Next: Autoencoder Up: ch10 Previous: Perceptron
The back propagation network (BP network or BPN) is a supervised
laerning algorithm that finds a wide variety of applications in
practice. In the most general sense, a BPN can be used as an
associator to learn the relationship between two sets of patterns
represented in vector forms. Specifically in classification,
similar to the perceptron network, the BPN as a classifier is
based on the training set
![${\bf X}=[{\bf x}_1,\cdots,{\bf x}_N]$](img121.svg) ,
of which each pattern
,
of which each pattern  , a d-dimensional vector, is
associated with the corresponding pattern, an m-dimensional vector
, a d-dimensional vector, is
associated with the corresponding pattern, an m-dimensional vector
 in
in
![${\bf Y}=[{\bf y}_1,\cdots,{\bf y}_N]$](img232.svg) , as its
class identity labeling, indicating to to which of the
, as its
class identity labeling, indicating to to which of the  classs
classs
 pattern
pattern  belongs.
belongs.
Different from the perceptron in which there is only one level of learning taking place between the output and input layers in terms of the weights, a BPN is a multi-layer (three or more) hierarchical structure composed of the input, hidden, and output layers, in which learning takes place in multilevels between consecutive layers. Consequently, a BPN can be more flexible and powerful than the two-layer perceptron network. In the following, before we consider the general BPN containg multiple hidden layers, we will first derive the back propagation algorithm for the simplest BPN with only one hidden layer in between the input and output layers.
We assume the input, hidden and output layers contain respectively
 ,
,  , and
, and  nodes, each node in the hidden and output layers
is fully connected to all nodes in the previous layer. When one of
the
nodes, each node in the hidden and output layers
is fully connected to all nodes in the previous layer. When one of
the  training patterns
training patterns  is presented to the input layer
of the BPN, an m-D vector
is presented to the input layer
of the BPN, an m-D vector
 is produced at the output layer as the corresponding response to the
input . Here
is produced at the output layer as the corresponding response to the
input . Here
![${\bf W}^h=[{\bf w}^h_1,\cdots,{\bf w}^h_l]$](img235.svg) and
and
![${\bf W}^o=[{\bf w}^o_1,\cdots,{\bf w}^o_m]$](img236.svg) are the function
parameters containing the augmented weight vectors for both the
hidden and output layers, to be determined in the training
process based on the training set
are the function
parameters containing the augmented weight vectors for both the
hidden and output layers, to be determined in the training
process based on the training set  and
and  so
that its output
so
that its output
 as a function of the current input
matches the desired output, the labeling .
Once the BPN is fully trained, any unlabeled pattern
can then be classified into one of the classes corresponding
to the minimum
as a function of the current input
matches the desired output, the labeling .
Once the BPN is fully trained, any unlabeled pattern
can then be classified into one of the classes corresponding
to the minimum
 . Note that
different from the perceptron network, the output of the
output nodes are in general not binary, although they can still
be binary if either one-hot or binary encoding is used for class
labeling.
. Note that
different from the perceptron network, the output of the
output nodes are in general not binary, although they can still
be binary if either one-hot or binary encoding is used for class
labeling.
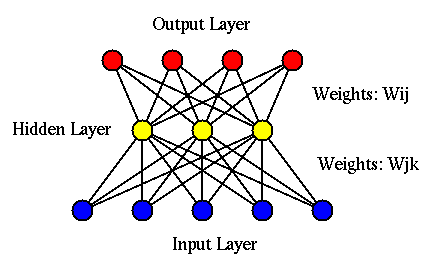
Specifically, the training of the BPN is an iteration of the following two-phase process:
A randomly selected sample labeled by is
presented to the input layer and forwarded through the weighted
connections to the hidden layer and then the output layer to
produce output
.
The squared error
 measuring the difference between the desired output
and the actual output
is propagated backward
from the output layer through the hidden layer to the input
layer, during which the weights of both the output and hidden
layers are modified so that
measuring the difference between the desired output
and the actual output
is propagated backward
from the output layer through the hidden layer to the input
layer, during which the weights of both the output and hidden
layers are modified so that
 will be reduced when
the same or similar pattern is presented in the future.
will be reduced when
the same or similar pattern is presented in the future.
