Next: Value Function Approximation Up: Model-Free Evaluation and Control Previous: Temporal Difference (TD) Algorithms
 ) Algorithm
) Algorithm
The MC and TD methods considered previously can be
unified by the n-step TD() method that spans
a spectrum of which the MC and TD methods are two
special cases at the opposite extremes.
Recall that both MC and TD algorithms updates iteratively
the value functions being estimated and the policy being
improved based on Eq. (49), but they
estimate the target  in the equation differently.
In an MC algorithm, the target is the actual return
in the equation differently.
In an MC algorithm, the target is the actual return
 , the
sum of discounted rewards of all future steps upto the
terminal state
, the
sum of discounted rewards of all future steps upto the
terminal state  , available only at the end of each
episode. On the other hand, in a TD algorithm, the target
is
, available only at the end of each
episode. On the other hand, in a TD algorithm, the target
is
 the sum of the
immeidate reward
the sum of the
immeidate reward  available at each step of the
episode, and the discounted value of the next state,
based on bootstrapping. We therefore see that an MC
algorithm updates the value functions and policy once
every episode, while a TD algorithm updates once every
step in the spisode.
available at each step of the
episode, and the discounted value of the next state,
based on bootstrapping. We therefore see that an MC
algorithm updates the value functions and policy once
every episode, while a TD algorithm updates once every
step in the spisode.
As a trade-off between the MC and TD methods, the n-step
TD algorithm can be considered a generalization of the TD
method, where the target in Eq. (49)
is an n-step return, the sum of the discounted
rewards in the  subsequent states and the discounted
value function at the following state
subsequent states and the discounted
value function at the following state  with
with
 :
:
 |
(57) |
 : the 1-step return is the sum of the
immediate reward and the estimated value of the next
state, the same as the TD target in the TD method:
: the 1-step return is the sum of the
immediate reward and the estimated value of the next
state, the same as the TD target in the TD method:
 |
(58) |
 : the n-step return is the sum of the
discounted rewards from all future states upto the
terminal state at the end of the episode, i.e., it
is the return
: the n-step return is the sum of the
discounted rewards from all future states upto the
terminal state at the end of the episode, i.e., it
is the return  defined in Eq. (7),
the same as in the MC method:
defined in Eq. (7),
the same as in the MC method:
 |
(59) |
 is zero.
is zero.
 :
All states
:
All states  beyond the terminal state with
beyond the terminal state with
 remain the same as the terminal state with
value
remain the same as the terminal state with
value  and return , same as in the MC
method.
and return , same as in the MC
method.
Based on these n-step returns of different values,
the n-step TD algorithm can be further generalized to
a more computationally advantageous and therefore more
useful algorithm called TD(), by which the MC
and TD algorithms are again unified as two special cases
at the opposite ends of a spectrum.
We first define the -return
 as
the weighted average of all n-step returns for
as
the weighted average of all n-step returns for
 :
:
 |
(60) |
 . Note that the weights decay
exponentially, and they are normalized due to the
coefficient
. Note that the weights decay
exponentially, and they are normalized due to the
coefficient  :
:
 |
(61) |
-return
defined above can be
expressed in two summations, the sum of the first  n-step returns
n-step returns
 , and the
sum of all subsequent n-step returns
, and the
sum of all subsequent n-step returns
 :
in the second term is the
sum of coefficients in the second summation:
:
in the second term is the
sum of coefficients in the second summation:
 |
(63) |
 . We see that in Eq. (62) all
n-step returns
. We see that in Eq. (62) all
n-step returns  are weighted by exponentially
decaying coefficient
are weighted by exponentially
decaying coefficient
 , except the true
return which is weighted by
, except the true
return which is weighted by
 .
.
Again consider two special cases:
 : all terms in Eq. (62)
are zero, except the first one with :
: all terms in Eq. (62)
are zero, except the first one with :
 |
(64) |
 : the first summation is zero and
: the first summation is zero and
 |
(65) |
) is a general
algorithm of which the two special cases TD(0) and TD(1)
are respectively the TD and MC methods.
In Eq. (62),
is calulated as the
weighted sum of all n-step returns upto
the last one available at the end of the episode.
This summation can be truncated to include fewer terms
before reaching the terminal state at the end of the
episode:
 ,
,
 same as
before, and when
same as
before, and when  ,
,
 , same as
the TD target.
, same as
the TD target.
Based on -return, the iterative update of the
value function
 in Eq. (52) can
be modified to:
in Eq. (52) can
be modified to:
 |
(67) |
 |
(68) |
), which is similar to the MC method, as
they are based on either or
, available
only at the end of each episode.
An alternative method is the backward view of
TD(), which can be shown to be equivalent to
the forward-view of TD(), but it is similar
to the TD(0) method, as they are both based on the
immediate reward available at each time step
of the episode, and therefore more computationally
convenient.
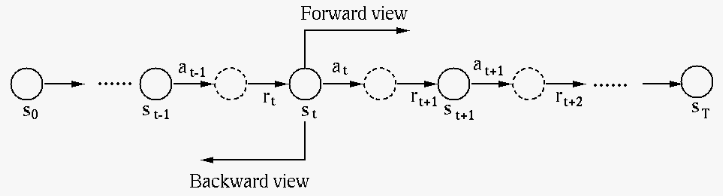
Specifically, the backward view of TD() is
based the eligibility trace  for each
of the states, which decays exponentially upon each
state transition
for each
of the states, which decays exponentially upon each
state transition
 |
(69) |
 to become
to become
 if
if  is currently visited.
is currently visited.
Now the iterative update of the estimated value function
in Eq. (52) is modified so that all
states, instead of only the one currently visited, are
updated, but to different extents based on :
 is the same as in TD(0),
given in Eq. (53):
is the same as in TD(0),
given in Eq. (53):
The eligibility trace as defined above is
motivated by the frequency and recency of the visites
to each state. If a state  has been more frequently
and recently visited compared to others, its
is greater than others and its value function
has been more frequently
and recently visited compared to others, its
is greater than others and its value function  will be updated by a greater increment than others.
will be updated by a greater increment than others.
Here is the pseudo code for the backward view of the
TD() methd for policy evaluation:
 to be evaluated
to be evaluated


