Next: Self-Organizing Map (SOM) Up: ch10 Previous: Autoencoder
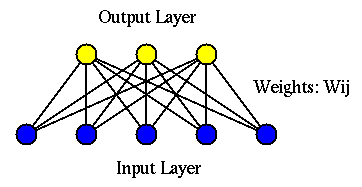
Competitive learning is a neural network algorithm for unsupervised
clustering, similar to the K-means algorithm considered previously.
The competitive learning takes place in a two-layer network composed
of an input layer of  nodes that receives an input vector
nodes that receives an input vector
![${\bf x}=[x_1,\cdots,x_d]^T$](img44.svg) as a point in the d-dimensional feature
space, and an output layer of
as a point in the d-dimensional feature
space, and an output layer of  nodes that produces an output
pattern
nodes that produces an output
pattern
![${\bf y}=[y_1,\cdots,y_m]^T$](img46.svg) representing the clusters of
interest. Each input variable
representing the clusters of
interest. Each input variable  may take either a continuous
real value or a binary value depending on the specific application,
the outputs
may take either a continuous
real value or a binary value depending on the specific application,
the outputs
 are binary, of which only one is 1
while all others are 0 (one-hot), as the result of a winner-take-all
completition based on their activation values.
are binary, of which only one is 1
while all others are 0 (one-hot), as the result of a winner-take-all
completition based on their activation values.
In each iteration of the learning process, a pattern  randomly chosen from the unlabeled dataset
randomly chosen from the unlabeled dataset
![${\bf X}=[{\bf x}_1,\cdots,{\bf x}_N]$](img121.svg) is presented to the input
layer of the network, while each node of the output layer gets an
activation value, a linear combination of all such inputs, i.e.,
the inner product of its weight vector
is presented to the input
layer of the network, while each node of the output layer gets an
activation value, a linear combination of all such inputs, i.e.,
the inner product of its weight vector  and the input
vector :
and the input
vector :
 |
(76) |
 is the angle between vectors and
in the d-dimensinal feature space. If the data vectors are optionally
normalized with unit length
is the angle between vectors and
in the d-dimensinal feature space. If the data vectors are optionally
normalized with unit length
 , i.e., they are points
on the unit hypersphere in the space. Optionally if the weight vectors
is also normalized with
, i.e., they are points
on the unit hypersphere in the space. Optionally if the weight vectors
is also normalized with
 , then their inner
product above is only affected by the angle between them.
, then their inner
product above is only affected by the angle between them.
The output of the network is determined by a winner-take-all competition. The node in the output layer that is maximally activated will output 1 while all others output 0:
 |
(77) |
 is closely related to the
Euclidean distance
is closely related to the
Euclidean distance
 :
:
 |
 |
 |
|
|
 |
(78) |
and are normalized, the winning node
with the maximum activation
 also has the
minimum Euclidean distance
also has the
minimum Euclidean distance
 and anglular
distance . Therefore the competition above can also be
expressed as the following:
and anglular
distance . Therefore the competition above can also be
expressed as the following:
 |
(79) |
 |
(80) |
 is the learning rate (step size). Optionally the
new weight vector can also be renormalized. For the iteration
process to gradually approach a stable clustering result, the
learning rate
is the learning rate (step size). Optionally the
new weight vector can also be renormalized. For the iteration
process to gradually approach a stable clustering result, the
learning rate  needs to be reduced through the iterations
from its initial value (e.g.,
needs to be reduced through the iterations
from its initial value (e.g.,
 ) toward 0 by a certain
decay factor
) toward 0 by a certain
decay factor  (e.g.,
(e.g.,
 ). This way the learning
rate decays exponentially for the learning process to gradually
slow down and becomes stabalized. The decay factor depends
on the size of the dataset, and it may need to be determined
heuristically and experimentally.
). This way the learning
rate decays exponentially for the learning process to gradually
slow down and becomes stabalized. The decay factor depends
on the size of the dataset, and it may need to be determined
heuristically and experimentally.
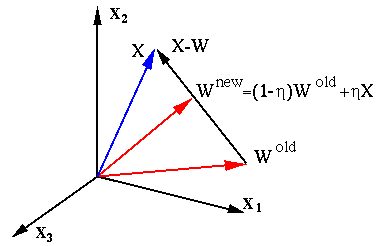
The competitive learing is illustrated in the figure above, where
the modified weight vector of the winner
 is between
and the old
is between
and the old
 , i.e., the effect of the
learning process is that the winner's weight vector which is closest
to the current input pattern is pulled even closer to it.
, i.e., the effect of the
learning process is that the winner's weight vector which is closest
to the current input pattern is pulled even closer to it.
Here are the iterative steps in the competitive learning:
, initialize
randomly the weight vectors  for the output nodes
(e.g., any randomly chosen samples from the dataset):
for the output nodes
(e.g., any randomly chosen samples from the dataset):
 , set
iteration index to zero
, set
iteration index to zero  ;
;
from the
dataset and calculate the activation for each of the output nodes:
 |
(81) |
 ,
and update its weights:
,
and update its weights:
 |
(82) |
 .
Optionally, renormalize
.
Optionally, renormalize
 .
.
is reduced from
its initial value  to some small value (e.g., 0.1) and the
weight vectors no longer change significantly. Otherwise
to some small value (e.g., 0.1) and the
weight vectors no longer change significantly. Otherwise
 , go back to Step 1.
, go back to Step 1.
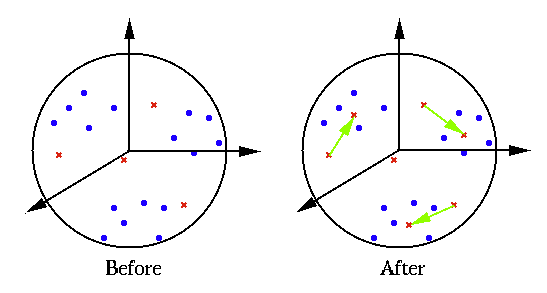
This iterative process can be more intuitively understood as shown
in the figure below. Every time a sample (a red dot) is
presented to the input layer, one of the output nodes will become
the winner and its weight vector (an blue x) closest to
the current input is drawn even closer to . As
this process is carried out iteratively many times, each cluster
of similar sample points in the space will draw one of the weight
vectors towards its centeral area, and the corresponding output node
will always win and output 1 whenever any member of the cluster is
presented to the network in the future. In other words, after this
unsupervised learning, the feature space is partitioned into  regions each corresponding to one of the clusters, represented
by one of the output nodes, whose weight vector is in the central
area of the region. We see that this process is very similar to the
K-means clustering algorithm, in which each cluster is represented
by the mean vector of all of its members.
regions each corresponding to one of the clusters, represented
by one of the output nodes, whose weight vector is in the central
area of the region. We see that this process is very similar to the
K-means clustering algorithm, in which each cluster is represented
by the mean vector of all of its members.
It is possible in some cases that the data samples are not distributed in such a way that they form a set of clearly saperable clusters the feature space. In the extreme case, they may even form a continuum. In such cases, a small number of output nodes (possibly even just one) may become frequent winners, while others become “dead nodes” if they never win and consequently never get the chance to odify their weight vectors. To avoid such meaningless outcome, a mechanism is needed to ensure that all nodes have some chance to win. This can be implemented by including an extra bias term in the learning rule:
 |
(83) |
 is the bias term proportional to the difference between
the “fair share” of winning
is the bias term proportional to the difference between
the “fair share” of winning  and the actual winning frequency:
and the actual winning frequency:
 |
(84) |
for the ith node will change its
winning frequency. If the node is winning more than its share ,
then  and it becomes harder for it to win in the future. On
the other hand, if the node rarely wins,
and it becomes harder for it to win in the future. On
the other hand, if the node rarely wins,  and its chance to win
in the future is increased. Here hyperparameter
and its chance to win
in the future is increased. Here hyperparameter  is some scaling
coefficient. The greater , the more balanced the competition will
be. It needs to be fine tuned based on the specific nature of the
data being analyzed.
is some scaling
coefficient. The greater , the more balanced the competition will
be. It needs to be fine tuned based on the specific nature of the
data being analyzed.
