Next: Model-Based Planning Up: Introduction to Reinforcement Learning Previous: Reinforcement Learning
Markov decision process (MDP) is the mathematical
framework for reinforcement learning. To understand MDP,
we first consider the basice concept of Markov process
or Markov chain, a stochastic model of a system that
can be characterized by a set of states
 of size
of size  (cardinality of
(cardinality of  ). The dynamics of the
system in terms of its state transition is modeled by the
transition probability
). The dynamics of the
system in terms of its state transition is modeled by the
transition probability
 from the current
state
from the current
state  to the next state
to the next state
 with
with
 . The system is assumed to be memoryless,
i.e., its future is independent of the past history
. The system is assumed to be memoryless,
i.e., its future is independent of the past history
 , given the present
, given the present  :
:
 |
(1) |
For example, if the state of a helicopter is described by its linear and angular position and velocity based on which its future position and velocity can be completely determined, then it can be modeled by a Markov process; but if the state is only described by its position, then its position in the past is needed for determining its future (e.g., to find its velocity), and it is not a Markov process.
All transition probabilities can be organized as an  state transition matrix:
state transition matrix:
![$\displaystyle {\bf P}=\left[\begin{array}{ccc}
P_{11} & \cdots & P_{1N}\\
\vdots & \ddots & \vdots \\
P_{N1} & \cdots & P_{NN}\end{array}\right]$](img24.svg) |
(2) |
 to the
to the  possible next states
possible next states
 have
to sum up to 1, we have
Any matrix satisfying this property is called a
stochastic matrix.
have
to sum up to 1, we have
Any matrix satisfying this property is called a
stochastic matrix.
In the following, our discussion is mostly concentrated on
the the general transition from the current state  to
the next state
to
the next state
 with transition probability
with transition probability
 .
.
Example Weather in Los Angeles:
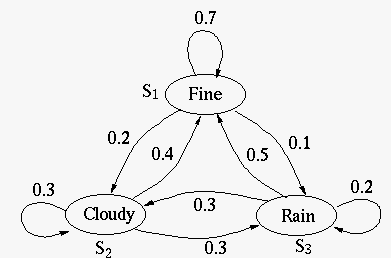
![$\displaystyle {\bf P}=\left[\begin{array}{ccc}
0.7 & 0.2 & 0.1 \\
0.4 & 0.3 & 0.3 \\
0.5 & 0.2 & 0.3 \end{array}\right]$](img30.svg) |
(4) |
We next consider a Markov reward process (MRP),
represented by a tuple
 of
four elements for the states, state transition probabilities,
rewards, and the discount factor. Here the reward
of
four elements for the states, state transition probabilities,
rewards, and the discount factor. Here the reward
 can be considered as a feedback signal to the agent at
each time step of the sequence of state transitions, indicating
how well it is doing with respect to the overall task. The
reward can be negative, as a penalty, for situations to be
avoided. The performance of the agent is measured by the
sum of rewards accumulated over all time steps of the
Markov process, weighted by the discount factor
can be considered as a feedback signal to the agent at
each time step of the sequence of state transitions, indicating
how well it is doing with respect to the overall task. The
reward can be negative, as a penalty, for situations to be
avoided. The performance of the agent is measured by the
sum of rewards accumulated over all time steps of the
Markov process, weighted by the discount factor
![$\gamma \in[0,\;1]$](img33.svg) that discounts future rewards. If
that discounts future rewards. If
 is close to 0, then the immediate reward is
emphasized (short-sighted or greedy), but if is
close to 1, then rewards in the future steps will be almost
as valuable as immediate ones (far-sighted).
is close to 0, then the immediate reward is
emphasized (short-sighted or greedy), but if is
close to 1, then rewards in the future steps will be almost
as valuable as immediate ones (far-sighted).
The sequence of state transitions of an MRP from an
initial state  to a terminal state
to a terminal state  is called an
episode, and the number of time steps
is called an
episode, and the number of time steps  is called
horizon, which can be either finite or infinite.
is called
horizon, which can be either finite or infinite.
