Next: TD() Algorithm Up: Model-Free Evaluation and Control Previous: Monte Carlo (MC) Algorithms
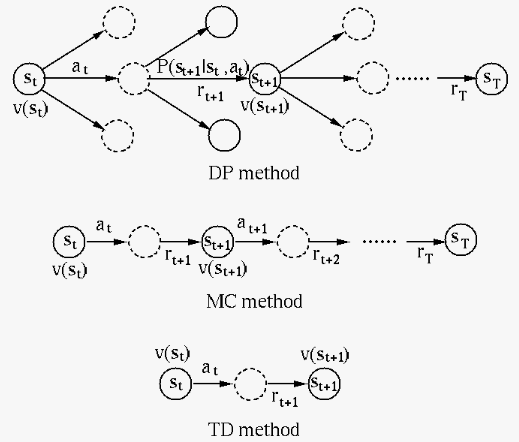
The temporal difference (TD) method is a combinaion of the
MC method considered above and the bootstrapping DP method
based on the Bellman equation. The main difference between
the TD and MC methods is the target, the return  , in
the incremental average in Eq. (49) for
estimating either the state or action value functions.
While in the MC method the target is the actual return
, in
the incremental average in Eq. (49) for
estimating either the state or action value functions.
While in the MC method the target is the actual return  calculated at the end of the episode when all subsequent
rewards
calculated at the end of the episode when all subsequent
rewards
 are available, here in the TD
method the target, called TD target, is the sum of
the immediate reward
are available, here in the TD
method the target, called TD target, is the sum of
the immediate reward  and the previouosly estimated
value
and the previouosly estimated
value
 at the next state:
at the next state:
 |
(51) |
Again, we first consider the simpler problem of policy
evaluation. As in the MC method, we estimate the value
function  as the average of the actual returns
found by running multiple episodes while sampling
the environment. Substituting this TD target into the
running average in Eq. (49) for the
value function above, we get
as the average of the actual returns
found by running multiple episodes while sampling
the environment. Substituting this TD target into the
running average in Eq. (49) for the
value function above, we get
 , called the TD error, is the
difference between the TD target and the previous
estimate:
and
, called the TD error, is the
difference between the TD target and the previous
estimate:
and  is the current estimatee of the value
of the next state (bootstrapping). It can be shown that
the iteration of this TD method converges to the true
value , if the step size is small enough.
is the current estimatee of the value
of the next state (bootstrapping). It can be shown that
the iteration of this TD method converges to the true
value , if the step size is small enough.
Here is the pseudo code for policy evaluation using the
TD method, based on parameters  and
and  :
:
 to be evaluated
to be evaluated
 for all
for all  arbitrarily,
arbitrarily,
 for terminal state
for terminal state  ,
,
![$\alpha\in(0,\;1]$](img289.svg)
 is not terminal (for each step)
is not terminal (for each step)
 , get reward
, get reward  and
next state
and
next state 
![$v(s)=v(s)+\alpha[ r+\gamma v(s')-v(s)]$](img291.svg)

As the TD algorithm updates the value function at every step of the episode, it uses the sample data more frequently and efficiently, and therefore has lower variance error than the CM method that updates the estimated value function at the end of each episode. On the other hand, the TD method may be biased when compared to the first-visit MC method, due to the arbitrary initialization of the value functions.
Based on the TD method for model-free policy evaluation,
we now further consider the TD method for model-free
control to gradually learn the optimal policy by updading
the Q-values of all state-action pairs  estimated
iteratively as the running average of the sample Q-values
at each time step of an episode while sampling the
environment.
estimated
iteratively as the running average of the sample Q-values
at each time step of an episode while sampling the
environment.
The Q-values for all state-action pairs can be stored in a state-action table which is iteratively updated by running many episodes of the unknown MDP by the TD method to gradually approach the maximum Q-values achievable by taking each action at each state, i.e., the optimal action is the one with the highest Q-value.
This method has two different flavors, the on-policy
algorithm, which updates the Q-value by following the
current policy such as an  -greedy policy, and
the off-policy algorithm, which updates the Q-value
by taking actions different from the current policy such
as the greedy action. In particular, if the policy currently
being followed is greedy (instead of -greedy),
the two algorithms are the same.
-greedy policy, and
the off-policy algorithm, which updates the Q-value
by taking actions different from the current policy such
as the greedy action. In particular, if the policy currently
being followed is greedy (instead of -greedy),
the two algorithms are the same.
The Q-value  of each state-action pair
is estimated as the running average of the return ,
the sum of the immmediate reward and the action
value
of each state-action pair
is estimated as the running average of the return ,
the sum of the immmediate reward and the action
value  of the next state based on action
of the next state based on action  dictated by the current policy (e.g.,-greedy):
dictated by the current policy (e.g.,-greedy):
 |
 |
 |
|
 |
 |
(54) |
This algorithm is called SARSA, as it updates
the Q-value based on the current state and action
 , the immediate reward , and the next state
and action . The pseudo code of SARSA algorithm is
listed below.
, the immediate reward , and the next state
and action . The pseudo code of SARSA algorithm is
listed below.
 for all ,
,
for all ,
,
 ,
denote -greedy policy
,
denote -greedy policy  by
according to based on
is not terminal (for each step)
, get reward and next state
according to based on
by
according to based on
is not terminal (for each step)
, get reward and next state
according to based on 
![$q(s,a)=q(s,a)+\alpha [r+\gamma q(s',a')-q(s,a)]$](img301.svg)

As a variation of SARSA, the expected SARSA updates
the Q-value at state based on the expected Q-value
of the next state , the weighted average of the
Q-values resulting from all possible actions, instead of
only one action. Consequently, the estimated Q-values by
the expected SARSA have lower variance than SARSA, and a
higher learning rate can be used to speed up the
learning process.
 |
(55) |
Same as SARSA, the Q-learning algorithm also estimates
the Q-value of each state-action pair
as the running average of the return , the sum of the
immmediate reward and the action value of
the next state based on the greedy action that
maximizes the next state value , different from
that dictated by the current policy.
 |
(56) |
The pseudo code of SARSA algorithm is listed below.
 arbitrarily ( for terminal ),
,
is not terminal (for each step)
according to based on ,
get reward and next state
arbitrarily ( for terminal ),
,
is not terminal (for each step)
according to based on ,
get reward and next state
![$q(s,a)=q(s,a)+\alpha [r+\gamma\max_{a'} q(s',a)'-Q(s,a)]$](img306.svg)
Here is the comparison of the MC and TD methods in terms of their pros and cons:
 ,
the expected return, by the true return obtained
at the end of the episode, i.e., the estimated value is
updated once every episode;
,
the expected return, by the true return obtained
at the end of the episode, i.e., the estimated value is
updated once every episode;
The TD method estimates
as the sum of the
immediate reward and the estimated state value
at the next state , i.e., it is a bootstrap
method, and the estimated value is updated at every step
of every spisode.
is based on sample returns
, and it is unbiased, while TD uses the
bootstrap approach to find the TD target based on sample
data that are not necessarily i.i.d., and it is more
sensitive to the initial guess of the value functions,
it is more biased.
affected by
many random events (state transitions, actions, and
rewards), and in particular the first-visit version of
the MC method only makes use of the sample data from
the first visit of a state, it does not use the available
data efficiently and it has high variance, while on the
other hand the TD method is based on only one random
variable, the estimated return, and it makes more
frequent and efficient use of the sample data, it has
lower variance.
Here is a summary of the dynamic programming (DP) method for model-based planning, and the Monte-Carlo (MC) and time difference (TD) methods for model-free control: