Next: About this document ... Up: ch10 Previous: Self-Organizing Map (SOM)

“Feature Integration and Object Representations along the Dorsal Stream Visual Hierarchy”
August 2014 Frontiers in Computational Neuroscience 8:84, 22 October 2014

“Bio-Inspired Computer Vision: Towards a Synergistic Approach of Artificial and Biological Vision”, April 2016
Computer Vision and Image Understanding 150, DOI: 10.1016/j.cviu.2016.04.009

Why vision is not both hierarchical and feedforward
Michael H. Herzog* and Aaron M. Clarke,
Laboratory of Psychophysics, Brain, Mind Institute, École Polytechnique Fédérale de Lausanne, Lausanne, Switzerland
Deep learning, hierarchical learning..
Applications include:
CNN achieves translation, rotation and distortion invariance by
Different from conventional (shallow) neural networks which depend on a set of hand-selected features, the CNN relies directly on the raw data, such as images for visual recognition or spectrograms for sound recognition, from which features are automatically extracted by the network.
Application in speech recognition: spectrogram
Convolutional neural network (CNN, or ConvNet) is a class of multilayer, feed-forward artificial neural network algorithm that has successfully been applied to image analysis and computer vision, such as image object recognition specifically.
Convolutional networks were inspired by biological processes in the brain. The connectivity pattern between neurons resembles the organization of the visual cortex. Individual cortical neurons respond to stimuli only in a restricted region of the visual field known as the
CNNs use a variation of multilayer perceptrons designed to require minimal preprocessing. They are also known as shift invariant or space invariant artificial neural networks (SIANN), based on their shared-weights architecture and translation invariance characteristics.