Both the reward  and the next state
and the next state  resulting
from arriving at the current state
resulting
from arriving at the current state  are considered
as random variables with joint probability
are considered
as random variables with joint probability
 , based on which
both the state transition probability and state reward
probability can be found by marginalization:
, based on which
both the state transition probability and state reward
probability can be found by marginalization:
 |
(5) |
received after
arriving at state is denoted by  , instead
of
, instead
of  . The index
. The index  for the summation over all
states will be abbreviated to in the subsequent
discussion. The expectation of the reward at is
for the summation over all
states will be abbreviated to in the subsequent
discussion. The expectation of the reward at is
We define the return  at each step
at each step  as
the accumlate reward, the sum of the immediate reward
after arriving at the current state and all
delayed rewards in the future states upto a terminal
state with reward
as
the accumlate reward, the sum of the immediate reward
after arriving at the current state and all
delayed rewards in the future states upto a terminal
state with reward  at the end of the episode,
discounted by :
at the end of the episode,
discounted by :
 at state as the expectation of the return, which
can be further expressed recursively in terms of the values
at state as the expectation of the return, which
can be further expressed recursively in terms of the values
 of all possible next states
of all possible next states
 :
:
 is given in Eq. (6). The value of a
terminal state at the end of an episode is zero, as
there will be no next state and thereby no more future
reward.
is given in Eq. (6). The value of a
terminal state at the end of an episode is zero, as
there will be no next state and thereby no more future
reward.
This equation is called the Bellman equation, by
which the value at current state is expressed
recursively in terms of the immediate reward and
the values of all possible next states, without
explicitely invoking all future rewards. Based on this
bootstrap idea of the Bellman equation, a multi-step
MRP problem can be expressed recursively as a subproblem
concerning only a single state transition from to ,
as a backward induction to find current state value from
all future ones. For this reason, the Bellman equation
plays an essential role in future discussion of some
important algorithms in reinforcement learning.
The Bellman equation in Eq. (8) holds
for all states
, and the resulting
equations can be expressed in vector form as:
 is called the stochastic matrix.
Solving this linear equation system of size we find
Such a solution exists as matrix
is called the stochastic matrix.
Solving this linear equation system of size we find
Such a solution exists as matrix
 is invertible. This can be shown by noting that all
eigenvalues of the stochastic matrix are not
greater than 1:
is invertible. This can be shown by noting that all
eigenvalues of the stochastic matrix are not
greater than 1:
 (see
here), and
all eigenvalues of
(see
here), and
all eigenvalues of
 are smaller than 1:
are smaller than 1:
 , i.e., the eigenvalue of
is greater than zero:
, i.e., the eigenvalue of
is greater than zero:
 .
Consequently the determinant
.
Consequently the determinant
 of this coefficient matrix, as the product of all its
nonzero eigenvalues, is non-zero and therefore matrix
is invertible.
of this coefficient matrix, as the product of all its
nonzero eigenvalues, is non-zero and therefore matrix
is invertible.
Alternatively, the Bellman equation in Eq. (8) can also be solved iteratively by the general method of dynamic programming (DP), which solves a multi-stage planning problem by a backward induction and find the value function recursively. We first rewrite the Bellman equation as
 |
(11) |
 is defined
as a vector-valued function (an operator) applied to
the vector argument
is defined
as a vector-valued function (an operator) applied to
the vector argument  . Now the Bellman equation
can be solved iteratively from an arbitrary initial value,
such as
. Now the Bellman equation
can be solved iteratively from an arbitrary initial value,
such as
 :
This iteration will always converge to the root of the
equation, the fixed point of function
:
This iteration will always converge to the root of the
equation, the fixed point of function
 ,
as it is a
contraction mapping
satisfying
,
as it is a
contraction mapping
satisfying
 |
 |
 |
|
 |
 |
(13) |
is a contraction can also be proven by
showing the norm of its Jacobian matrix, its derivative
with respect to its vector argument , is smaller
than 1. We first find the Jacobian matrix
 |
(14) |
 (equivalent to
(equivalent to  ), the maximum absolute
row sum:
), the maximum absolute
row sum:
 |
(15) |
 .
