Next: Naive Bayes Classification Up: ch9 Previous: Discriminative vs. Generative Methods
Here we first consider a set of simple supervised classification
algorithms that assign an unlabeled sample  to one of
the
to one of
the  known classes based on set
known classes based on set  of training samples
of training samples
![${\bf X}=[{\bf x}_1,\cdots,{\bf x}_N]$](img9.svg) , where each sample
, where each sample  is labeled by
is labeled by
 , indicating it belongs to
class
, indicating it belongs to
class  .
.
Given an unlabeled pattern , we first find its  nearest neighbors in the training dataset, and then assign
to one of the classes by a majority vote of the
neighbors based on their class labelings. The voting can be weighted
so that closer neighbors are more heavily weighted than those that
are farther away. In particular, when
nearest neighbors in the training dataset, and then assign
to one of the classes by a majority vote of the
neighbors based on their class labelings. The voting can be weighted
so that closer neighbors are more heavily weighted than those that
are farther away. In particular, when  , is assigned
to the class of its closest neighbor.
, is assigned
to the class of its closest neighbor.
While the k-NN method is simple and straight forward, its computational
cost is high as classifying any unlabeled pattern requires
computing distances to all data points in the training set.
Given a set of training data points
 all belonging to the kth class (
all belonging to the kth class (
 ), we can find their
mean and covariance to represent the class:
), we can find their
mean and covariance to represent the class:
 |
(1) |
can be classified to one of the
classes based on certain distance
 between
and each of class :
between
and each of class :
if then then |
(2) |
We could simply use the Euclidean distance
 between and
between and  . But such a classification may not
reliable as Euclidean distance does not take into consideration the
covariance
. But such a classification may not
reliable as Euclidean distance does not take into consideration the
covariance
 representing how the
representing how the  samples are
distributed in the feature space, as illustrated by the following
example.
samples are
distributed in the feature space, as illustrated by the following
example.
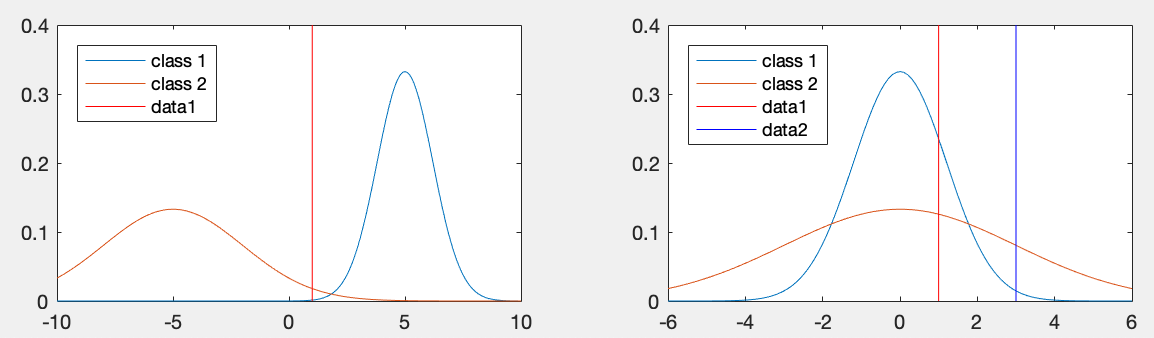
Example 1: As illustrated in the figure below (left plot), a
point  in 1-D space is to be classified into one of the two
classes represented by their corresponding Gaussian pdfs:
in 1-D space is to be classified into one of the two
classes represented by their corresponding Gaussian pdfs:
 |
(3) |
 and
and  are considered, we have
are considered, we have
 , i.e., is closer to
, i.e., is closer to  than
than  and therefore should be classified to class
and therefore should be classified to class  . However,
as shown in the plot,
. However,
as shown in the plot,  should be classified to class
should be classified to class  , if the
variances
, if the
variances
 and
and
 are also taken into consideration.
are also taken into consideration.
We see the distance
should be positively related
to
 , but inversely related to
, but inversely related to  , i.e., we can
define
, i.e., we can
define
 . Based on this distance, we find
. Based on this distance, we find
 , i.e., should be
classified to .
, i.e., should be
classified to .
In a higher dimensional feature space, we can carry out classification
based on the more generally defined Mahalanobis distance between
a point and a distribution represented by and
:
 |
(4) |
Example 2: As illustrated in the above figure (right plot), two
samples  and
and  are to be classified into either of two
classes:
are to be classified into either of two
classes:
 |
(5) |
 are the same,
are the same,
 for both samples
for both samples  and
and  , they are both classified into
with a greater variance
, they are both classified into
with a greater variance
 therefore smaller
Mahalanobis distances:
therefore smaller
Mahalanobis distances:
 |
(6) |
should be classified to .
We therefore see that sometimes the Mahalanobis distance is not reliable
for classification, and some better method need to be considered, as
discussed later.