Next: Line minimization Up: Unconstrained Optimization Previous: Newton's method
Newton's method discussed above is based on the Hessian
 and gradient
and gradient
 of the function
of the function
 to be minimized. However, the method is not applicable if
the Hessian
to be minimized. However, the method is not applicable if
the Hessian  is not available, or the cost of computing the
inverse
is not available, or the cost of computing the
inverse
 is too high. In such a case, the gradient
descent method can be used without using the Hessian matrix.
is too high. In such a case, the gradient
descent method can be used without using the Hessian matrix.
We first consider the minimization of a single-variable function
 . From any inital point
. From any inital point  , we can move to a nearby point
, we can move to a nearby point
 along the opposite direction of the gradient, so that the
function value will be smaller than that at the current position
:
along the opposite direction of the gradient, so that the
function value will be smaller than that at the current position
:
 where where |
(46) |
 is positive or negative,
the function value
is positive or negative,
the function value  (approximated by the first two terms
of its Taylor series) is always reduced if the positive step size
(approximated by the first two terms
of its Taylor series) is always reduced if the positive step size
 is small enough:
is small enough:
 |
(47) |
 |
(48) |
 at which
at which  and no
further progress can be made, i.e. a local minimum of the function is
obtained.
and no
further progress can be made, i.e. a local minimum of the function is
obtained.
This simple method can be generalized to minimize a multi-variable
objective function
 in N-D space. The
derivative of the 1-D case is generalized to the gradient vector
in N-D space. The
derivative of the 1-D case is generalized to the gradient vector
 of function
,
which is in the direction along which the function increases most rapidly
with the steepest slope, perpendicular to the contour or iso-lines of the
function
. The fastest way to reduce
is to go
down hill along the opposite direction of the gradient vector.
of function
,
which is in the direction along which the function increases most rapidly
with the steepest slope, perpendicular to the contour or iso-lines of the
function
. The fastest way to reduce
is to go
down hill along the opposite direction of the gradient vector.
Specifically the gradient descent method (also called steepest
descent or down hill method) carries out the following approximation
 (the first two terms of the
Taylor series) with
(the first two terms of the
Taylor series) with
 :
:
 |
(49) |
 and the
minimum of the function
is reached.
and the
minimum of the function
is reached.
Comparing the gradient descent method with Newton's method we see that
here the Hessian matrix is no longer needed. The iteration simply follows
a search direction
 , which is different from the
search direction of Newton's method,
, which is different from the
search direction of Newton's method,
 ,
based on
,
based on  as well as
as well as  . Specially, when
. Specially, when
 ,
the two methods become the same.
,
the two methods become the same.
As the gradient descent method relies only on the gradient vector of the objective function without any information contained in the second order derivatives in the Hessian matrix, it does not have as much information as Newton's method and therefore may not be as efficient. For example, when the function is quadratic, as discussed before, Newton's method can find the solution in a single step from any initial guess, but it may take the gradient descent method many steps to reach the solution, because it always follows the negative direction of the local gradient, which typically does not lead to the solution directly. However, for the same reason, the gradient descent method is computationally less expensive as the Hessian matrix is not used.
Example:
Consider a two-variable quadratic function in the following general form:
![$\displaystyle f({\bf x})={\bf x}^T{\bf Ax}+{\bf b}^T{\bf x}+c
=[x_1\;x_2]\left[...
...nd{array}\right]
+[b_1\;b_2]\left[\begin{array}{c}x_1\\ x_2\end{array}\right]+c$](img278.svg) |
 is a symmetric positive semidefinite matrix,
i.e.,
is a symmetric positive semidefinite matrix,
i.e.,
 and
and
 . Specially, if we let
. Specially, if we let
![$\displaystyle {\bf A}=\left[\begin{array}{cc}2 & 1\\ 1 & 1\end{array}\right],\;\;\;\;\;
{\bf b}=\left[\begin{array}{c}0 \\ 0\end{array}\right],\;\;\;\;\; c=0$](img282.svg) |
![$\displaystyle f(x_1,x_2)=\frac{1}{2}[x_1\;x_2]\left[\begin{array}{cc}2&1\\ 1&1\...
...t[\begin{array}{c}x_1\\ x_2\end{array}\right]=\frac{1}{2}(2x_1^2+2x_1x_2+x_2^2)$](img283.svg) |
 at
at  .
.
