Next: Model-Free Evaluation and Control Up: Introduction to Reinforcement Learning Previous: Markov Decision Process
Given a complete MDP model in terms of
 of
the environment, the goal of model-based planning is to
find the optimal policy
of
the environment, the goal of model-based planning is to
find the optimal policy  that achieves the maximum
value:
that achieves the maximum
value:
| If |  |
 |
|
| Then |  |
 |
(26) |
One way to solve this optimization problem is to use
brute-force search to enumerate all  available
policies at each of the
available
policies at each of the  states
states  . If we
assume the numbers of avilable actions in all states are
the same for simplicity, i.e.,
. If we
assume the numbers of avilable actions in all states are
the same for simplicity, i.e.,
 ,
then the computational complexity of this method is
,
then the computational complexity of this method is
 , likely to be too high for such a
brute-force search to be practical if
, likely to be too high for such a
brute-force search to be practical if  is large.
is large.
A more efficient and therefore more practical way to
optimize the policy is to do it iteratively. Consider
a simpler task of improving upon an existing
deterministic policy  at a single transition
step from the current state
at a single transition
step from the current state  to a next state
to a next state  .
Instead of taking the action
.
Instead of taking the action  dictated by
the policy, we can improve it by taking the
greedy action that maximizes the action value
function in Eq. (22), while subsequent
steps still follow the old policy . Now we get a
new policy:
dictated by
the policy, we can improve it by taking the
greedy action that maximizes the action value
function in Eq. (22), while subsequent
steps still follow the old policy . Now we get a
new policy:
While it is obvious that this greedy method will result
in a higher return for the single state transition from
to , we can further prove the following
policy improvement theorem stating that following
this greedy method in all subsequent states, we will get
a new policy  that achieves higher values than the
those of the old one at all states:
that achieves higher values than the
those of the old one at all states:
 |
(29) |
The proof is by recursively applying the greedy method to
replace the old policy  by the new one
by the new one  for a higher value for each of the subsequent steps one at
a time:
for a higher value for each of the subsequent steps one at
a time:
 .
.
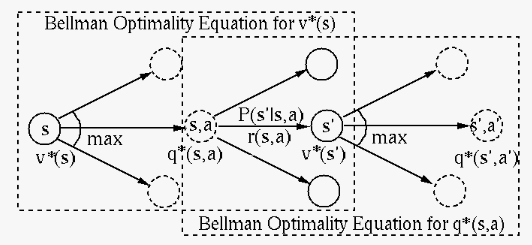
The optimal state value  and action value
and action value
 can therefore be achieved by replacing the
weighted average over all possible actions at each
state ( and ) in the Bellman equations in
Eqs. (21) and
(22) by their maximum:
can therefore be achieved by replacing the
weighted average over all possible actions at each
state ( and ) in the Bellman equations in
Eqs. (21) and
(22) by their maximum:
states in
 and can
be written in vector form:
and can
be written in vector form:
 |
(33) |
![$\displaystyle {\bf v}^*=\left[\begin{array}
{c}v^*(s_1)\\ \vdots\\ v^*(s_N)\end...
...s & \vdots \\
P(s_1\vert s_N,a) & \cdots & P(s_N\vert s_N,a)\end{array}\right]$](img162.svg) |
(34) |
 :
This iteration is to be used for policy evaluation in
the algorithm value iteration below for finding
the optimal policy. This iteration will converge as
function
:
This iteration is to be used for policy evaluation in
the algorithm value iteration below for finding
the optimal policy. This iteration will converge as
function
 is a
contraction mapping
with
is a
contraction mapping
with  :
:
 |
 |
 |
|
 |
 |
||
|
 |
||
|
 |
(36) |
 is the p-norm
(
is the p-norm
( ) of a stochastic matrix, which is known to be 1.
) of a stochastic matrix, which is known to be 1.
Given the complete information of the MDP model in
terms of
, we can find the optimal policy
using either policy iteration (PI) or
value iteration (VI) based on the DP method.
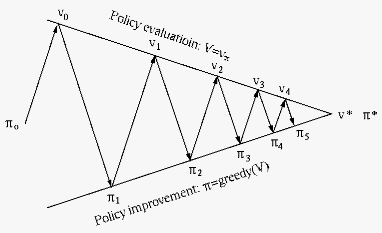
Carry out the following two processes iteratively from
some arbibrary initial policy until convergence
when no longer changes:
Given a deterministic policy ,
Eq. (21) becomes the Bellman
equation in Eq. (24), a linear
equation system of equations of unknowns
 , which can be solved
iteratively as in Eq. (12) to find
values at all states:
, which can be solved
iteratively as in Eq. (12) to find
values at all states:

Given  based on policy , get a
better policy by the greedy method as in
Eq. (27):
based on policy , get a
better policy by the greedy method as in
Eq. (27):
![$\pi'(s)=\argmax_a\left[ r(s,a)
+\gamma\sum_{s'}P(s'\vert s,\pi(s)) v_\pi(s')\right]
\;\;\;\;\;\;\;\;\forall s\in S$](img172.svg)
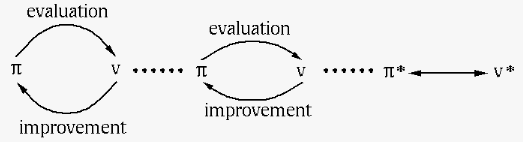
We see that in each round of the policy iteration,
two intertwined and interacting processes, the policy
evaluation and policy improvement, are carried out
alternatively, one depending on the other, and one
completing before the other starts. The value functions
at all states are sysmeticaly evaluated
before they are updated, and the policy  at all states is updated before it is evaluated. While
these two processes chase each other as moving target
iteratively and eventually converge to the optimal
policy achieving the optimal value
at all states is updated before it is evaluated. While
these two processes chase each other as moving target
iteratively and eventually converge to the optimal
policy achieving the optimal value  . This
approach is said to be synchronous, as shown here:
. This
approach is said to be synchronous, as shown here:
The pseudo code for the algorithm is listed below:


 ;
;
 (small positive value);
(small positive value);
 ):
):

 :
:




![$\pi'(s)=\argmax_a\left[r(s,a)+\gamma\sum_{s'} P(s'\vert s,\pi(s)) v(s')\right]$](img186.svg)


One drawback of the policy iteration method is the high computational complexity of the inner iteration for policy evaluation inside the outer iteration for policy evaluation. To speed up this process, we could terminate the inner iteration early before convergence. In the extreme case, we simply combine policy evaluation and improvement into a single step, resulting in the following value iteration contains two steps:
Based on some initial value  , solve the Bellman
optimality equation in Eq. (31)
by iteration in Eq. (35):
, solve the Bellman
optimality equation in Eq. (31)
by iteration in Eq. (35):
![$\displaystyle v_{n+1}(s)=\max_a\left[r(s,a)+\gamma\sum_{s'}
P(s'\vert s,a)v_n(s')\right]
\;\;\;\;\;\;\forall s\in S$](img190.svg) |
(38) |
Find  that maximizes :
that maximizes :
![$\displaystyle \pi^*(s)=\argmax_a\left[r(s,a)+\gamma
\sum_{s'}P(s'\vert s,a)v_n(s')\right]
\;\;\;\;\;\;\forall s\in S$](img192.svg) |
(39) |
Here is the pseudo code for the algorithm:
 ;
;
![$v'(s)=\max_a\left[r(s,a)+\gamma\sum_{s'}P(s'\vert s,a)v(s')\right]$](img194.svg)


![$\pi^*(s)=\argmax_a\left[r(s,a)+\gamma\sum_{s'}P(s'\vert s,a)v(s')\right]$](img197.svg)
In the PI method considered above, the value functions at all states are evaluated before the policy is updated for all states, as illustrated below:
This synchronous policy iteration can be modified so that the values at some or even one of the states are evaluated in-place before other state values are updated, and the policy at some or even one of the states are updated in-place before that at other states, resulting in an asynchronous method called general policy iteration (GPI), to be discussed in detail in the next sections on model-free control.

![$\displaystyle \pi'(s)=\argmax_a q_\pi(s,a)
=\argmax_a \left[ r(s,a)+\gamma \sum_{s'} P(s'\vert s,a)
v_\pi(s')\right]$](img142.svg)
![$\displaystyle q_\pi(s,\pi'(s))=\max_a q_\pi(s,a)
=\max_a \left[ r(s,a)+\gamma \sum_{s'} P(s'\vert s,a)
v_\pi(s')\right]
\ge
q_\pi(s,\pi(s))=v_\pi(s)$](img143.svg)

![$\displaystyle q_\pi(s,\pi'(s)) =\max_a q_\pi(s,a)
=\max_a\left[ r(s,a)+\gamma \sum_{s'} P(s'\vert s,a) v_\pi(s')\right]$](img148.svg)


![$\displaystyle r(s,\pi'(s))+\gamma \sum_{s'} P(s'\vert s,\pi'(s))
\left[ r(s',\pi'(s))+\gamma \sum_{s''} P(s''\vert s',\pi'(s')) v_\pi(s'')\right]$](img151.svg)
![$\displaystyle r(s,\pi'(s))+\gamma r(s',\pi'(s))+
\gamma \sum_{s'} P(s'\vert s,\pi'(s))
\left[ \gamma \sum_{s''} P(s''\vert s',\pi'(s')) v_\pi(s'')\right]$](img152.svg)