Next: Deep Q-learning Up: Introduction to Reinforcement Learning Previous: Value Function Approximation
The control algorithms based on approximated value functions also follow the general method of the general policy iteration, as illustrated bellow:
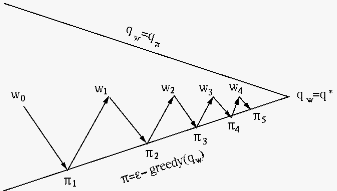
We note that this is similar to the algorithms for model-free
control illustrated in Fig. 1.4, but with
the action-value function
 is replaced by the
parameter
is replaced by the
parameter  of the approximation action function
of the approximation action function
 . In particular, for a linear function,
we have:
. In particular, for a linear function,
we have:
 is the feature vector for the
state-action pair
is the feature vector for the
state-action pair  . We need to find the optimal
parameter that minimizes the objective function,
the mean square error of the approximation:
with gradient vector:
. We need to find the optimal
parameter that minimizes the objective function,
the mean square error of the approximation:
with gradient vector:
 |
 |
![$\displaystyle \frac{d}{d{\bf w}}J({\bf w})
=-E_\pi\left[q_\pi(s,a)-\hat{q}(s,a,{\bf w})\right]
\triangledown\hat{q}(s,a,{\bf w})$](img440.svg) |
|
|
![$\displaystyle -E_\pi\left[(q_\pi(s,a)-{\bf w}^T{\bf x}(s,a)){\bf x}(s,a)\right]$](img441.svg) |
(96) |
, instead of
its expectation, then  can be dropped, and the optimal
weight vector
can be dropped, and the optimal
weight vector  that minimizes
that minimizes
 in
Eq. (95) can be learned
iteratively:
in
Eq. (95) can be learned
iteratively:
 is the increment of the update:
is the increment of the update:
 |
|
![$\displaystyle \alpha[ q_\pi(s_t,a_t)-\hat{q}_\pi(s_t,a_t,{\bf w})]
\triangledown\hat{q}_\pi(s_t,a_t,{\bf w})$](img447.svg) |
|
|
![$\displaystyle \alpha[ q_\pi(s_t,a_t)-{\bf w}_t^T{\bf x}(s_t,a_t) ]
{\bf x}(s_t,a_t)$](img448.svg) |
(98) |
in the expression
is unknown, it needs to be estimated by some target
depending on the specific methods used:
The true
is replaced by the sample return
 as the target, obtained at the end of each episode:
as the target, obtained at the end of each episode:
![$\displaystyle \Delta{\bf w}
=\alpha[G_t-\hat{q}(s_t,a_t,{\bf w})]
\triangledown \hat{q}(s_t,a_t,{\bf w})
=\alpha[G_t-{\bf w}_t^T{\bf x}(s_t,a_t)]{\bf x}(s_t,a_t)$](img449.svg) |
(99) |
The action value function
is replaced
by the TD target, the sum of the immediate reward,
available at each step of each spisode, and the
approximated action value of the next state  :
:
Following Eq. (71), the TD error is defined as:
 |
(101) |
 |
(102) |
 ) method:
) method:
In the forward-view version of the TD() method
the action function
is approximated by
-return
 as the target, available
only at the end of each spisode:
as the target, available
only at the end of each spisode:
![$\displaystyle \Delta{\bf w}
=\alpha[ G_t^\lambda-{\bf w}_t^T{\bf x}(s_t,a_t) ]{\bf x}(s_t,a_t)$](img457.svg) |
(104) |
The backward-view version of the TD() method
based on eligibility traces is more advantageous in
both space and temporal complexity as well as learning
efficiency.
We first define an eligiibility trace vector which is set to zero at the beginning of the episode, but then decays
 |
(105) |
 |
(106) |
and Eq. (70)
/////
Recall the TD error for the backward view of the
TD() method first given in
Eq. (71):
 |
(108) |
In summary, here are the conceptual (not necessarily algorithmic) steps for the general model-free control based on approximated action-value function:
as in Eq. (97),
 -greedy approach as in
Eq. (41)
-greedy approach as in
Eq. (41)
   |
(109) |

![$\displaystyle J({\bf w})
=\frac{1}{2}E_\pi[(q_\pi(s,a)-\hat{q}(s,a,{\bf w}))^2]
=\frac{1}{2}E_\pi[(q_\pi(s,a)-{\bf w}^T{\bf x}(s,a))^2]$](img439.svg)


![$\displaystyle {\bf w}_t+\alpha\left[(q_\pi(s_t,a_t)-\hat{q}_\pi(s_t,a_t,{\bf w}))
\triangledown\hat{q}_\pi(s_t,a_t,{\bf w}) \right]$](img444.svg)
![$\displaystyle {\bf w}_t+\alpha\left[(q_\pi(s_t,a_t)-{\bf w}_t^T{\bf x}(s_t,a_t))
{\bf x}(s_t,a_t) \right]$](img445.svg)

![$\displaystyle \alpha[r_{t+1}+\gamma\hat{q}(s_{t+1},a_{t+1},{\bf w})
-\hat{q}(s_t,a_t,{\bf w}) ]
\triangledown\hat{q}(s_t,a_t,{\bf w})$](img451.svg)
![$\displaystyle \alpha[r_{t+1}+\gamma{\bf w}^T{\bf x}(s_{t+1},a_{t+1})
-{\bf w}_t^T{\bf x}(s_t,a_t) ]{\bf x}(s_t,a_t)$](img452.svg)
![$\displaystyle \alpha[r_{t+1}+\gamma\max_{a'}
\hat{q}(s_{t+1},a',{\bf w})-\hat{q}(s_t,a_t,{\bf w}) ]
\triangledown\hat{q}(s_t,a_t,{\bf w})$](img455.svg)
![$\displaystyle \alpha[r_{t+1}+\gamma\max_{a'}
{\bf w}^T{\bf x}(s_{t+1},a')-{\bf w}_t^T{\bf x}(s_t,a_t)]{\bf x}(s,a)$](img456.svg)
