Next: Kernel PCA Up: ch8 Previous: Application to Image Data
In the kernel method, all data points as a vector
![${\bf x}=[x_1,\cdots,x_d]^T$](img2.svg) in the original d-dimensional feature
space are mapped by a kernel function
in the original d-dimensional feature
space are mapped by a kernel function
 into a higher, possibly infinite, dimensional space
into a higher, possibly infinite, dimensional space
 |
(90) |
 in
the algorithm, then based on the kernel trick, the kernel
function
never needs to be actually carried
out. In fact, the form of the kernel function
in
the algorithm, then based on the kernel trick, the kernel
function
never needs to be actually carried
out. In fact, the form of the kernel function
 and
the dimensionality of the higher dimensional space do not need to
be explicitly specified or known.
and
the dimensionality of the higher dimensional space do not need to
be explicitly specified or known.
The motivation for such a kernel mapping is that the relevant operations such as classification and clustering may be carried out much more effectively once the dataset is mapped to the higher dimensional space. For example, classes not linearly separable in the original d-dimensional feature space may be trivially separable in a higher dimensional space, as illustrated by the following examples.
Example 1
In 1-D space, classes
 and
and
 or
or are not linearly
separable. By the following mappping from 1-D space to 2-D space:
are not linearly
separable. By the following mappping from 1-D space to 2-D space:
![$\displaystyle {\bf z}=\phi(x)=\left[\begin{array}{l}z_1\\ z_2\end{array}\right]
=\left[ \begin{array}{c} x \\ (x-(a+b)/2)^2 \end{array}\right]$](img364.svg) |
(91) |
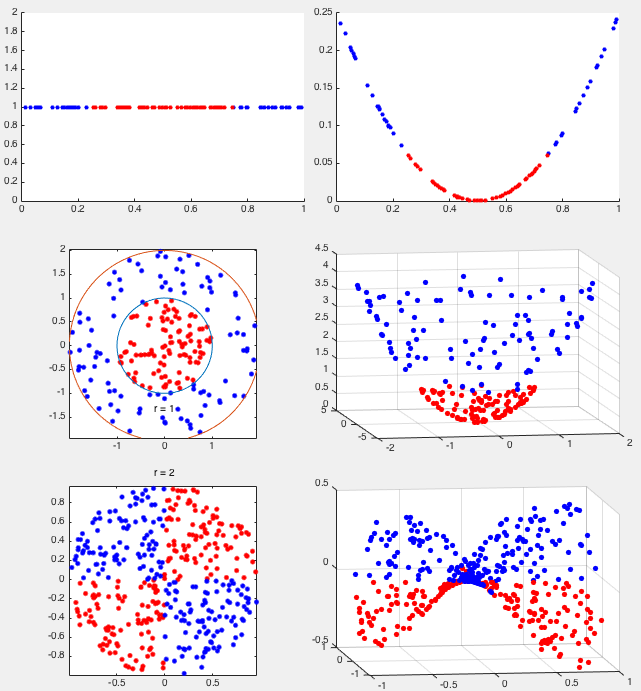
Example 2:
The method above can be generalized to higher dimensional spaces
such as mapping from 2-D to 3-D space. Consider two classes in a
2-D space that are not linearly separable:
 and
and
 . However, by the
following mappping from 2-D space to 3-D space:
. However, by the
following mappping from 2-D space to 3-D space:
![$\displaystyle {\bf z}=\phi({\bf x})=\left[\begin{array}{l}z_1\\ z_2\\ z_3\end{array}\right]
=\left[\begin{array}{c}x_1\\ x_2\\ x_1^2+x_2^2\end{array}\right]$](img367.svg) |
(92) |
Example 3:
In 2-D space, in the exclusive OR dataset, the two classes of
 containing points in quadrants I and III, and
containing points in quadrants I and III, and  containing
points in quadrants II and IV are not linearly separable. However, by
mapping the data points to a 3-D space:
containing
points in quadrants II and IV are not linearly separable. However, by
mapping the data points to a 3-D space:
![$\displaystyle {\bf z}=\phi({\bf x})=\left[\begin{array}{l}z_1\\ z_2\\ z_3\end{array}\right]
=\left[\begin{array}{c}x_1\\ x_2\\ x_1x_2\end{array}\right]$](img370.svg) |
(93) |
Definition: A kernel is a function that takes two vectors
 and
and  as arguments and returns the inner product
of their images
as arguments and returns the inner product
of their images
 and
and
 :
:
 |
(94) |
The kernel function takes as input some two vectors
and in the original feature space, and returns a scalor
value as the inner product  and
and  in some higher
dimensional space. If the data points in the original space only
appear in the form of inner product, then the kernel function
, called the kernel-induced implicit
mapping, never needs to be explicitly specified, and the dimension
of the new does not even need to be known.
in some higher
dimensional space. If the data points in the original space only
appear in the form of inner product, then the kernel function
, called the kernel-induced implicit
mapping, never needs to be explicitly specified, and the dimension
of the new does not even need to be known.
The following is a set of commonly used kernel functions
 , which can be represented as an
inner product of two vectors
and
, which can be represented as an
inner product of two vectors
and
 in a higher dimensional space.
in a higher dimensional space.
Assume
,
![${\bf x}'=[x'_1,\cdots,x'_d]^T$](img379.svg) ,
,
 |
(95) |
The binomial theorem states:
 |
(96) |
 |
(97) |
 items into two bins (
items into two bins ( in one
and
in one
and  in the other). This result can be generalized to the multinormial
case:
in the other). This result can be generalized to the multinormial
case:
 |
(98) |
 |
(99) |
balls into  bins with
bins with
 balls in the ith bin (see here), and the
summation is over all possible ways to get non-negative integers
balls in the ith bin (see here), and the
summation is over all possible ways to get non-negative integers
 that add up to .
that add up to .
Now consider the homogeneous polynomial kernel for d-dimensional vectors
defined as
 |
 |
 |
|
|
 |
(100) |
![$\displaystyle {\bf z}=\phi({\bf x})=\left[\sqrt{ \frac{n!}{k_1!\cdots k_d!} }
\...
...1}\cdots x_d^{k_d}\right),\;\left(k_i\ge 0,\;\sum_{i=1}^d k_i=n\right)\right]^T$](img392.svg) |
(101) |
In particular, when  and
and  , the polynomial kernel defined over
2-D vectors
, the polynomial kernel defined over
2-D vectors
![${\bf x}=[x_1,x_2]^T$](img394.svg) is:
is:
 |
(102) |
![${\bf z}=\phi({\bf x})=[x_1^2,\,\sqrt{2}x_1x_2,\,x_2^2]$](img396.svg) is a mapping
from
is a mapping
from  in 2-D space to
in 2-D space to  in 3-D space.
in 3-D space.
A non-homogeneous polynomial kernel is defined as
 |
(103) |
The RBF kernel is defined as
 |
(104) |
 is a parameter that can be adjusted to fit
each specific dataset. This kernel can be wriiten as the inner product of
two infinite dimensional vectors (for simplicity, we assume
is a parameter that can be adjusted to fit
each specific dataset. This kernel can be wriiten as the inner product of
two infinite dimensional vectors (for simplicity, we assume  ):
):
 |
|
 |
|
|
![$\displaystyle e^{-\vert\vert{\bf x}\vert\vert^2/2} \; e^{-\vert\vert{\bf x}'\ve...
...!}{k_1!\cdots k_d! }
\left((x_1x'_1)^{k_1}\cdots (x_dx'_d)^{k_d}\right) \right]$](img404.svg) |
||
|
 |
||
|
 |
(105) |
![$\displaystyle {\bf z}=\phi({\bf x})=\left[ e^{-\vert\vert{\bf x}\vert\vert^2/2}...
...1!\cdots k_d!}},
\;\left(n=0,\cdots,\infty,\;\sum_{k=1}^nk_i=n\right) \right]^T$](img407.svg) |
(106) |
 we have
we have
 |
|
 |
|
|
 |
(107) |
![${\bf z}=\phi(x)=\left[ e^{-x^2/2}\,x^n/\sqrt{n!},
\;(n=0,\cdots,\infty)\right]^T$](img412.svg) is a kernel function that maps a 1-D space into an infinite dimensional
space.
is a kernel function that maps a 1-D space into an infinite dimensional
space.