Each of a set of ![]() images of
images of ![]() rows and
rows and ![]() columns and
columns and ![]() pixels can be represented as a K-D vector by concatenating its
pixels can be represented as a K-D vector by concatenating its ![]() columns
(or its
columns
(or its ![]() rows), and the
rows), and the ![]() images can be represented by a
images can be represented by a ![]() array
array ![]() with each column for one of the
with each column for one of the ![]() images:
images:
![\begin{displaymath}
{\bf X}_{K\times N}
=[{\bf x}_{c_1},\cdots,{\bf x}_{c_N}]
...
...
({\bf X}^T)_{N\times K}=[{\bf x}_{r_1},\cdots,{\bf x}_{r_K}]
\end{displaymath}](img202.png)
A KLT can be applied to either the column or row vectors of the data
array ![]() , depending on whether the column or row vectors are
treated as the realizations (samples) of a random vector.
, depending on whether the column or row vectors are
treated as the realizations (samples) of a random vector.
![\begin{displaymath}
{\bf\Sigma}_r=\frac{1}{K}\sum_{i=1}^K{\bf x}_{r_i}{\bf x}^T...
...x}_{r_K}^T\end{array}\right]
=\frac{1}{K} ({\bf X}^T{\bf X})
\end{displaymath}](img209.png)
Pre-multiplying ![]() on both sides of the eigenequation above we
get
on both sides of the eigenequation above we
get
![\begin{displaymath}
{\bf\Sigma}_c=\frac{1}{N} \sum_{i=1}^N{\bf x}_{c_i}{\bf x}^...
...f x}_{c_K}\end{array}\right]
=\frac{1}{N} ({\bf X}{\bf X}^T)
\end{displaymath}](img231.png)
Pre-multiplying ![]() on both sides we get
on both sides we get
From these two cases we see that the eigenvalue problems associated with
these two different covariance matrices
![]() and
and
![]() are equivalent, in the sense that they
have the same non-zero eigenvalues, and their eigenvectors are related by
are equivalent, in the sense that they
have the same non-zero eigenvalues, and their eigenvectors are related by
![]() or
or
![]() . We can therefore
solve the eigenvalue problem of either of the two covariance matrices,
depending on which has lower dimension.
. We can therefore
solve the eigenvalue problem of either of the two covariance matrices,
depending on which has lower dimension.
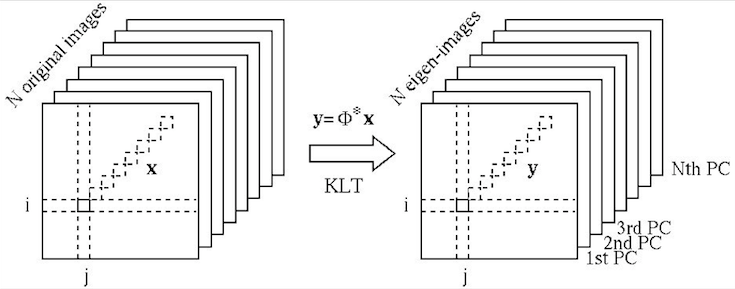
Owing to the nature of the KLT, most of the energy/information contained
in the ![]() images, representing the variations among all
images, representing the variations among all ![]() images, is
concentrated in the first few eigen-images corresponding to the greatest
eigenvalues, while the remaining eigen-images can be omitted without
losing much energy/information. This is the foundation for various
KLT-based image compression and feature extraction algorithms. The
subsequent operations such as image recognition and classification can
be carried out in a much lower dimensional space after the KLT.
images, is
concentrated in the first few eigen-images corresponding to the greatest
eigenvalues, while the remaining eigen-images can be omitted without
losing much energy/information. This is the foundation for various
KLT-based image compression and feature extraction algorithms. The
subsequent operations such as image recognition and classification can
be carried out in a much lower dimensional space after the KLT.
In image recognition, the goal is typically to classify or recognize
objects of interest, such as hand-written alphanumeric characters, or
human faces, represented in an image of ![]() pixels. As not all
pixels. As not all ![]() pixels
are necessary for representing the image object, the KLT can be carried
out to compact most of the information into a small number of components:
pixels
are necessary for representing the image object, the KLT can be carried
out to compact most of the information into a small number of components:
Example
![\begin{displaymath}
{\bf X}=\left[\begin{array}{cc}4&8 6&8 1&3 9&6\end{array}\right]
\end{displaymath}](img254.png)
![\begin{displaymath}
{\bf\Lambda}=\left[\begin{array}{cc}15.12&0 0&291.88\end{a...
...1710\\
-0.2179 & 0.1919 & -0.7369 & 0.6105\end{array}\right]
\end{displaymath}](img255.png)
![\begin{displaymath}
{\bf Y}=\left[\begin{array}{rr}
0.0000 & 0.0000\\
0.0000...
...0\\
-2.9368 & 2.5484\\
11.1971 & 12.9037\end{array}\right]
\end{displaymath}](img256.png)