Next: Quasi-Newton Methods Up: Unconstrained Optimization Previous: Gradient Descent Method
In general, in an algorithm for minimizing an objective function
 , such as Newton's method (Eq. (36))
and the gradient descent method (Eq. (50)),
the variable
, such as Newton's method (Eq. (36))
and the gradient descent method (Eq. (50)),
the variable  is iteratively updated to gradualy reduce
the value of
. Specifically, both the search direction
is iteratively updated to gradualy reduce
the value of
. Specifically, both the search direction
 and the step size
and the step size  in the iteration
in the iteration
 need to be determined
so that
need to be determined
so that
 is maximally reduced.
is maximally reduced.
First we realize that the search direction needs to
point away from the gradient  along which
along which
 increases most rapidly. In other words, the angle
increases most rapidly. In other words, the angle  between
and should be greater than
between
and should be greater than  :
:
 |
(51) |
 and Newton's method with
and Newton's method with
 :
:
 |
(52) |
 is assumed to be positive definite so that a
minimum exists.
is assumed to be positive definite so that a
minimum exists.
Next, we need to find the optimal step size  so that the
function value
so that the
function value
 is
minimized along the search direction . To do so, we set
to zero the derivative of the function with respect to ,
the
directional derivative
along the direction of , and get the following by chain
rule:
is
minimized along the search direction . To do so, we set
to zero the derivative of the function with respect to ,
the
directional derivative
along the direction of , and get the following by chain
rule:
 at the next point
at the next point
 should be perpendicular to the search direction . In
other words, when traversing along , we should stop at
the point
should be perpendicular to the search direction . In
other words, when traversing along , we should stop at
the point
 at which the
gradient
at which the
gradient
 is perpendicular to , i.e.,
it has zero component along , and the corresponding
is the optimal step size.
is perpendicular to , i.e.,
it has zero component along , and the corresponding
is the optimal step size.
To find the actual optimal step size , we need
to solve a 1-D optimization problem while treating
 as a function
of the step size as a variable, and approximate it
by the first three terms of its Taylor series at
as a function
of the step size as a variable, and approximate it
by the first three terms of its Taylor series at  (Maclaurin series of function
(Maclaurin series of function  ):
):
![$\displaystyle \left[f({\bf x}_n+\delta{\bf d}_n)\right]_{\delta=0}$](img314.svg) |
 |
 |
(55) |
![$\displaystyle \left[\frac{d}{d\delta}f({\bf x}_n+\delta{\bf d}_n)\right]_{\delta=0}$](img316.svg) |
|
![$\displaystyle \left[{\bf g}({\bf x}_n+\delta{\bf d}_n)^T{\bf d}_n\right]_{\delta=0}
={\bf g}^T_n{\bf d}_n$](img317.svg) |
(56) |
![$\displaystyle \left[\frac{d^2}{d\delta^2}f({\bf x}_n+\delta{\bf d}_n)\right]_{\delta=0}$](img318.svg) |
|
![$\displaystyle \left[\frac{d}{d\delta}{\bf g}({\bf x}_n
+\delta{\bf d}_n)^T\righ...
...})\;
\frac{d}{d\delta}({\bf x}_n+\delta{\bf d}_n)\right]^T_{\delta=0}
{\bf d}_n$](img319.svg) |
|
|
 |
(57) |
 is the Hessian matrix of
at
is the Hessian matrix of
at  . Substituting these back into the Taylor series above
we get:
. Substituting these back into the Taylor series above
we get:
 |
(58) |
that minimizes
 , we
set its derivative with respect to to zero:
to get the optimal
step size based on both and :
, we
set its derivative with respect to to zero:
to get the optimal
step size based on both and :
Based on this result, we can find the optimal step side for the Newton's method and gradient descent method considered previously:
The search direction is
, and the
optimal step size is
 |
(61) |
 |
(62) |
The search direction is
, and
Eq. (53) becomes:
 i.e., i.e., |
(63) |
 is always
perpendicular to the previous one
, i.e., the
iteration follows a zigzag path composed of a sequence of segments
from the initial guess to the final solution. The optimal step size
is
is always
perpendicular to the previous one
, i.e., the
iteration follows a zigzag path composed of a sequence of segments
from the initial guess to the final solution. The optimal step size
is
Given as well as , we can find the optimal
step size with complexity  for each iteration.
