Next: Back Propagation Up: ch10 Previous: Hopfield Network
The perceptron network (F. Rosenblatt, 1957) is a
two-layer learning network containing an input layer of  nodes and an output layer of
nodes and an output layer of  output node. The perceptron
is a supervised method trained by dataset
output node. The perceptron
is a supervised method trained by dataset
![${\bf X}=[{\bf x}_1,\cdots,{\bf x}_N]$](img121.svg) , of which each sample
, of which each sample
![${\bf x}=[x_1,\cdots,x_d]^T$](img44.svg) is labeled by the corresponding
component in
is labeled by the corresponding
component in
![${\bf y}=[y_1,\cdots,y_N]^T$](img122.svg) , indicating to which
one of
, indicating to which
one of  catagoric classes
catagoric classes  belongs to. The goal
of the training process is to determine the weights
belongs to. The goal
of the training process is to determine the weights
![${\bf w}=[w_1,\cdots,w_d]^T$](img123.svg) and bias
and bias  so that the output
so that the output
 corresponding to input
matches its labeling
corresponding to input
matches its labeling  for all
for all  samples
in the training set in some optimal way. When the perceptron
network is fully trained, it can be used to classify any
unlabeled sample
samples
in the training set in some optimal way. When the perceptron
network is fully trained, it can be used to classify any
unlabeled sample  into one of the classes.
into one of the classes.
We first consider the special case where the output layer has
only  node, and the perceptron is a binary classifier,
same as the method of linear regression, and also the initial
setup of the support vector machine (SVM), in the sense that
all such methods are based on the linear equation
node, and the perceptron is a binary classifier,
same as the method of linear regression, and also the initial
setup of the support vector machine (SVM), in the sense that
all such methods are based on the linear equation
 , representing a hyperplane
by which the d-dimensional feature space is partitioned into
two regions corresponding to two classes
, representing a hyperplane
by which the d-dimensional feature space is partitioned into
two regions corresponding to two classes  and
and  .
When the parameters
.
When the parameters  and are determined in the
training process, any unlabeled is classified into
either of the two classes depending on whether the function
value
and are determined in the
training process, any unlabeled is classified into
either of the two classes depending on whether the function
value
 is greater or smaller than zero:
is greater or smaller than zero:
If then then |
(29) |
by
 , we get
, we get
 |
(30) |
 is the
projection of onto the normal direction
of the partitioning hyperplane, and
is the
projection of onto the normal direction
of the partitioning hyperplane, and
 is
the vector from the origin to the hyperplane (
is
the vector from the origin to the hyperplane ( is the
distance of the hyperplane to the origin). Now the
classification above can be rewritten as
is the
distance of the hyperplane to the origin). Now the
classification above can be rewritten as
If then then |
(31) |
is classified into either of the two classes
based on the projection
 of onto
, which is either greater or smaller than the bias
of onto
, which is either greater or smaller than the bias
 , depending on whether is on the positive or
negative side of the plane.
, depending on whether is on the positive or
negative side of the plane.
In all these binary classification methods the parameters
and need to be determined based on training set
 labeled by
labeled by  , but they do so differently.
While in least squares method and support vector machine these
parameters are obtained by respectively the least squared method
and quadratic programming, here in the perceptron network these
parameters are obtained by iteratively modifying some randomly
initialized values to gradually reduce the error or residual,
the difference between actual output
, but they do so differently.
While in least squares method and support vector machine these
parameters are obtained by respectively the least squared method
and quadratic programming, here in the perceptron network these
parameters are obtained by iteratively modifying some randomly
initialized values to gradually reduce the error or residual,
the difference between actual output
 and
the ground truth labeling , denoted by
and
the ground truth labeling , denoted by
 ,
for all training samples in the dataset. This method is called
the
,
for all training samples in the dataset. This method is called
the  -rule.
-rule.