.
In summary, the Bellman equation in Eq. (8)
can be solved by either of the two methods in
Eqs. (10) and (12),
so long as  . When the size of state space
is large, the complexity
. When the size of state space
is large, the complexity  is too high then the
iterative method may be more efficient.
is too high then the
iterative method may be more efficient.
Based on the definition of MRP, we further define
Markov decision process (MDP) as an MRP with
certain decision-making rule called policy,
denoted by  , following the policy the agent
takes one of the actions
, following the policy the agent
takes one of the actions  available at
each state to control the state transition of the
process. An MDP can therefore be described by a tuple
available at
each state to control the state transition of the
process. An MDP can therefore be described by a tuple
 , of which
, of which  is the set of all
actions. The policy can be either stochastic
denoted by
is the set of all
actions. The policy can be either stochastic
denoted by
 as the conditional
probability of taking action
as the conditional
probability of taking action  in state , or
deterministic denoted by
in state , or
deterministic denoted by  . A policy is
soft if any of the actions available at a state
is possible to be taken, i.e.,
. A policy is
soft if any of the actions available at a state
is possible to be taken, i.e.,
 for all
and all
for all
and all  . In particular, a policy
is
. In particular, a policy
is  -soft if
-soft if
 for some small value of .
for some small value of .
As there are  possible actions to take in
state
possible actions to take in
state  , the total number of policies is
, the total number of policies is
 . If the
number of available actions
. If the
number of available actions  is the same for all
is the same for all
 states, then the total number of policies is
states, then the total number of policies is
 .
.
Following a given policy from an initial state
will result a sequence of state transitions called a
trajectory of the episode:
 |
(16) |
can be any of the states in
of the MDP, not to be confused
with the t-th state in . Note that in an episode
some of the states in may be visited multiple
times, while some others may never be visited. Also
note that due to the random nature of the MDP, following
the same policy may not result in the same trajectory.
Along the trajectory of an episode, an accumulation
of discounted rewards from all states visited will
be received. Our goal is to find the optimal policy
as a sequence of actions
 for
a given MDP model of the environment in terms of its
state transition dynamics and rewards, so that the
value
for
a given MDP model of the environment in terms of its
state transition dynamics and rewards, so that the
value  at the start state , the expectation
of the sum of all discounted future rewards, is maximized.
This optimization problem can be solved by the method
of dynamic programming, and such a process is called
planning.
at the start state , the expectation
of the sum of all discounted future rewards, is maximized.
This optimization problem can be solved by the method
of dynamic programming, and such a process is called
planning.
In an MDP, both the next state and reward are
assumed to be random variables with joint probability
 conditioned on the action and the previous state
. The state transition probability becomes
conditioned on the action and the previous state
. The state transition probability becomes
received after arriving at the
current is
Following a specific random policy  , the agent
takes an action to transit from the current
state to the next state
with probability
, the agent
takes an action to transit from the current
state to the next state
with probability
 |
(19) |
 and the reward in
state :
and the reward in
state :
![$\displaystyle r_\pi(s)=E_\pi[ r_{t+1}\vert s_t=s]=\sum_{a\in A(s)}\pi(a\vert s)\;r(s,a)$](img111.svg) |
(20) |
 denotes the expectation with respect to a
certain policy . The summation over all available
actions in state will be abbreviated to
in the following.
denotes the expectation with respect to a
certain policy . The summation over all available
actions in state will be abbreviated to
in the following.
We further define two important functions with respect
to a given policy of an MDP:
 is the
expected return at each state of the MDP while
following policy , similar to the value function
of an MRP as in Eq. (8), but now
treated as a function of action as well as state :
is the
expected return at each state of the MDP while
following policy , similar to the value function
of an MRP as in Eq. (8), but now
treated as a function of action as well as state :
 is defined below.
is the expected return of taking a specific action
(irrelevant to policy ) in state , and then
following in all subsequent states:
is defined below.
is the expected return of taking a specific action
(irrelevant to policy ) in state , and then
following in all subsequent states:
 is recursively represented as a
weighted sum of
is recursively represented as a
weighted sum of
 based on
Eq. (21).
based on
Eq. (21).
