Next: Linear Regression Based on Up: Regression Analysis and Classification Previous: Linear Least Squares Regression
In a generic regression problem, the goal is to estimate the
unknown relationship
 between the dependent variable
between the dependent variable
 and the
and the  independent variables
independent variables
![${\bf x}=[x_1,\cdots,x_d]^T$](img491.svg) ,
by a model function
,
by a model function
 , based on a set of given
training data
, based on a set of given
training data
 ,
contaminated by some rero-mean random noise
,
contaminated by some rero-mean random noise  with variance
with variance
 :
:
![$\displaystyle y=f({\bf x})+e,\;\;\;\;\;\;\;
E[e]=0,\;\;\;\; \Var[e]=E[(e-E[e]^2)]=E[e^2]=\sigma^2$](img699.svg) |
(136) |
 ,
the estimated function
is also random,
and, by assumption, it is independent of , i.e.,
,
the estimated function
is also random,
and, by assumption, it is independent of , i.e.,
 , therefore
, therefore
![$E[e\,\hat{f}]=E[e]\,E[\hat{f}]$](img701.svg) .
.
How well the model
fits the training
data can be measured by the mean of its squared error
(SE) defined as
![$[y-\hat{f}({\bf x})]^2$](img702.svg) , called the
mean squared error (MSE):
, called the
mean squared error (MSE):
![$\displaystyle \E [ (y-\hat{f})^2 ]$](img703.svg) |
 |
![$\displaystyle \E[(f+e-\hat{f})^2 ]
=\E\left[ [ (f-E\hat{f})+(E\hat{f}-\hat{f})+e]^2 \right]$](img704.svg) |
|
|
![$\displaystyle E\left[ (f-E\hat{f})^2+(E\hat{f}-\hat{f})^2+e^2
+2 [e(f-E\hat{f})+e(E\hat{f}-\hat{f})
+(f-E\hat{f})(E\hat{f}-\hat{f}) ]\right]$](img705.svg) |
||
|
![$\displaystyle \E[(f-E\hat{f})^2]+\E[(E\hat{f}-\hat{f})^2]+E (e^2)$](img706.svg) |
||
 |
![$\displaystyle 2\E[ e(f-E\hat{f}) ]
+2\E[e(E\hat{f}-\hat{f})]
+2\E[(E\hat{f}-\hat{f})(f-E\hat{f})]$](img708.svg) |
||
|
![$\displaystyle \E[(f-E\hat{f})^2]+\E[(E\hat{f}-\hat{f})^2]+\E[e^2]$](img709.svg) |
(137) |
![$\displaystyle \left\{ \begin{array}{l}
\E[e(f-E\hat{f})]=\E[e]\;\E[f-E\hat{f}]=...
...t{f}-\hat{f})(f-E\hat{f})]=(E\hat{f}-E\hat{f})(f-E\hat{f})=0
\end{array}\right.$](img710.svg) |
(138) |
![$\E[e^2]=\sigma^2$](img711.svg) , due to the
inevitable observation error.
, due to the
inevitable observation error.
![$\E[(f-E\hat{f})^2]=(f-E\hat{f})^2$](img712.svg) ,
the squared bias, the difference between the estimated
function and the true function, measuring how well the
estimated function
,
the squared bias, the difference between the estimated
function and the true function, measuring how well the
estimated function  based on the training data
models the true function
based on the training data
models the true function  ;
;
![$\E[\hat{f}-E\hat{f}]^2=\Var[\hat{f}]$](img715.svg) ,
the variance of the estimated function , measuring the
variation of the model due to the noise in the training data.
,
the variance of the estimated function , measuring the
variation of the model due to the noise in the training data.
We therefore get the following general relationship in terms of the three types of error:
| Mean Squared Error Variance Bias Error Irreducible Error |
(139) |
![$E(e^2]=0$](img716.svg) , we have:
, we have:
| Mean Squared Error Variance Bias Error |
(140) |
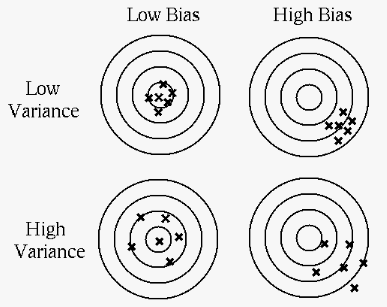
Given the total MSE and the irreducible error , the
bias error and the variance error are complementary, i.e., if
one error is higher, the other is lower, depending on the model
function produced by the specific algorithm. This is
called the
bias-variance tradoff, which is related to the major issur of
overfitting vs. underfitting in supervised learning:
 |
(141) |
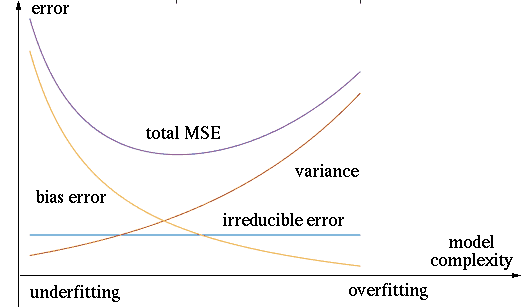
As both overfitting and underfitting result in poor predicttion
capability, they need to be avoided by making a proper tradeoff
between bias-error/underfitting and variance-error/overfitting.