We now consider specifically the training algorithm of the
perceptron network as a binary classifier. As always, we
redefine the data vector as
![${\bf x}=[x_0=1,x_1,\cdots,x_n]^T$](img148.svg) and the weight vector as
and the weight vector as
![${\bf w}=[w_0=b,w_1,\cdots,w_n]^T$](img149.svg) so
that the decision function can be more conveniently written as
an inner product
so
that the decision function can be more conveniently written as
an inner product
 without the
additional bias term.
without the
additional bias term.
The randomly initialized weight vector is iteratively
updated based on the following mistake driven -rule:
 is the step size but here called the
learning rate, which is assumed to be 1 in the
following for simplicity. We can show that by the iteration
above, is modified in such a way that the error
is always reduced.
is the step size but here called the
learning rate, which is assumed to be 1 in the
following for simplicity. We can show that by the iteration
above, is modified in such a way that the error
is always reduced.
When a training sample labeled by  is presented
to the nodes of the input layer of the perceptron, its output
is presented
to the nodes of the input layer of the perceptron, its output
 may or may not match the the label
may or may not match the the label
 , as shown in the table:
, as shown in the table:
 |
(33) |
 , the
error is
, the
error is
 , and the weight vector
, and the weight vector
 is not
modified. But in cases 2 and 3
is not
modified. But in cases 2 and 3
 , the error
is
, the error
is
 , the weight vector is modified
in either of the following two ways:
, the weight vector is modified
in either of the following two ways:
 , but
, but  , then
, then
 and
and
 , we have
When the same is presented to the network again in the
future, the function is smaller than its previous value
, we have
When the same is presented to the network again in the
future, the function is smaller than its previous value
 |
(35) |
 is more likely to be the same as the
desired .
is more likely to be the same as the
desired .
 , but
, but
 , then
and
, then
and  , we have
When the same is presented again, the function is
greater than its previoius value
, we have
When the same is presented again, the function is
greater than its previoius value
 |
(37) |
is more likely to be the same as the
desired .
and
Eq. (36) for can be combined to become
where the scaling constant  is dropped as it can be absorbed
into the learning rate if we let
is dropped as it can be absorbed
into the learning rate if we let  . Now the learning rule
can be rewritten as:
. Now the learning rule
can be rewritten as:
If then then |
(39) |
In summary, the learning law guarantees that the weight vector
is modified in such way that the performance of the
network is always improved with reduced error
 .
If and are linearly saperable, then a perceptron will
always produce in finite number of iterations to saperate
them.
.
If and are linearly saperable, then a perceptron will
always produce in finite number of iterations to saperate
them.
This binary classifier with output node can now be genrealized
to multiclass classifier with  output nodes, and each of the
weight vectors in
output nodes, and each of the
weight vectors in
![${\bf W}=[{\bf w}_1,\cdots,{\bf w}_m]$](img181.svg) is modified
by the same learning process considered above. The
is modified
by the same learning process considered above. The  classes can
be encoded by the outputs
classes can
be encoded by the outputs
 in
two different ways. If the one-hot method is used, the
binary output can encode
in
two different ways. If the one-hot method is used, the
binary output can encode  classes, i.e., the kth class is
represented by an m-bit output with
classes, i.e., the kth class is
represented by an m-bit output with  while all others
while all others  for
for  . Alternatively, if binary encoding is used, the
outputs can encode as many as
. Alternatively, if binary encoding is used, the
outputs can encode as many as  classes. For example,
classes. For example,  classes can be labeled by
classes can be labeled by  binary vector of either 4 or 2 bits:
binary vector of either 4 or 2 bits:
 or or |
(40) |
output nodes form an m-dimensional binary vector
![$\hat{\bf y}=[\hat{y}_1,\cdots,\hat{y}_m]^T$](img193.svg) , which is to be compared
with the labeling of the current input with error
, which is to be compared
with the labeling of the current input with error
 . When the training is complete, an
unlabeled input is classified to one of the classes with
a matching label to the perceptron's output. In the case of one-hot
encoding, it is possible for the binary output to not match
any of the one-hot encoded classes (e.g.,
. When the training is complete, an
unlabeled input is classified to one of the classes with
a matching label to the perceptron's output. In the case of one-hot
encoding, it is possible for the binary output to not match
any of the one-hot encoded classes (e.g.,
![$\hat{\bf y}=[-1\;1\;-1\;1]^T$](img195.svg) . In this case, the input can
be classified to the class corresponding to the node with the greatest
output value
.
