Next: The Bisection and Secant Up: Solving Equations Previous: Solving Equations
Consider a linear equation system of  equations and
equations and  variables:
variables:
 |
(1) |
 |
(2) |
![$\displaystyle {\bf A}=\left[\begin{array}{ccc}
a_{11} & \cdots & a_{1N}\\ \vdot...
...\;\;\;\;\;\;
{\bf b}=\left[\begin{array}{c}b_1\\ \vdots\\ b_M\end{array}\right]$](img43.svg) |
(3) |
 can be determined by the
fundamental theorem of linear algebra
based on the rank
can be determined by the
fundamental theorem of linear algebra
based on the rank  of the coefficient matrix
of the coefficient matrix
 . Here we only consider some speical cases:
. Here we only consider some speical cases:
 , is full rank square matrix, and
its inverse
, is full rank square matrix, and
its inverse
 exists. Then the system has a
unique solution:
exists. Then the system has a
unique solution:
 |
(4) |
 , the system is under-determined or under-constrained
and there may exist multiple solutions.
, the system is under-determined or under-constrained
and there may exist multiple solutions.
 , the system is over-determined or over-constrained
and no solution exists. However, we can still find the optimal
solution in the least-squares sense.
, the system is over-determined or over-constrained
and no solution exists. However, we can still find the optimal
solution in the least-squares sense.
We now consider solving the over-determined linear system in
last case. The error or residual of the ith equation
is defined as
 ,
or in matrix form
,
or in matrix form
 with
with
![${\bf r}=[r_1,\cdots,r_M]^T$](img54.svg) . The total sum-of-squares error
of the system is:
. The total sum-of-squares error
of the system is:
 |
 |
 |
|
|
 |
(5) |
To find the optimal solution  that minimizes
that minimizes
 , we set its derivative with respect to
to zero (see here):
, we set its derivative with respect to
to zero (see here):
 |
|
 |
|
|
 |
(6) |
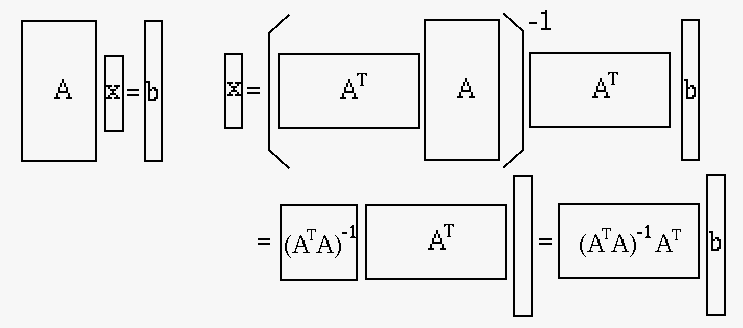
 is the pseudo-inverse
of the non-square matrix .
is the pseudo-inverse
of the non-square matrix .
When the equations are barely independent, matrix
 may be a near singular matrix with some
eigenvalues close to zero, correspondingly its inverse
may be a near singular matrix with some
eigenvalues close to zero, correspondingly its inverse
 may have some huge eigenvalues.
Consequently the system may be ill-conditioned or ill-posed,
in the sense that a small change in the system due to noise
may cause a large change in the solution .
may have some huge eigenvalues.
Consequently the system may be ill-conditioned or ill-posed,
in the sense that a small change in the system due to noise
may cause a large change in the solution .
This problem can be addressed by regularization.
Specificaly, by which the solution is controled
to not take unreasonably high values. Specifically we
construct an objective function that contains a penalty
term for large , as well as the error term
 :
:
 |
(8) |
 , we can obtain a solution
of small norm
, we can obtain a solution
of small norm
 as well as low error
as well as low error
 . Same as before, the solution
can be obtained by setting the derivative of
to
zero
. Same as before, the solution
can be obtained by setting the derivative of
to
zero
 |
(9) |
 |
(10) |
is near singular,
matrix
 is not due to the
additional term
is not due to the
additional term
 .
.
By adjusting the hyperparameter  , we can make a
proper tradeoff between accuracy and stability.
, we can make a
proper tradeoff between accuracy and stability.
: the solution is more accurate but
also more prone to noise and therefore less stable,
i.e., the variance error may be large. This is called
overfitting;
: the solution is more stable as it
is less affacted by noise, but it may be less accurate.
This is called underfitting.