However, if the Hessian is not available, such as in
the gradient descent method, the optimal step size above cannot be
computed. We can instead approximate
for each iteration.
However, if the Hessian is not available, such as in
the gradient descent method, the optimal step size above cannot be
computed. We can instead approximate
 in
the third term of Eq. (54) at two nearby points
at and
in
the third term of Eq. (54) at two nearby points
at and
 , where
, where  is a small value:
is a small value:
![$\displaystyle \left[\frac{d^2}{d\delta^2} f({\bf x}+\delta{\bf d})\right]_{\delta=0}$](img338.svg) |
|
![$\displaystyle \left[\frac{d}{d\delta} f'({\bf x}+\delta{\bf d})\right]_{\delta=...
...\lim_{\sigma\rightarrow 0}
\frac{f'({\bf x}+\sigma{\bf d})-f'({\bf x})}{\sigma}$](img339.svg) |
|
 |
 |
(65) |
 and
and
 .
This approximation can be used to replace
.
This approximation can be used to replace
 in Eq. (59) abve:
in Eq. (59) abve:
 |
(66) |
we get the estimated optimal step size:
 |
(67) |
,
this optimal step size becomes:
and the iteration becomes
 |
(69) |
Example:
The gradient descent method applied to solve the same three-variable equation system previously solved by Newton's method:
 |
The step size is determined by the secant method with
 . The iteration from an initial guess
. The iteration from an initial guess
 is shown below:
is shown below:
 |
 , and
With 500 additional iterations the algorithm converges to the
following approximated solution with accuracy of
, and
With 500 additional iterations the algorithm converges to the
following approximated solution with accuracy of
 :
:
![$\displaystyle {\bf x}^*=\left[\begin{array}{r}
0.5000013623816102\\
0.0040027495837189\\
-0.4999000311539049\end{array}\right]$](img352.svg) |
(70) |
When it is difficult or too computationally costly to find the
optimal step size along the search direction, some suboptimal
step size may be acceptable, such as in the
quasi-Newton methods
for minimization problems. In this case, although the step size
is no longer required to be such that the function value
at the new position
is minimized along the search direction , the step size
still has to satisfy the following
Wolfe conditions:
 |
(71) |
 |
(72) |
 , this condition can also be written
in the following alternative form:
, this condition can also be written
in the following alternative form:
 |
(73) |
 and
and  above satisfy
above satisfy
 .
.
In general, these conditions are motivated by the desired effect
that after each iterative step, the function should have a shallower
slope along , as well as a lower value, so that eventually
the solution can be approached where
is minimum and
the gradient is zero.
Specifically, to understand the first condition above, we represent
the function to be minimized as a single-variable function of the
step size
 , and its
tangent line at the point as a linear function
, and its
tangent line at the point as a linear function
 , where the intercept
, where the intercept  can be found
as
can be found
as
 , and the
slope
, and the
slope  can be found as the derivative of
at :
can be found as the derivative of
at :
 |
(74) |
 . Now the
function of the tangent line can be written as
. Now the
function of the tangent line can be written as
 |
(75) |
 of
slope zero, we see that any straight line between
of
slope zero, we see that any straight line between
 and
and
 can be described by
can be described by
 with
with
 , with a slope
, with a slope
 .
The Armijo rule is to find any
.
The Armijo rule is to find any  that satisfies
that satisfies
 |
(76) |
is guaranteed to be reduced.
The second condition requires that at the new position
the slope of the gradient
along
the search direction be sufficiently reduced to be
less than a specified value (determined by ), in comparison
to the slope at the old position .