We now consider the specific computation taking place in both the forward and backward passes.
![${\bf x}=[x_1,\cdots,x_d]^T$](img44.svg) represented to the input layer to the output
represented to the input layer to the output
![$\hat{\bf y}_n=[y_1,\cdots,y_m]^T$](img241.svg) produced by the output layer:
produced by the output layer:
![${\bf x}=[x_0=1,x_1,\cdots,x_d]^T$](img243.svg) and
and
![${\bf w}_j^h=[w_{j0}^h=b_j^h,w_{j1}^h,\cdots,w_{jd}^h]^T$](img244.svg) are augmented, and
are augmented, and
 is the
activation of the jth hidden layer node. These
equations can be expressed in vector form:
where
is the
activation of the jth hidden layer node. These
equations can be expressed in vector form:
where
![${\bf z}=[z_1,\cdots,z_l]^T$](img247.svg) , and
, and
![${\bf W}^h=[{\bf w}^h_1,\cdots,{\bf w}^h_l]^T$](img248.svg) is an
is an
 matrix.
matrix.
![${\bf z}=[z_0=1,z_1,\cdots,z_l]^T$](img251.svg) and
and
![${\bf w}_i^o=[w_{i0}^o=b_i^o,w_{i1}^o,\cdots,w_{il}^o]^T$](img252.svg) are augmented, and
are augmented, and
 is the
activation of the ith output layer node. These
equations can be expressed in vector form:
where
is the
activation of the ith output layer node. These
equations can be expressed in vector form:
where
![$\hat{\bf y}=[\hat{y}_1,\cdots,y_m]^T$](img255.svg) , and
, and
![${\bf W}^o=[{\bf w}^o_1,\cdots,{\bf w}^o_m]^T$](img256.svg) is an
is an
 matrix.
matrix.
to the input layer:
The squared error
 can be written as a function of the output weights
can be written as a function of the output weights
 and hidden layer
weights
and hidden layer
weights
 :
:
 |
 |
![$\displaystyle \frac{1}{2}\vert\vert{\bf y}-\hat{\bf y}\vert\vert^2
=\frac{1}{2}...
...rac{1}{2}\sum_{i=1}^m\left[g\left(\sum_{j=0}^lw_{ij}^{o}z_j\right)-y_i\right]^2$](img262.svg) |
|
|
![$\displaystyle \frac{1}{2}\sum_{i=1}^m\left[g\left(w_{i0}^o+\sum_{j=1}^l w_{ij}^...
...m_{j=1}^l w_{ij}^o\,
g\left(\sum_{k=0}^d w_{jk}^hx_k\right)\right)-y_i\right]^2$](img263.svg) |
(50) |
Similar to the objective function of the ridge regression considered in a previous section, an additional regularization term can be included in the objective function to encourage small weights to prevent overfitting:
where is the weight decay parameter and
is the weight decay parameter and
 is the
Frobenius norm.
is the
Frobenius norm.
The gradient descent method is used to modify first the
output layer weights and then the hidden layer weights
to iteratively reduce the objective function  in the
following steps:
in the
following steps:
with respect to the output
layer weights
 by the chain rule:
by the chain rule:
 |
(52) |
 .
.
to
reduce by gradient descent method with learning rate
or step size  :
:
 |
 |
 |
|
|
 |
(53) |
 , or in matrix form:
, or in matrix form:
 |
(54) |
![${\bf d}^o=[d_1^o,\cdots,d_m^o]^T$](img277.svg) is the elementwise
(Hadamard) product
is the elementwise
(Hadamard) product
 ,
and
,
and
 is the outer
product of
is the outer
product of  and
and
![${\bf z}=[z_0=1,z_1,\cdots,z_l]$](img281.svg) .
.
with respect to the hidden
layer weights
 by the chain rule:
by the chain rule:
 |
|
 |
|
|
 |
||
|
 |
(55) |
 |
(56) |
![$\displaystyle \left[\begin{array}{l}\delta_1^h\\ \vdots\\ \delta_l^h\end{array}...
...