. In this case, the input can
be classified to the class corresponding to the node with the greatest
output value
.
The Matlab code for the essential part of the algorithm is listed
below. Array is the dataset contains training samples,
each labeled by one of the components in array as its class
identity. Array  is a
is a
 matrix containing
matrix containing
 dimensional weight vectors each for one of the output
nodes.
dimensional weight vectors each for one of the output
nodes.
[X Y]=DataOneHot; % get data
K=length(unique(Y','rows')) % number of classes
X=[ones(1,N); X]; % data augmentation
[d N]=size(X); % number of dimensions and number of samples
m=size(Y,1); % number of output nodes
W=2*rand(d,m)-1; % random initialization of weights
eta=1;
nt=10^4; % maximum number of iteration
for it=1:nt
n=randi([1 N]); % random index
x=X(:,n); % pick a training sample x
y=Y(:,n); % label of x
yhat=sign(W'*x); % binary output
delta=y-yhat; % error between desired and actual outputs
for i=1:m
W(:,i)=W(:,i)+eta*delta(i)*x; % update weights for all K output nodes
end
if ~mod(it,N) % test for every epoch
er=test(X,Y,W);
if er<10^(-9)
break
end
end
end
This is the function that test the training set based on estimated weight
vectors in :
function er=test(X,Y,W) % test based on estimated W,
[d N]=size(X);
Ne=0; % number of misclassifications
for n=1:N
x=X(:,n);
yhat=sign(W'*x);
delta=Y(:,n)-yhat;
if any(delta) % if misclassification occurs to some output nodes
Ne=Ne+1; % update number of misclassifications
end
end
er=Ne/N; % error percentage
end
This is the code that generates the training set labeled by either one-hot or binary encoding method:
function [X,Y]=DataOneHot
d=3;
K=8;
onehot=1; % onehot=0 for binary encoding
Means=[ -1 -1 -1 -1 1 1 1 1;
-1 -1 1 1 -1 -1 1 1;
-1 1 -1 1 -1 1 -1 1];
Nk=50*ones(1,K);
N=sum(Nk); % total number of samples
X=[];
Y=[];
s=0.4;
s=0.2;
for k=1:K % for each of the K classes
Xk=Means(:,k)+s*randn(d,Nk(k));
if onehot
Yk=-ones(K,Nk(k));
Yk(k,:)=1;
else % binary encoding
dy=ceil(log2(K));
y=2*de2bi(k-1,dy)-1;
Yk=repmat(y',1,Nk(k));
end
X=[X Xk];
Y=[Y Yk];
end
Visualize(X,Y)
end
Examples
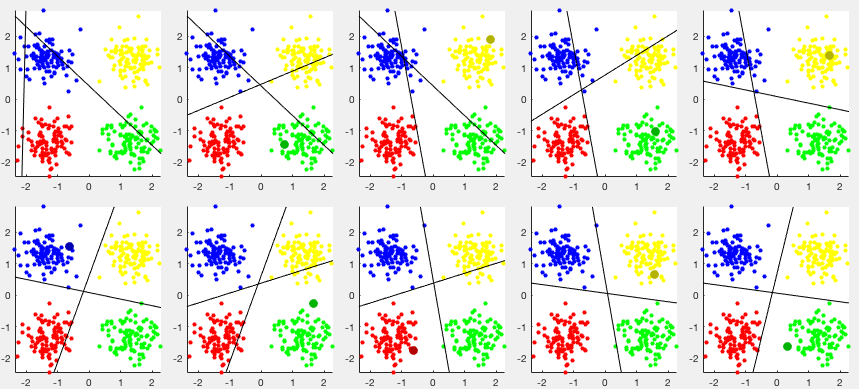
The figure below shows the classification results of a perceptron
network with  input nodes and
input nodes and  output nodes. The two output
nodes encode
output nodes. The two output
nodes encode  classes in a 2-D space. The training set contains
100 samples for each of the four classes labeled by
classes in a 2-D space. The training set contains
100 samples for each of the four classes labeled by
![${\bf y}=[y_1,\,y_2]$](img201.svg) .