CNNs use relatively little pre-processing compared to conventional image classification algorithms. The network learns the filters that in traditional algorithms were hand-engineered. This independence from prior knowledge and human effort in feature design is a major advantage.
3D volumes of neurons. The layers of a CNN have neurons arranged in 3 dimensions: width, height and depth. The neurons inside a layer are connected to only a small region of the layer before it, called a receptive field. Distinct types of layers, both locally and completely connected, are stacked to form a CNN architecture.
Local connectivity: following the concept of receptive fields, CNNs exploit spatial locality by enforcing a local connectivity pattern between neurons of adjacent layers. The architecture thus ensures that the learnt "filters" produce the strongest response to a spatially local input pattern. Stacking many such layers leads to non-linear filters that become increasingly global (i.e. responsive to a larger region of pixel space) so that the network first creates representations of small parts of the input, then from them assembles representations of larger areas.
Shared weights: In CNNs, each filter is replicated across the entire visual field. These replicated units share the same parameterization (weight vector and bias) and form a feature map. This means that all the neurons in a given convolutional layer respond to the same feature within their specific response field. Replicating units in this way allows for features to be detected regardless of their position in the visual field, thus constituting the property of translation invariance.
neurons with limited receptive field
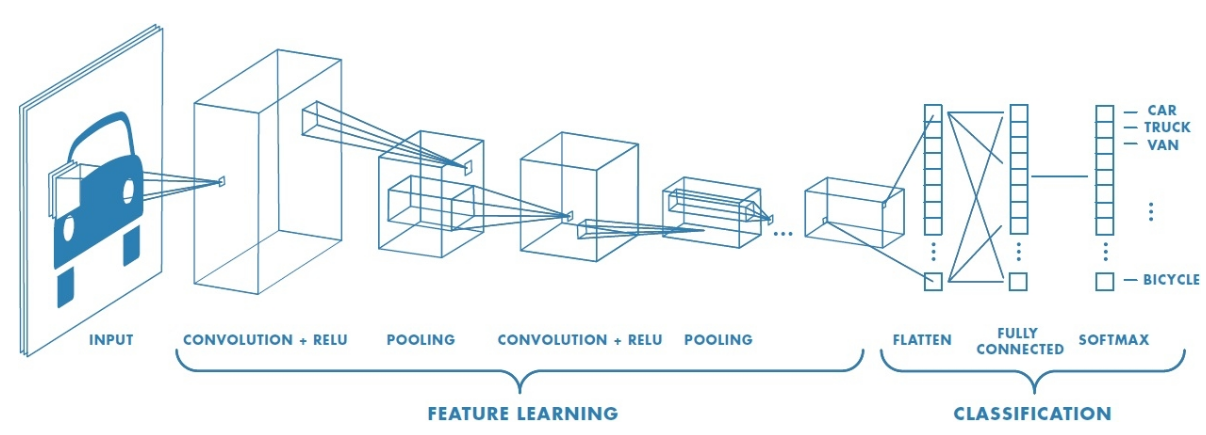
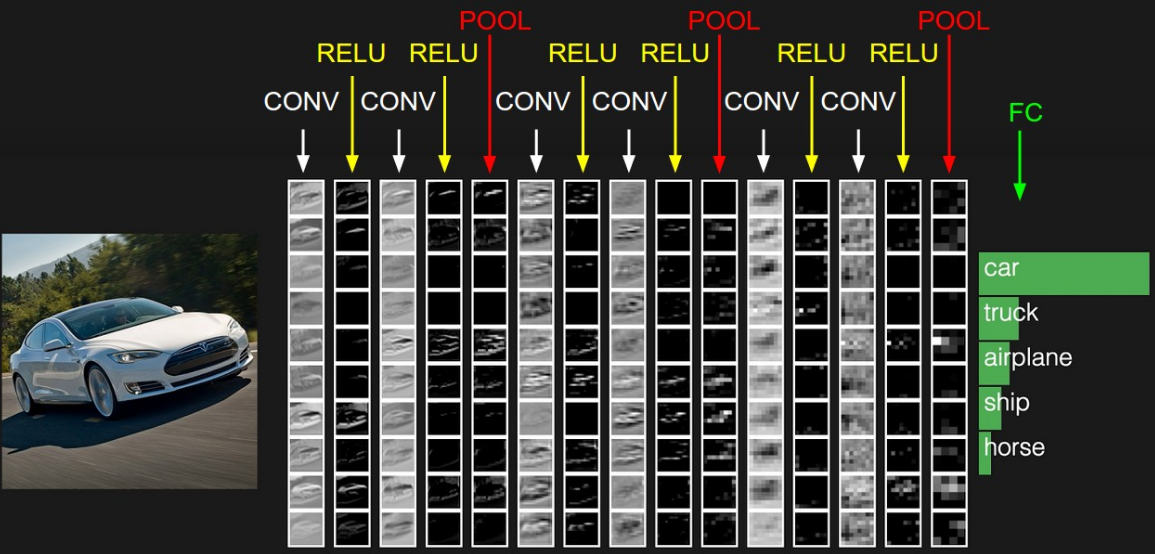
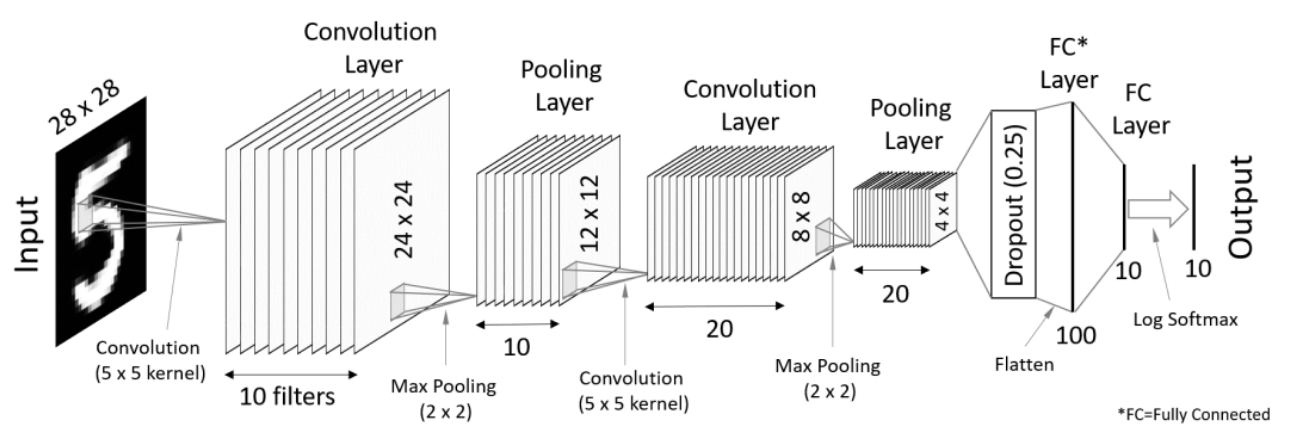
layers of different functions
 pixels in the image of three planes for
red, green and blue (RGB).
pixels in the image of three planes for
red, green and blue (RGB).