This is an important issue not only in the context of regression,
but also in general in all supervised learning algorithms, for
the purpose of predicting either a value as in regression, or a
categorical class in classification, based on the output
 as a function of the given data point
. A general framework for all such algorithms is shown
below, where the algorithm in the box is to come up with a model
function
as a function of the given data point
. A general framework for all such algorithms is shown
below, where the algorithm in the box is to come up with a model
function
 of which the output
of which the output  need to match the labeling of the data point in
some optimal way:
need to match the labeling of the data point in
some optimal way:
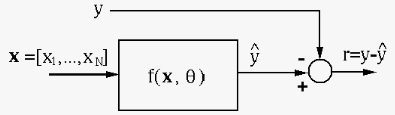
Due to the inevitable noise in the training data, all such algorithms face the same issue of how to make a proper tradeoff between overfitting and underfitting, as illustrated below.
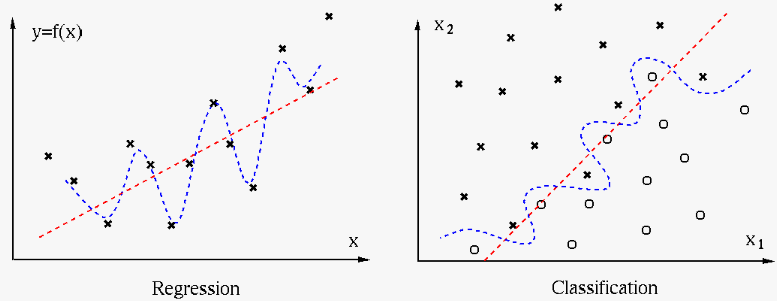
We see that in regression on the left, a set of data points is modeled by two different regression functions, while in classification on the right, the 2-D space is partitioned into two regions corresponding to two classes by two different decision boundaries. The issue is, which of the two models, in either regression or classification, fits the data better, in terms of underfitting versus overfitting.
The simple linear regression function or decision boundary (red) may underft the data as it may miss some legitimate variations in the data.
The complex regression model, e.g., a high order polynomial, or decision boundary (blue) may overfit the data as it may be overly affected by the variation due to the observation noise.
In general, based on a single set of training data points, it is impossible to distinguish between signal and random noise, and to judge whether a learning algorithm over or underfits the data. However, based on multiple datasets contaminated by different random noise, overfitting problem can be detected if the algorithm produces significantly different results when trained by different datasets. Based on this idea, the method of cross-validation can be used to train a learning algorithm by a subset of the training dataset and then test the algorithm by a different subset of the data. if the residual error during testing is large, then the algorithm may suffer from overfitting.
Many regression and classification algorithms address the issue of overfitting versus underfitting by a process called regularization to prevent overfitting, espeicially when the problem is ill-conditioned, so that the model is less sensitive to noise in the training data and therefore more generalizable, while still able to capture the essential nature and behavior of the signal. Typically this is done by adjusting some hyperparameter of the model to make a proper tradeoff between the two extremes of over and underfitting.
As an exammple, consider the method of ridge regression
for LS linear regression. If the  data points in the training
set are barely independent, then matrix
data points in the training
set are barely independent, then matrix
 has full
rank but is very close to singularity, and its smallest
eigenvalue
has full
rank but is very close to singularity, and its smallest
eigenvalue
 , the smallest singular value
, the smallest singular value
 of
of  , is close
to zero, and the normal equation
, is close
to zero, and the normal equation
 (Eq. (115)) is ill-conditioned. Now the solution
(Eq. (115)) is ill-conditioned. Now the solution
 based on the pseudo-inverse is
unstable and prone to noise. Any minor change due to noise in
the dataset (in either
based on the pseudo-inverse is
unstable and prone to noise. Any minor change due to noise in
the dataset (in either  or
or  ) may cause a
huge change in
) may cause a
huge change in  , i.e., the resulting has
a large variance error and the regression model overfits the
data and is therefore poor generalizable.
, i.e., the resulting has
a large variance error and the regression model overfits the
data and is therefore poor generalizable.
In this case, the ridge regression method can be used
to regularize the ill-conditioned problem by constructing an
objective function
 that contains a regularization
or penalty term
that contains a regularization
or penalty term
 to discourage large
weights while minimizing the error
to discourage large
weights while minimizing the error
 :
:
 is called the weight decay parameter.
Solving the equation
is called the weight decay parameter.
Solving the equation
 |
(143) |
:
: the solution is more accurate but
also more prone to noise and therefore less stable,
i.e., large variance error but small bias error, or
overfitting;
: the solution is more stable as it
is less affacted by noise, but it may be less accurate,
i.e., small variance error but large bias error, or
underfitting.