The two weight vectors
.
The two weight vectors  and
and  are initialized
randomly. During the training iteration, when
are initialized
randomly. During the training iteration, when
 , the
weight vector for the output node is modified, otherwise, nothing needs
to be done. After nine such modifications, the four classes are completely
saperated by the two straight lines normal to the two weight vectors.
The first panel shows the initial stage, while the subsequent panels
show how the weight vectors are modified each time when
, the
weight vector for the output node is modified, otherwise, nothing needs
to be done. After nine such modifications, the four classes are completely
saperated by the two straight lines normal to the two weight vectors.
The first panel shows the initial stage, while the subsequent panels
show how the weight vectors are modified each time when
 .
The darker and bigger dots represent the samples presented to the
network when one of the weight vectors is modified.
.
The darker and bigger dots represent the samples presented to the
network when one of the weight vectors is modified.
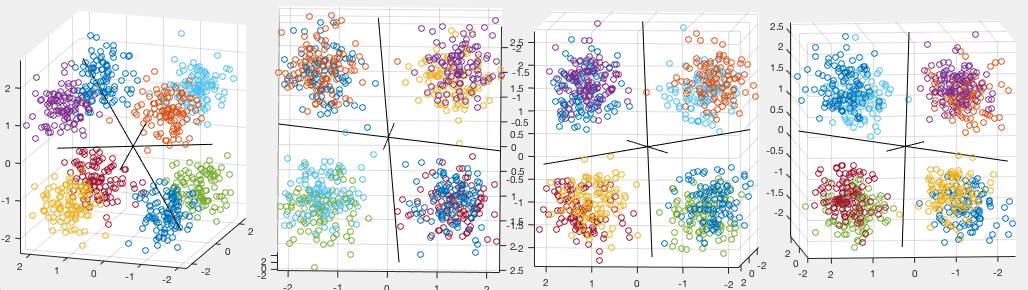
The figure below shows the classification results of a perceptron of
 input nodes and
input nodes and  output nodes encoding
output nodes encoding  classes.
After 35 modifications the weight vectors, the perceptron is completely
trained to classify all eight classes correctly. The first panel shows
the initial stage, the following three panels show the weight vectors,
, and
classes.
After 35 modifications the weight vectors, the perceptron is completely
trained to classify all eight classes correctly. The first panel shows
the initial stage, the following three panels show the weight vectors,
, and  , also the normal vectors of
the decision planes, from some three different viewing angles. We see
that the eight classes are indeed saperated by the three planes normal
to the weight vectors.
, also the normal vectors of
the decision planes, from some three different viewing angles. We see
that the eight classes are indeed saperated by the three planes normal
to the weight vectors.
The main contraint of the perceptron algorithm as a binary
classifier that the two classes are linearly separable can be
removed by the kernel method, once the algorithm is modified in
such a way that all data samples appear in the form of an inner
product. Consider first the training process in which the
training samples are repeatedly presented to the network, and
the weight vector is modified to become
 whenever a sample
labeled by is misclassified with
whenever a sample
labeled by is misclassified with
 . If the weight vector is initialized
to zero
. If the weight vector is initialized
to zero  , then the weight vector by the updating rule
in Eq. (38) can be written as a linear combination
of the training samples:
, then the weight vector by the updating rule
in Eq. (38) can be written as a linear combination
of the training samples:
 is the number of times sample labeled
by is misclassified. Upon receiving a new training sample
is the number of times sample labeled
by is misclassified. Upon receiving a new training sample
 labeled by
labeled by  , we have
, we have
 and and |
(42) |
is updated by the delta-rule:
| If |  |
||
| then |  |
||
 i.e. i.e. |
(43) |
 need to be updated
during the training process, while the weight vector in
Eq. (41) no longer needs to be explicitly
calculated. Once the training process is complete, any unlabeled
can be classified into either of the two classes based
on
:
need to be updated
during the training process, while the weight vector in
Eq. (41) no longer needs to be explicitly
calculated. Once the training process is complete, any unlabeled
can be classified into either of the two classes based
on
:
If then then |
(44) |
As all data samples appear in the form of inner product in both
the training and testing phase, the kernel method can be applied to
replace the inner product
 by a kernel function
by a kernel function
 . Also, the discussion above for output
nodes can be generalized to output nodes.
