
weighted more heavily than the earlier ones. Such a
stratigy is suitable when estimating parameters of a
nonstationary system, such as an MDP with varying
behaviors when the policy is being modified continuously.
Specifically in model-free control Eq. (47)
can be used to iteratively update the estimated value
functions while sampling the environment. Both the
state and action values as the expected return are
estimated as the average of all previous sample returns,
and they are updated incrementally when a new sample
return  , the target, becomes available:
, the target, becomes available: