The following steps are for any randomly chosen training pattern pair
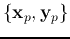 .
.
- Apply
![${\bf x}_p=[x_{p1},\cdots, x_{pN}]^T$](img230.png) to the
to the 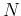 input nodes;
input nodes;
- Compute output from all
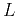 nodes in the hidden layer:
nodes in the hidden layer:
- Compute output from all
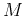 nodes in the output layer:
nodes in the output layer:
- Find the error term for each output node (not quite the same as defined
previously):
- Find error terms for all hidden nodes (not quite the same as defined
previously)
- Update weights to output nodes
- Update weights to hidden nodes
- Compute
This process is then repeated with another pair of
in the training set. When the error is acceptably small for all of the training
pattern pairs, training can be terminated.
The training process of BP network can be considered as a
data modeling problem:
The goal is to find the optimal parameters, the weights of both the hidden and
output layers, based on the observed dataset, the training data of 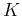 pairs
pairs
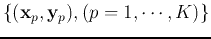 . The
Levenberg-Marquardt algorithm
discussed previously can be used to obtain the parameters, such as Matlab function
trainlm
. The
Levenberg-Marquardt algorithm
discussed previously can be used to obtain the parameters, such as Matlab function
trainlm







