Next: About this document ... Up: Introduction to Reinforcement Learning Previous: Deep Q-learning
All RL algorithms previous considered are based on either
state or action-value function and the policy is indectly
derived from them by greedy or  -greedy method.
However, as the ultimate goal of an RL problem is to find
the optimal policy that maximizes the return, it make
sense to consider this as an optimization problem to
directly find the optimal policy based on an objective
function representing the total return to be maximized,
by the gradient ascent method, as discussed in the
following.
-greedy method.
However, as the ultimate goal of an RL problem is to find
the optimal policy that maximizes the return, it make
sense to consider this as an optimization problem to
directly find the optimal policy based on an objective
function representing the total return to be maximized,
by the gradient ascent method, as discussed in the
following.
Previously we approximate the state value function
 and action value function
and action value function
 by
some parameterized functions
by
some parameterized functions
 and
and
 respectively, of which
the parameter
respectively, of which
the parameter  can be obtained by sampling
the environment, as a supervised learning process.
Now we construct a model of a stochastic policy as
a parameterized function:
can be obtained by sampling
the environment, as a supervised learning process.
Now we construct a model of a stochastic policy as
a parameterized function:
 |
(110) |
![${\bf\theta}=[\theta_1,\cdots,\theta_d]^T$](img470.svg) represents some
represents some  parameters of the model. As the
dimensionality is typically smaller than the
number of states and actions, such a parameterized
policy model is suitable in cases where the numbers
of states and actions are large or even continuous.
parameters of the model. As the
dimensionality is typically smaller than the
number of states and actions, such a parameterized
policy model is suitable in cases where the numbers
of states and actions are large or even continuous.
As a specific example, the policy model can be based on the soft-max function:
satisfying . Here the
summation is over all possible actions, and
. Here the
summation is over all possible actions, and
 is the preference of action
is the preference of action  in state
in state  , which
can be a parameterized function such as a simple linear
function
, which
can be a parameterized function such as a simple linear
function
 , or a
neural network with weights represented by
, or a
neural network with weights represented by
 ,
the same as how the value functions are approxmiated in
Section 1.5. According to this
policy, an action with higher preference
will have a higher probability to be chosen.
,
the same as how the value functions are approxmiated in
Section 1.5. According to this
policy, an action with higher preference
will have a higher probability to be chosen.
Different from how we find the parameter of
 by minimizing
by minimizing
 ,
the mean squared error between the value function
and its model
,
based on gradient descent, here we find the parameter
of
,
the mean squared error between the value function
and its model
,
based on gradient descent, here we find the parameter
of
 by maximizing
by maximizing
 representing the value function, the
expected return, under the policy, based on gradient
ascent. Such methods are therefore called
policy gradient methods.
representing the value function, the
expected return, under the policy, based on gradient
ascent. Such methods are therefore called
policy gradient methods.
The value-function based methods considered previously and the policy-based methods considered here are summarized below, together with the actor-critic method, as the combination of the two:
-greedy method based on the
value function learned during sampling the
environment as a supervised learning process.
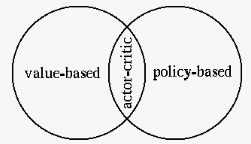
Advantages of policy-based RL includes better convergence properties, but may stuck at local optimum, effective in high-dimensional or continuous action space can learn stochastic policies, but have high variance.
How good a policy is may be measured by different objective functions all related to the values or rewards associated with the policy being evaluated, depending on the environment of the specific problem:
 :
:
 |
(112) |
 |
(113) |
 is the stationary distribution
of all states under policy
is the stationary distribution
of all states under policy
 .
.
 for
the policy model
by solving the
maximization problem:
for
the policy model
by solving the
maximization problem:
 |
(114) |
 :
:
![$\displaystyle \triangledown_\theta J(\theta)=\frac{d}{d{\theta}}J(\theta)
=\lef...
...rtial J}{\partial\theta_1},\cdots,
\frac{\partial J}{\partial\theta_n}\right]^T$](img486.svg) |
(115) |
 for the index of the iteration based on
the assumption that the a new sample point is available at
every time step of an episode while sampling the environment
following policy
.
for the index of the iteration based on
the assumption that the a new sample point is available at
every time step of an episode while sampling the environment
following policy
.
While it is conceptually straight forward to see how
gradient ascent method can be used to find the optimal
parameter
that maximizes
,
it is not easy to actually find its gradient
 , which depends on not only
what actions to take at the states directly determined
by the policy
, but also how the
states are distributed under the policy in an unknown
environment. This challenge is addressed by the following
policy gradient theorem. The proof of the theorem
below leads to an expression of the gradient
, which depends on not only
what actions to take at the states directly determined
by the policy
, but also how the
states are distributed under the policy in an unknown
environment. This challenge is addressed by the following
policy gradient theorem. The proof of the theorem
below leads to an expression of the gradient
 , which can be used
to find the optimal parameter
iteratively
by the stochastic gradient ascend method.
, which can be used
to find the optimal parameter
iteratively
by the stochastic gradient ascend method.
Proof of policy gradient theorem:


 is not a function of
is not a function of 
 in Eq. (17)
is indpendent of
in Eq. (17)
is indpendent of  and moved inside summation over
and moved inside summation over
 is expressed as a
function in terms
is expressed as a
function in terms
 .
.
We further define
 as the probability
of transitioning from state to a state
as the probability
of transitioning from state to a state  after
after  steps
following
:
steps
following
:
 |
(119) |
and get:
 can be written as
can be written as
 as a constant independent of state ,
and we also defined
as a constant independent of state ,
and we also defined
 |
(126) |
from
the start state , and
as a normalized verion of  representing the probability
distribution of visiting state while following policy
representing the probability
distribution of visiting state while following policy  .
Eq. (125) can be further written as
.
Eq. (125) can be further written as
 denotes the expectation over all actions
in each state weighted by
and all
states
denotes the expectation over all actions
in each state weighted by
and all
states  weighted by
weighted by
 .
.
Q.E.D.
We see that the gradient
 is
now expressed as the expectation of the action value function
, weighted by the gradient of the logrithm of the
corresponding policy
.
Now Eq. (116) can be further written as
is
now expressed as the expectation of the action value function
, weighted by the gradient of the logrithm of the
corresponding policy
.
Now Eq. (116) can be further written as
We further note that Eq. (125) still hold if
an arbitrary bias term  independent of action
is included:
independent of action
is included:
 |
(131) |
The expectation
in Eqs. (129)
and (132) can be dropped if the method of
stochastic gradient ascent is used, as in all algorithms
below, where each iterative step is based on only one
sample data point instead of its expectation.
Specifically, for a soft-max policy model as given in
Eq. (111), we have
 |
 |
 |
|
|
 |
||
|
 |
||
|
 |
(133) |
We list set of popular policy-based algorithms below, based on either the MC or TD methods, generally used in previous algorithms.
In this algorithm, the action value function
 in Eq. (129) is
replaced by the return
in Eq. (129) is
replaced by the return  btained at the end of each
episode while sampling the environment. Now the equation
becomes:
btained at the end of each
episode while sampling the environment. Now the equation
becomes:
 |
(134) |
 is included
as the expression for
in Eq. (128) assumed
is included
as the expression for
in Eq. (128) assumed  for simplicity.
for simplicity.
Here is the pseudo code for the algorithm:
 for each state visited
for each state visited