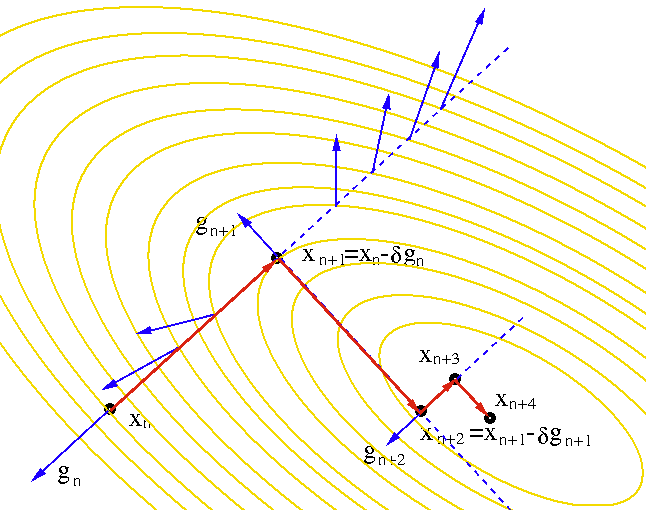
The reason why
 can also be explained geometrically.
As shown in the figure the gradient vectors at various points along the direction
of
can also be explained geometrically.
As shown in the figure the gradient vectors at various points along the direction
of
 are shown by the blue arrows, and their projections onto the direction
represent the slopes of the function
are shown by the blue arrows, and their projections onto the direction
represent the slopes of the function
 .
Obviously at
where
.
Obviously at
where
 reaches its minimum, its slope
is zero. In other words, the projection of the gradient
onto the
direction of
is zero, i.e.,
or
reaches its minimum, its slope
is zero. In other words, the projection of the gradient
onto the
direction of
is zero, i.e.,
or
 .
.
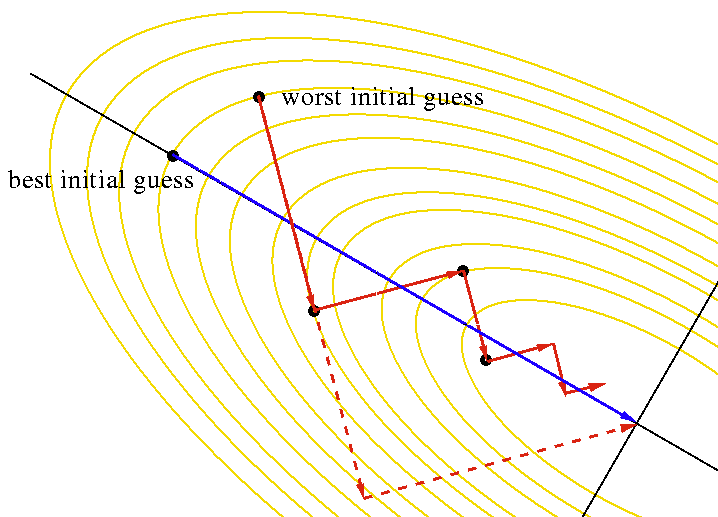
The gradient descent method gradually approaches a solution of an N-D
minimization problem by moving from the initial guess  along a zigzag
path composed of a set of segments with any two consecutive segments
perpendicular to each other. The number of steps depends greatly on the initial
guess. As illustrated in the example below in an N=2 dimensional case, the best
possible case is that the solution happens to be on the gradient direction of the
initial guess, which could be reached in a single step, while the worst possible
case is that the gradient direction of the initial guess happens to be 45 degrees
off from the gradient direction of the optimal case, and it takes many zigzag
steps to go around the optimal path to reach the solution. Many of the steps
are in the same direction as some of the previous steps.
along a zigzag
path composed of a set of segments with any two consecutive segments
perpendicular to each other. The number of steps depends greatly on the initial
guess. As illustrated in the example below in an N=2 dimensional case, the best
possible case is that the solution happens to be on the gradient direction of the
initial guess, which could be reached in a single step, while the worst possible
case is that the gradient direction of the initial guess happens to be 45 degrees
off from the gradient direction of the optimal case, and it takes many zigzag
steps to go around the optimal path to reach the solution. Many of the steps
are in the same direction as some of the previous steps.