The state-action value
plays a more important
role than as it allows the freedom of taking
any action independent of a given policy , thereby
allowing the opportunity to improve an existing policy,
e.g., by taking a greedy action to maximize the
value
. The state-action value function
is often abbreviated as the action value
ore Q-value for convenience in future discussions.
As a function of the state-action pair  , the state
action value
can be represented as a table
of rows each for one of the states , and
columns each for one of the actions . The Q-value for
each state-action pair stored in the table can be updated
iteratively by various algorithms for learning the Q-values.
, the state
action value
can be represented as a table
of rows each for one of the states , and
columns each for one of the actions . The Q-value for
each state-action pair stored in the table can be updated
iteratively by various algorithms for learning the Q-values.
In particular, if the policy is deterministic with
 and , then we have
and , then we have
 |
(23) |
, same as in Eq. (12).
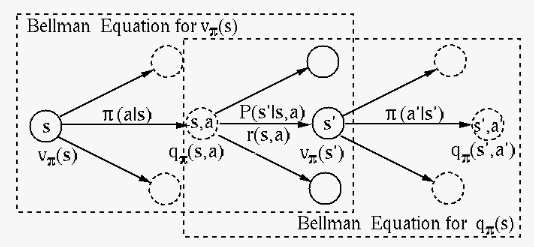
The figure above illustrates the Bellman equations in
Eqs. (21) and (22),
showing the bootstrapping of the state value function
in the dashed box on the left, and that of the action
value function in dashed box on the right. Specifically
here the word bootstrapping means the iterative method
that updates the estimated value at a state based
on the estimated value of the next state . After
taking oen of the actions available in state
based on policy , an immediate reward
 is received. However, which state the MDP will
transit into as the next state is random depending
on
is received. However, which state the MDP will
transit into as the next state is random depending
on  of the environment but independent of the
policy. This uncertanty is represented graphically by a
dashed circle called a chance node associated with
the action value
as the sum of the immediate
reward and the expected value of the next state,
the weighted average of values of all possible
state .
of the environment but independent of the
policy. This uncertanty is represented graphically by a
dashed circle called a chance node associated with
the action value
as the sum of the immediate
reward and the expected value of the next state,
the weighted average of values of all possible
state .

![$\displaystyle r(s)=E[ r_{r+1}\vert s_t=s]=\sum_r r P(r\vert s)
=\sum_r r \sum_{s'} P(s',r\vert s)$](img43.svg)


![$\displaystyle E[ \;G_t\vert s_t=s \;]
=E [r_{t+1}+\gamma r_{t+2}+\gamma^2 r_{t+3} +\cdots \vert s_t=s]$](img53.svg)
![$\displaystyle E [r_{t+1}+\gamma (r_{t+2}+\gamma r_{t+3} +\cdots) \vert s_t=s]$](img54.svg)
![$\displaystyle E[r_{t+1}\vert s=s_t]+\gamma E[ G_{t+1} \vert s_{t+1}=s',\,s_t=s]$](img55.svg)


![$\displaystyle \left[\begin{array}{c}v(s_1)\\ \vdots\\ v(s_N)\end{array}\right]
...
...rray}\right]
\left[\begin{array}{c} v(s_1)\\ \vdots\\ v(s_N)\end{array} \right]$](img59.svg)




![$\displaystyle r(s,a)=E[ r_{t+1} \vert s_t=s, a_t=a ]
=\sum_r r\; p(r\vert s,a)=\sum_r r \sum_{s'} p(s',r\vert s,a)$](img108.svg)

![$\displaystyle E_\pi [ G_t \vert s_t=s]$](img115.svg)



![$\displaystyle E_\pi\left[ G_t\vert s_t=s, a_t=a \right]$](img120.svg)