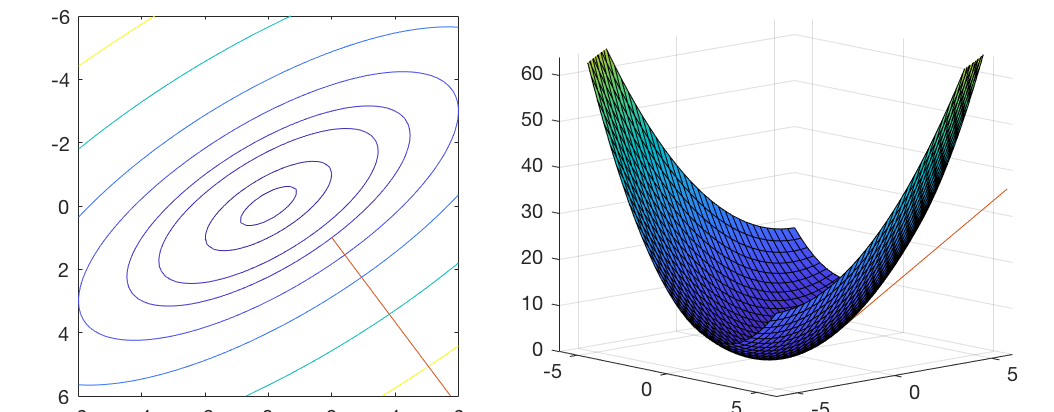
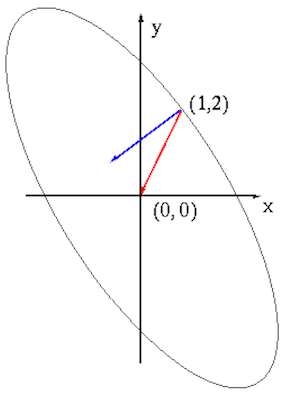
We assume the initial guess is
![${\bf x}_0=[1,\;2]^T$](img286.svg) , at which the
gradient is
, at which the
gradient is
![${\bf g}_0=[4,\;3]^T$](img287.svg) . Now we compare the gradient method
with Newton's method, in terms of the search direction
. Now we compare the gradient method
with Newton's method, in terms of the search direction  and
progress of the iterations:
and
progress of the iterations:
![$\displaystyle {\bf g}=\left[\begin{array}{c}2x_1+x_2\\ x_1+x_2\end{array}\right...
...ght],\;\;\;\;
{\bf H}^{-1}=\left[\begin{array}{rr}1&-1\\ -1&2\end{array}\right]$](img289.svg) |
![${\bf d}_0=-{\bf H}^{-1}{\bf g}_0=-[1,\;2]^T$](img290.svg) (the red arrow in the figure).
The iteration is:
(the red arrow in the figure).
The iteration is:
![$\displaystyle {\bf x}_1={\bf x}_0-{\bf H}^{-1}{\bf g}_0=\left[\begin{array}{rr}...
...array}{r}4\\ 3\end{array}\right]
=\left[\begin{array}{r}0\\ 0\end{array}\right]$](img291.svg) |
![${\bf d}_0=-{\bf g}_0=-[4,\;3]^T$](img292.svg) , perpendicular to the contour of
the function. The first iteration is:
, perpendicular to the contour of
the function. The first iteration is:
![$\displaystyle {\bf x}_1={\bf x}_0-\delta{\bf g}_0
=\left[\begin{array}{r}1\\ 2\...
...{array}\right]
=\left[\begin{array}{r}1-\delta 4\\ 2-\delta 3\end{array}\right]$](img293.svg) |
 (to be considered later)
to find
(to be considered later)
to find  , and then continue the iteration.
, and then continue the iteration.
The figure below shows the search direction of the Newton's method
(red), which reaches the solution in a single step, based on not only
the gradient  , the local information at the point
, the local information at the point  ,
but also the Hessian matrix
,
but also the Hessian matrix  , the global information of the
quadratic function, in comparison to the gradient descent method (blue)
based only on the local gradient . Without global information
representing the elliptical shape of the contour line of the
quadratic function, the gradient descent method requires an iteration,
and is therefore less effective.
, the global information of the
quadratic function, in comparison to the gradient descent method (blue)
based only on the local gradient . Without global information
representing the elliptical shape of the contour line of the
quadratic function, the gradient descent method requires an iteration,
and is therefore less effective.
In the gradient descent method, we also need to determine a proper step
size . If is too small, the iteration may converge too
slowly, especially when reduces slowly toward its minimum. On the
other hand, if is too large but has some rapid variations
in the local region, the minimum of the function may be skipped and the
iteration may not converge. We will consider how to find the optimal step
size in the next section.