As its name suggests, this algorithm is based on two
approximation function models, the first for the policy
parameterized by
,
the actor, same as in the REINFORCE algorithm above,
and the second for the value function
parameterized by , the critic, same as in
Eq. (97).
Specifically, in Eq. (132), the action
value function
is replaced by its
bootstrapping expression
 ,
and the bias term is replaced by the approximated
value function
,
and the bias term is replaced by the approximated
value function
 . Now both parameters
and
can be found iteratively at
every step of an episode while sampling the environment
(the TD method) by stochastic gradient method with the
expectation
. Now both parameters
and
can be found iteratively at
every step of an episode while sampling the environment
(the TD method) by stochastic gradient method with the
expectation  dropped:
dropped:
 |
|
![$\displaystyle {\bf w}_t+\alpha_w
\left[ (r_{t+1}+\gamma\hat{v}_\pi(s',{\bf w})-\hat{v}_\pi(s,{\bf w}))
\,\triangledown_w\hat{v}_\pi(s,{\bf w})\right]$](img560.svg) |
|
 |
|
![$\displaystyle \theta_t+\alpha_\theta
\left[ (r_{t+1}+\gamma\hat{v}_\pi(s',{\bf ...
...t{v}_\pi(s,{\bf w}))
\,\triangledown_\theta\ln \pi(a\vert s,{\bf\theta})\right]$](img562.svg) |
(135) |
Here is the pseudo code for the algorithm:
and
 and
and 
 ,
,  is not terminal (for each step)
following
, find
reward and next state
is not terminal (for each step)
following
, find
reward and next state





 ) policy gradient
) policy gradient
Here is the pseudo code for the algorithm:
and
and
 and
and  ,
,
 ,
,
 is not terminal (for each step)
following
, find
reward and next state
is not terminal (for each step)
following
, find
reward and next state



Following the similar steps, the policy gradient theorem for environment with continuous state and action spaces can be also proven:
 |
(136) |





![$\displaystyle \sum_a \left[ \triangledown_\theta\pi(a\vert s,{\bf\theta})\;q_{\...
...,a)
+\pi(a\vert s,{\bf\theta})\;\triangledown_\theta q_{\pi_\theta}(s,a)\right]$](img493.svg)

![$\displaystyle \sum_a \left[ \triangledown_\theta\pi(a\vert s,{\bf\theta})\;q_{\...
...iangledown_\theta\sum_{s'}\sum_r
P(s',r\vert s,a)(r+v_{\pi_\theta}(s')) \right]$](img495.svg)

![$\displaystyle \sum_a \left[ \triangledown_\theta\pi(a\vert s,{\bf\theta})\;q_{\...
...\sum_{s'}\sum_rP(s',r\vert s,a)
\triangledown_\theta v_{\pi_\theta}(s') \right]$](img497.svg)

![$\displaystyle \sum_a \left[ \triangledown_\theta\pi(a\vert s,{\bf\theta})\;q_{\...
...f\theta})\sum_{s'}P(s'\vert s,a)\triangledown_\theta v_{\pi_\theta}(s') \right]$](img499.svg)











![$\displaystyle \phi(s)+\sum_{s'}Pr_\pi(s\rightarrow s',1) \left[
\phi(s')+\sum_{s''}Pr_\pi(s'\rightarrow s'',1)\triangledown_\theta v_{\pi_\theta}(s'')\right]$](img519.svg)














![$\displaystyle E_{\pi_\theta} \left[\triangledown_\theta
\ln \pi(a\vert s,{\bf\theta})\,q_{\pi_\theta}(s,a) \right]$](img538.svg)
![$\displaystyle {\bf\theta}_{t+1}
={\bf\theta}_t+\alpha\triangledown_\theta J({\b...
...\theta}(s_t,a_t)\;\triangledown_\theta
\ln \pi(a_t\vert s_t,{\bf\theta})\right]$](img542.svg)


![$\displaystyle {\bf\theta}_{t+1}
={\bf\theta}_t+\alpha\triangledown_\theta J({\b...
...s_t,a_t)+b(s_t))\;\triangledown_\theta
\ln \pi(a_t\vert s_t,{\bf\theta})\right]$](img547.svg)