. Also, the discussion above for output
nodes can be generalized to output nodes.
Here is the Matlab code segment for the most essential parts of the kernel perceptron algorithm:
[X Y]=Data; % get dataset
[d N]=size(X); % d: dimension, N: number of training samples
X=[ones(1,N); X]; % augmented data
m=size(Y,1); % number of output nodes
A=zeros(m,N); % initialize alpha for all m output nodes and N samples
K=Kernel(X,X); % get kernel matrix of all N samples
for it=1:nt
n=randi([1 N]); % random index
x=X(:,n); % pick a training sample
y=Y(:,n); % and its label
yhat=sign((A.*Y)*K(:,n)); % get yhat
delta=Y(:,n)-yhat; % error between desired and actual output
for i=1:m % for each output node
if delta(i)~=0 % if a misclassification
A(i,n)=A(i,n)+1; % update the corresponding alpha
end
end
if ~mod(it,N) % test for every epoch
er=test(X,Y,A); % percentage of misclassification
if er<10^(-9)
break
end
end
end
function er=test(X,Y,A) % function for testing
[d N]=size(X); % d: dimension, N: number of training samples
m=size(Y,1);
Ne=0; % initialize number of misclassifications
for n=1:N % for all N training samples
x=X(:,n); % get the nth sample
y=Y(:,n); % and its label
f=(A.*Y)*Kernel(X,x); % f(x)
yhat=sign(f); % yhat=sign(f(x))
if norm(y-yhat)~=0 % misclassification at some output nodes
Ne=Ne+1; % increase number of misclassification
end
end
er=Ne/N; % percentage of misclassification
end
Example:
The kernel perceptron is applied to the dataset of handwritten
digits of  classes for the digits from 0 to 9 with
classes for the digits from 0 to 9 with  one-hot output nodes, based on the radial basis kernel. The
kernel perceptron is trained on half of the data and then tested
by the other half of the data. The confussion matricies of the
training set by the end of the training process and the test
set are both shown below. The error rate of the training set is
zeor, i.e., all training samples are correctly classified, while
the test error rate is
one-hot output nodes, based on the radial basis kernel. The
kernel perceptron is trained on half of the data and then tested
by the other half of the data. The confussion matricies of the
training set by the end of the training process and the test
set are both shown below. The error rate of the training set is
zeor, i.e., all training samples are correctly classified, while
the test error rate is  , i.e.,
, i.e.,  of the test samples
are correctly classified.
of the test samples
are correctly classified.
![$\displaystyle \left[\begin{array}{rrrrrrrrrr}
116 & 0 & 0 & 0 & 0 & 0 & 0 & 0 &...
... 1 & 3 & 93 & 4\\
1 & 2 & 0 & 1 & 7 & 0 & 0 & 3 & 6 & 96\\
\end{array}\right]$](img231.svg) |
(45) |
The constraint of the perceptron algorithm is the requirement that the classes are linear saperabe due to the fact that there is only one level of learning taking place between the output and input layers. This constraint of linear separablity will be removed when multi-layer networks are used, such as the back propagation algorithm to be discussed in the next section, and more generally, the deep learning networks containing a large number of learning layers between the input and output layers.




