Next: Kernel Methods Up: Principal Component Analysis Previous: Comparison with Other Orthogonal
The KLT can be applied to a set of  images for various purposes such as
data compression and feature extraction. There are two alternative ways to
carry out the KLT on the images each containing
images for various purposes such as
data compression and feature extraction. There are two alternative ways to
carry out the KLT on the images each containing  pixels, depending
on how the random vector
pixels, depending
on how the random vector  is defined based on the image data
which can be represented in the form of an
is defined based on the image data
which can be represented in the form of an  2-D array.
2-D array.
-dimensional vector  can be formed by all
pixels (by concatenating the rows or columns) of each of the
images. These vectors each for one of the images are represented
by a
can be formed by all
pixels (by concatenating the rows or columns) of each of the
images. These vectors each for one of the images are represented
by a  data array
data array
![${\bf X}=[{\bf x}_1,\cdots,{\bf x}_N]$](img6.svg) , and
treated as the samples of a K-dimensional random vector , its
covariance matrix can be estimated (assuming with zero mean) as:
, and
treated as the samples of a K-dimensional random vector , its
covariance matrix can be estimated (assuming with zero mean) as:
![$\displaystyle {\bf\Sigma}=\frac{1}{N} \sum_{n=1}^N{\bf x}_n{\bf x}_n^T
=\frac{1...
...N^T\end{array}\right]
=\frac{1}{N} \left( {\bf X} {\bf X}^T \right)_{K\times K}$](img327.svg) |
(86) |
-dimensional vector can be formed by the pixels at the same
position (in the  th row and
th row and  th column of the image array) from
all images. There are such vectors each for one of the
pixels in the images. These vectors are the rows of the
th column of the image array) from
all images. There are such vectors each for one of the
pixels in the images. These vectors are the rows of the  defined above, or the columns of
defined above, or the columns of  . The covariance matrix
of these dimensional vectors can be estimated as:
. The covariance matrix
of these dimensional vectors can be estimated as:
 |
(87) |
As shown previously, these two different covariance matrices share
the same eigenvalues. The eigenequations for
 and
(with the constant coefficients
and
(with the constant coefficients  and
and  neglected) are:
neglected) are:
 |
(88) |
on both sides of the second equation we get
![$\displaystyle {\bf X}^T{\bf X} [{\bf X}^T{\bf u}]=\mu [{\bf X}^T{\bf u}].$](img335.svg) |
(89) |
 and eigenvector
and eigenvector
 when normalized. The two covariance
matrices
when normalized. The two covariance
matrices
 and
and
 have the same rank
have the same rank
 (if is not degenerate) and therefore the same number of non-zero eigenvalues.
Consequently, the KLT can be carried out based on either matrix with the same
effects in terms of the signal decorrelation and energy compaction. As the number
of pixels in the image is typically much greater than the number of images,
(if is not degenerate) and therefore the same number of non-zero eigenvalues.
Consequently, the KLT can be carried out based on either matrix with the same
effects in terms of the signal decorrelation and energy compaction. As the number
of pixels in the image is typically much greater than the number of images,
 , we will take the second approach above to treat the pixels in the same
position in all images as a sample of an -dimensional random signal vector and
carry out the KLT based on the
, we will take the second approach above to treat the pixels in the same
position in all images as a sample of an -dimensional random signal vector and
carry out the KLT based on the  covariance matrix
covariance matrix
 .
.
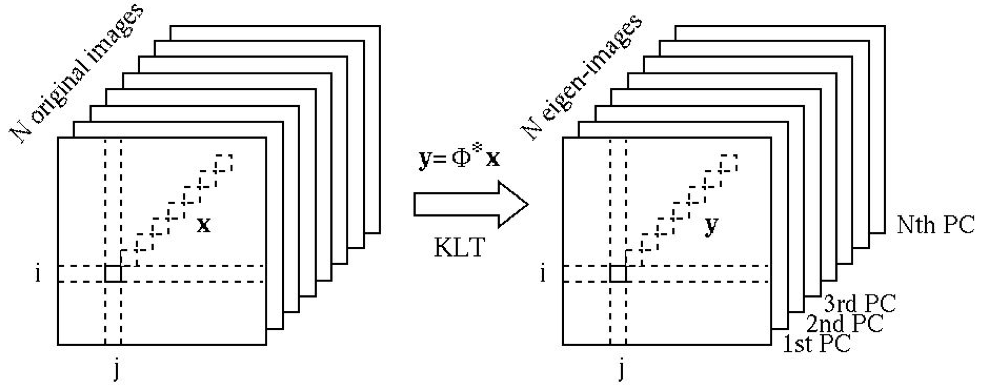
We can now carry out the KLT to each of the -dimensianl vectors
corresponding to each pixel of the images to obtain another
-dimensional vector
 for the same pixel of a
set of eigen-images, as shown below. After the KLT, most of the
energy/information contained in the images, representing the variations
among all images, is concentrated in the first few eigen-images corresponding
to the greatest eigenvalues, while the remaining eigen-images can be omitted
without losing much energy/information. This is the foundation for various
KLT-based image compression and feature extraction algorithms. The subsequent
operations such as image recognition and classification can all be carried out
in a much lower dimensional space.
for the same pixel of a
set of eigen-images, as shown below. After the KLT, most of the
energy/information contained in the images, representing the variations
among all images, is concentrated in the first few eigen-images corresponding
to the greatest eigenvalues, while the remaining eigen-images can be omitted
without losing much energy/information. This is the foundation for various
KLT-based image compression and feature extraction algorithms. The subsequent
operations such as image recognition and classification can all be carried out
in a much lower dimensional space.
We now consider some of such applications.
In remote sensing, images of the surface of either the Earth or other
planets such as Mars are taken by a multispectral camera system on board
satellite, for various studies (e.g., geology, geography, etc.). The camera
system has an array of sensors, typically a few tens or even over a
hundred, each sensitive to a different wavelength band in the visible and
infrared range of the electromagnetic spectrum. Depending on the number
of sensors, the data are referred to as either multi or hyper-spectral
images.
These sensors will produce a set of images covering the same surface
area on the ground. For the same position in these images, there are
pixel values each from one wavelength band representing the spectral profile
that characterizes the material on the surface area corresponding to the
pixel. A typical application of the multi or hyper-spectral image data is
to classify the pixels into different types of materials (different types
of rocks, vegetations, polutions, etc.). When is large, KLT can be
used to reduce the dimensionality without loss of much information.
Specifically, we consider the values associated with each pixel form
an N-dimensional random vector, and then carry out KLT to reduce its
dimensionality. All classification can be carried out in this low
dimensional space, thereby significantly reducing the computational
complexity.

A sequence of  frames of a video of a moving escalator and their
eigen-images are shown respectively in the upper and lower parts of the
figure below.
frames of a video of a moving escalator and their
eigen-images are shown respectively in the upper and lower parts of the
figure below.

It is interesting to observe that the first eigen-image corresponding to the greatest eigenvalue (left panel of the third row of the figure) represents mostly the static scene of the image frames representing the main variations in the image (carrying most of the energy), while the subsequent eigen-images represent mostly the motion in the video, the variation between the frames. For example, the motion of the people riding on the escalator is mostly reflected by the first few eigen-images following the first one, while the motion of the escalator stairs is mostly reflected in the subsequent eigen-images.
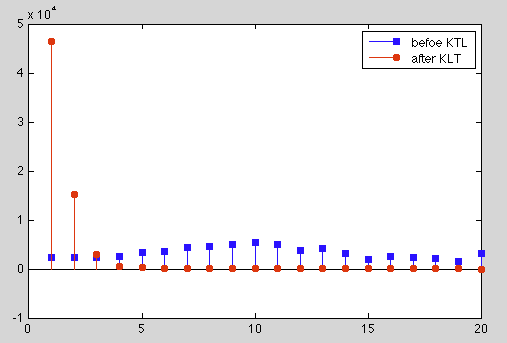
The  covariance matrix and the energy distribution among the eight
components plot before and after the KLT are shown below.
covariance matrix and the energy distribution among the eight
components plot before and after the KLT are shown below.

We see that due to the spatial correlation between nearby pixels, the covariance matrix before the KLT (left) can be modeled by the squared exponental function, while the covariance matrix after the KLT (middle) is completely decorrelated and the energy is highly compacted into a small number of principal components (here the first component), as also clearly shown in the comparison of the energy distribution before and after the KLT (right).
Twenty images of faces ( ):
):

The eigen-images after KLT:

Percentage of energy contained in the
| components | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| percentage energy | 48.5 | 11.6 | 6.1 | 4.6 | 3.8 | 3.7 | 2.6 | 2.5 | 1.9 | 1.9 | 1.8 | 1.6 | 1.5 | 1.4 | 1.3 | 1.2 | 1.1 | 1.1 | 0.9 | 0.8 |
| accumulative energy | 48.5 | 60.1 | 66.2 | 70.8 | 74.6 | 78.3 | 81.0 | 83.5 | 85.4 | 87.3 | 89. | 90.7 | 92.2 | 93.6 | 94.9 | 96.1 | 97.2 | 98.2 | 99.2 | 100.0 |
Reconstructed faces using 95% of the total information (15 out of 20 components):

The goal here is to recognize hand-written number from 0 to 9 in an image,
as those in the figure below, containing  samples for the
samples for the  numbers. Each sample in the
numbers. Each sample in the
 image can be represented by a
image can be represented by a
 dimensional vector by concatenating all columns (or
rows) of the image. The KLT can be carried out to significantlly reduce
the dimensionality of the vectors from
dimensional vector by concatenating all columns (or
rows) of the image. The KLT can be carried out to significantlly reduce
the dimensionality of the vectors from  to some
to some  , based on
either the covariance matrix
, based on
either the covariance matrix
 of all
sample vectors representing the over all distribution of these data points,
or the between-class scatter matrix
of all
sample vectors representing the over all distribution of these data points,
or the between-class scatter matrix  previously considered
representing the separability of the ten classes.
previously considered
representing the separability of the ten classes.
Specifically, we use the eigenvectors corresponding to the  greatest
eigenvalues of the covariance matrix or the between-class scatter matrix
to form a by
greatest
eigenvalues of the covariance matrix or the between-class scatter matrix
to form a by  transform matrix. After the KLT transform by the data,
certain classification algorithm can be carried out in the much reduced d'
dimensional space.
transform matrix. After the KLT transform by the data,
certain classification algorithm can be carried out in the much reduced d'
dimensional space.

The energy distribution over all signal components is plotted below
for the original signal (top), after the KLT based on (middle),
and after the KLT based on  .
.
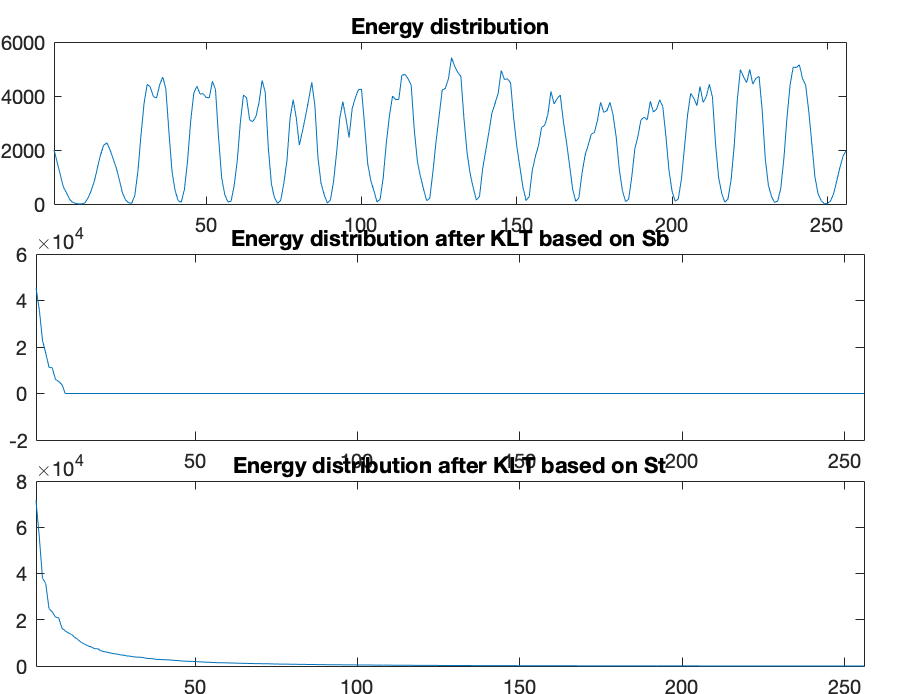
For the KLT based on with rank  ,
,  components are
needed to keep 95.1% of the total energy, in comparison to the KTL
based on with rank
components are
needed to keep 95.1% of the total energy, in comparison to the KTL
based on with rank
 , requiring are
only
, requiring are
only  principal components corresponding to the same number of
non-zero eigenvalues of to keep 100% of the total energy
representing the separability information. The percentage energy conteined
in these non-zero eigenvalues are:
principal components corresponding to the same number of
non-zero eigenvalues of to keep 100% of the total energy
representing the separability information. The percentage energy conteined
in these non-zero eigenvalues are:
 .
.
The corresponding dimensional eigenvectors can be visualized when
converted to
eigenimages, representing the basis by which any
original images can be represented as a linear combination of such eigenimages,
as shown in the figure below. The 10th eigenimage corresponding to a zero
eigenvalue contains only some random noise.

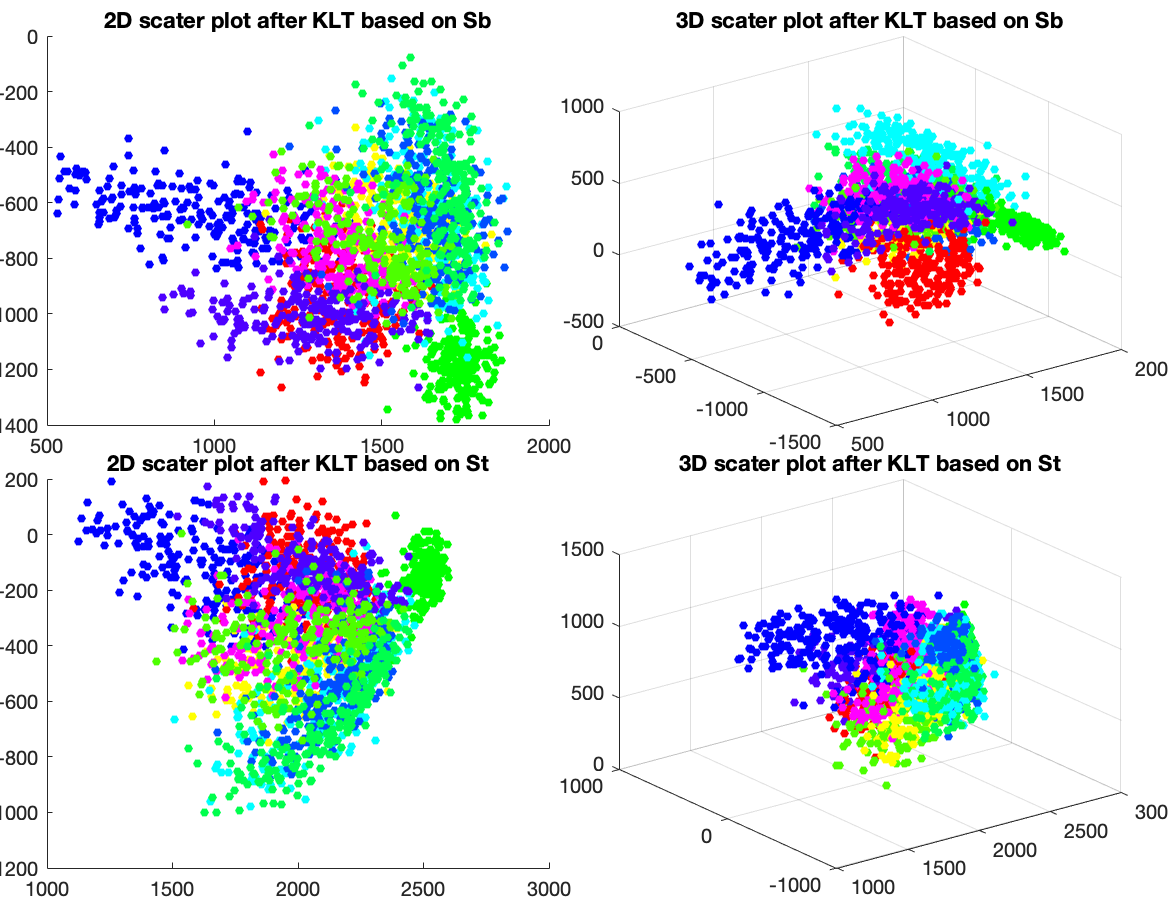
If we only keep the first two or three principal components (corresponding
to the greatest eigenvalues) after the KLT, the dataset can be visualized
as shown in the figure below. The sample points in each of the ten different
classes are color-coded. It can be seen that even when the dimensions are
much reduced from  to
to  or even
or even  , it is still possible to
separate the ten classes reasonably well.
, it is still possible to
separate the ten classes reasonably well.