\left[\begin{array}{c}d_1\\ \vdots\\ d_m\end{array}\right]
={\bf W}^o{\bf d}^o$](img288.svg) |
(57) |
 is an
is an  matrix, the same as that
defined above but with the first column of
matrix, the same as that
defined above but with the first column of  's removed.
's removed.
to
reduce by gradient descent method:
 |
|
 |
|
|
 |
(58) |
 |
(59) |
 is the elementwise product of vector
is the elementwise product of vector
 and
and
 ,
and
,
and
 is the
outer product of vectors
is the
outer product of vectors  and .
and .
In summary, here are the steps in each iteration:
![$[x_1,\cdots,x_d]^T$](img301.svg) ,
construct
,
construct  dimensional vector
dimensional vector
![${\bf x}=[1,x_1,\cdots,x_d]^T$](img302.svg) ;
;
 ,
and construct
,
and construct  dimensional vector
dimensional vector
![${\bf z} \leftarrow [1,{\bf z}]$](img305.svg) ;
;

 ;
;
 ;
;
 , where
, where
 is the same as but with
its first column removed.
is the same as but with
its first column removed.
 ;
;
is
acceptably small for all of the training patterns. Otherwise
repeat the above with another pattern in the training set.
The Matlab code for the essential part of the BPN algorithm is
listed below. Array  contains
contains  classes each with samples,
array
classes each with samples,
array  are the labelings of the
are the labelings of the  training samples, array
training samples, array
 contains the
contains the  dimensional weight vectors for the
dimensional weight vectors for the  output nodes. Also,
output nodes. Also,  is the number of hidden nodes, is
the learning rate between 0 and 1, and
is the number of hidden nodes, is
the learning rate between 0 and 1, and  is the tolerance
for the terminination of the learning iteration (e.g., 0.01).
is the tolerance
for the terminination of the learning iteration (e.g., 0.01).
function [Wh, Wo, g]=backPropagate(X,Y)
syms x
g=1/(1+exp(-x)); % Sigmoid activation function
dg=diff(g); % its derivative function
g=matlabFunction(g);
dg=matlabFunction(dg);
[d,N]=size(X); % number of inputs and number of samples
X=[ones(1,N); X]; % augment X by adding a row of x0=1
Wh=1-2*rand(L,d+1); % Initialize hidden layer weights
Wo=1-2*rand(M,L+1); % Initialize output layer weights
er=inf;
while er > tol
I=randperm(N); % random permutation of samples
er=0;
for n=1:N % for all N samples for an epoch
x=X(:,I(n)); % pick a training sample
ah=Wh*x; % activation of hidden layer
z=[1; g(ah)]; % augment z by adding z0=1
ao=Wo*z; % activation to output layer
yhat=g(ao); % output of output layer
delta=Y(:,I(n))-yhat % delta error
er=er+norm(delta)/N % test error
do=delta.*dg(ao); % Find d of output layer
Wo=Wo+eta*do*z'; % update weights for output layer
dh=(Wo(:,2:L+1)'*do).*dg(ah); % delta of hidden layer
Wh=Wh+eta*dh*x'; % update weights for hidden layer
end
end
end
The training process of BP network can also be considered as a
data modeling
problem to
fit the given data
 by a function with the weights of both the hidden and output layers
as the parameters:
by a function with the weights of both the hidden and output layers
as the parameters:
 |
(60) |
 and
that minimize the difference
and
that minimize the difference
 between
the desired and the actual outputs. The Levenberg-Marquardt algorithm
discussed previously can be used to obtain the parameters, such as
Matlab function
trainlm.
between
the desired and the actual outputs. The Levenberg-Marquardt algorithm
discussed previously can be used to obtain the parameters, such as
Matlab function
trainlm.