 is not terminal (for each step)
is not terminal (for each step)
 based on
based on  ,
get reward
,
get reward  and next state
and next state 





 , different from
the TD algorithm where only the value at the state
currently visited is updated.
, different from
the TD algorithm where only the value at the state
currently visited is updated.
Again consider two special cases:
,  for all states except the
current being visited, i.e., TD()
becomes TD(0), the same as the TD method.
, then is scaled down by a
factor
for all states except the
current being visited, i.e., TD()
becomes TD(0), the same as the TD method.
, then is scaled down by a
factor  for all states except the current
being visited, i.e., TD() becomes TD(1),
the same as the MC method. However, different from
the MC method that updates the value function
for all states except the current
being visited, i.e., TD() becomes TD(1),
the same as the MC method. However, different from
the MC method that updates the value function  at the end of each spisode, here is still
updated at every step of the episode due to the
backward view of the method.
at the end of each spisode, here is still
updated at every step of the episode due to the
backward view of the method.
This backward view of the TD() method can be
applied to model-free control when the state value
function is replaced by the action value function.
Corresponding to the SARSA and Q-learning algorithms
based on TD(0) in the previous section, here are the
two algorithms based on eligibility traces:
) algorithm:
 ,
,
![$\alpha\in(0,\;1]$](img289.svg) ,
,
 ,
denote
,
denote  -greedy policy by
-greedy policy by
 according to based on
according to based on  is not terminal (for each step)
is not terminal (for each step)
 , get reward and next state
, get reward and next state
 according to based on
according to based on 





) algorithem:
,
,
,
denote -greedy policy by
according to based on
is not terminal (for each step)
, get reward and next state
according to based on


 then
else
then
else  ) algorithm is different from the
SARSA() algorithm in two ways. First, the
action value is updated based on the greedy action
) algorithm is different from the
SARSA() algorithm in two ways. First, the
action value is updated based on the greedy action  ,
instead of the by policy ; second, if the
-greedy policy happens to choose a random
non-greedy action
,
instead of the by policy ; second, if the
-greedy policy happens to choose a random
non-greedy action  with probability
to explore rather than exploiting , the eligibility
traces of all states are reset to zero. There are other
different versions of the algorithm which do not reset
these traces.
with probability
to explore rather than exploiting , the eligibility
traces of all states are reset to zero. There are other
different versions of the algorithm which do not reset
these traces.