To improve the performance of the gradient descent method we can include in the iteration a momentum term representing the search direction previously traversed:
 |
(77) |
 controls how much momentum is to
be added.
controls how much momentum is to
be added.
Obviously it is most desirable not to repeat any of the previous directions traveled so that the solution can be reached in N steps, each in a unique direction in the N-D space. In other words, the subsequent steps are independent of each other, never interfering with the results achieved in the previous steps. Such a method will be discussed in the next section.
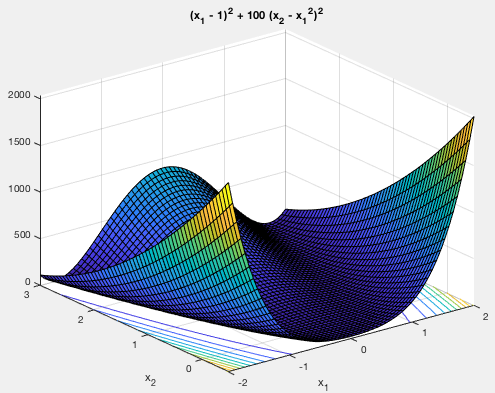
Example:
The Rosenbrock function
  |
 at the point
at the point  , which is inside a long parabolic
shaped valley as shown in the figure below. As the slope along the
valley is very shallow, it is difficult for an algorithm to converge
quickly to the minimum. For this reason, the Rosenbrock function is
often used to test various minimization algorithms.
, which is inside a long parabolic
shaped valley as shown in the figure below. As the slope along the
valley is very shallow, it is difficult for an algorithm to converge
quickly to the minimum. For this reason, the Rosenbrock function is
often used to test various minimization algorithms.
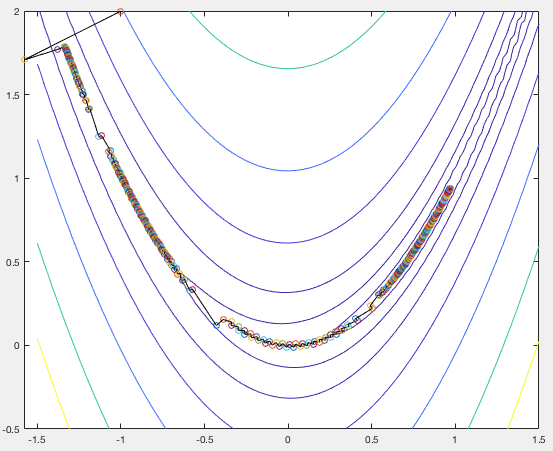
The figure below shows the search path of the gradient descent method based on the optimal step size given in Eq. (64). We see that the search path is composed a long sequence of 90 degree turns between consecutive segments.
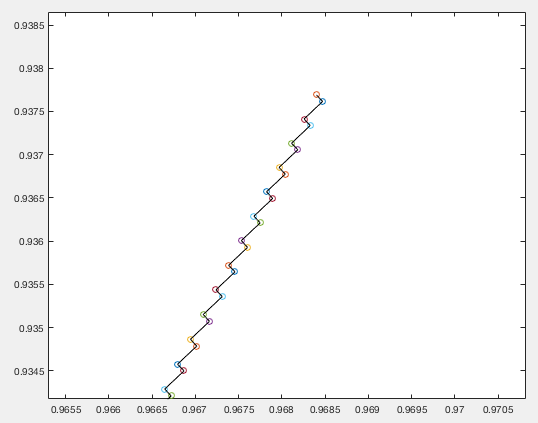
When the Newton's method is applied to this minimization problem, it takes only four iterations for the algorithm to converge to the minimum, as shown in the figure below:

![$\displaystyle f({\bf x}_{n+1})=f({\bf x}_n+\delta{\bf d}_n)\approx
\left[f({\bf...
...}{2}\;\left[\frac{d^2}{d\delta^2}f({\bf x}_n+\delta{\bf d}_n)\right]_{\delta=0}$](img313.svg)