The three-layer BPN containing a single hidden layer discussed
above can be easily generalized to a multilayer BPN containing
any number of hidden layers (e.g., for a deep learning network)
by simply repeating steps 6 and 7 for the single hidden layer in
the algorithm list above. We assume in addition to the input layer,
there are in total learning layers including all the hidden
layers and the output layer, indexed by
 . Then step
6 above becomes:
. Then step
6 above becomes:
 |
(61) |
 is the activation
of all nodes in the lth layer,
is the activation
of all nodes in the lth layer,
 is the input to the lth
layer, output from the (l-1)th layer (
is the input to the lth
layer, output from the (l-1)th layer (
 ), and
), and
 |
(62) |
 |
(63) |
The matlab code segment below is for the BP network of multiple
hidden layers, in which is the total number of learning layers
and  is the number of nodes in the lth layer (
):
is the number of nodes in the lth layer (
):
W={1-2*rand(m(1),d+1)}; % initial weights for first layer
for l=2:L
W{l}=1-2*rand(m(l),m(l-1)+1); % initial weights for all other layers
end
er=inf;
while er > tol
I=randperm(N); % random permutation of samples
er=0;
for n=1:N % N samples for an epoch
z={1;X(:,I(n))}; % pick a training sample
a={W{1}*z{1}}; % activation of first layer
for l=2:L % the forward pass
z{l}=[1;g(a{l-1})]; % input to the lth layer
a{l}=W{l}*z{l}; % activation of the lth layer
end
yhat=g(a{L}); % actual output of last layer
delta=Y(:,I(n))-yhat; % delta error
er=er+norm(delta)/N; % test error
d{L}=delta.*dg(a{L}); % d for output layer
W{L}=W{L}+eta*d{L}*z{L}'; % upddate weights for output layer
for l=L-1:-1:1 % the backward pass
d{l}=(W{l+1}(:,2:end)'*d{l+1}).*dg(a{l}); % d for hidden layers
W{l}=W{l}+eta*d{l}*z{l}'; % upddate weights for hidden layers
end
end
end
Example 1: The classification results of two previously used 2-D
data sets are shown below. The error rates are respectively  and
and
 , and the confusion matrices are:
, and the confusion matrices are:
![$\displaystyle \left[ \begin{array}{rrr}
185 & 14 & 1 \\ 5 & 181 & 14 \\ 11 & 33...
...
\;\;\;\;\;\;\;
\left[ \begin{array}{rr}176 & 24 \\ 22 & 178 \end{array}\right]$](img335.svg) |
(64) |
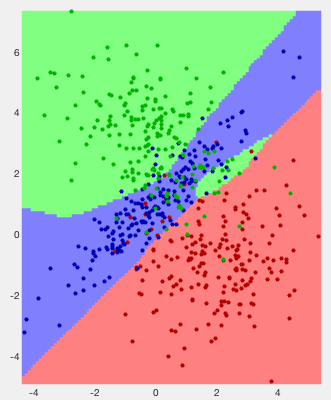
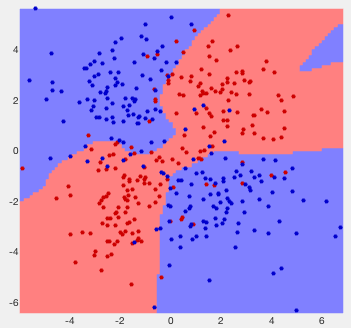
Example 2:
The back propagation network applied to the classification of the
dataset of handwritten digits from 0 to 9 used previously. Out of
the  samples in the dataset, half is used for training
while the other half for testing. Shown below are the confusion
matrices of both the training (left) and testing (right) phases.
Out of the 1120 samples for training 27 are misclassified (
samples in the dataset, half is used for training
while the other half for testing. Shown below are the confusion
matrices of both the training (left) and testing (right) phases.
Out of the 1120 samples for training 27 are misclassified ( ),
and out of the 1120 samples for testing 74 are misclassified
(
),
and out of the 1120 samples for testing 74 are misclassified
( ).
).
![$\displaystyle \left[ \begin{array}{rrrrrrrrrr}
113 & 0 & 0 & 0 & 0 & 0 & 0 & 1 ...
... & 2 & 97 & 5 \\
0 & 2 & 0 & 0 & 4 & 0 & 0 & 0 & 0 &102 \\
\end{array}\right]$](img339.svg) |
(65) |
Hierarchical structure and two pathways of the visual cortex




![$\displaystyle J({\bf W}^h,{\bf W}^o)=\varepsilon
+\frac{\lambda}{2}\left[\vert\vert{\bf W}^h\vert\vert _2^2+\vert\vert{\bf W}^o\vert\vert _2^2\right]$](img264.svg)