This process of competitive learning can also be viewed as a
vector quantization process, by which the continuous vector
space is quantized to become a set of discrete regions, called
Voronoi diagram (tessellation).
Vector quantization can be used for data compression. A cluster of
similar signals in the vector space can all be approximately
represented by the weight vector of one of a small number of
output nodes in the neighborhood of , thereby the data
size can be significantly reduced.
The Matlab code for the iteration loop of the algorithm is listed below.
[d N]=size(X); % dataset containing N samples
b=zeros(1,K); % bias terms for K clusters
freq=zeros(1,K); % winning frequencies
eta=0.9; % initial learning rate
decay=0.99; % decay rate
it=0;
while eta>0.1 % main iterations
it=it+1;
W0=W; % initial weight vectors
x=X(:,randi(N,1)); % randomly select an input sample
dmin=inf;
for k=1:K % find winner among all K output nodes
d=norm(x-W(:,k))-b(k);
if dmin>d
dmin=d; m=k; % mth node is the winner
end
end
w=W(:,m)+eta*(x-W(:,m)); % modify winner's weights
W(:,m)=w/norm(w); % renormalize its weights (optional)
share(m)=share(m)+1; % update share for winner
b=c*(1/K-share/it); % modify biases for all nodes
eta=eta*decay; % reduce learning rate
end
Examples
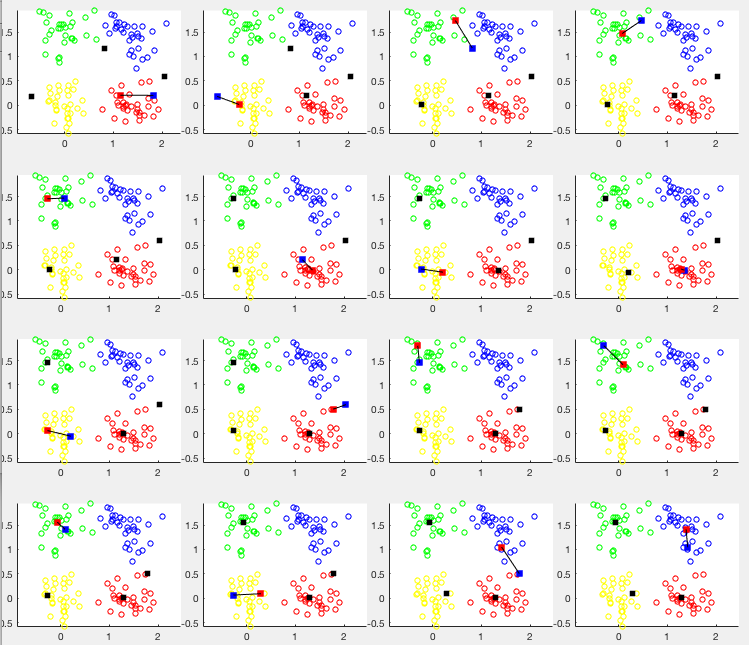
The competitive learning method is applied to a set of simulated 2-D
data of four clusters. The network has  input nodes and
input nodes and  output
nodes. The first 16 iterations are shown in the figure below, where open
circles represent the data points, while the solid back squares represent
the weight vectors. Also, the blud and red squares represent the weight
vector of the winner before and after its modification, visualized by the
straight line connecting the two squares. We see that the weight
vectors randomly initialized are iteratively modified one at a time, and
after these 16 iterations, they each move to the center of one of the
four clusters. The saperability of the clustering result measured by
output
nodes. The first 16 iterations are shown in the figure below, where open
circles represent the data points, while the solid back squares represent
the weight vectors. Also, the blud and red squares represent the weight
vector of the winner before and after its modification, visualized by the
straight line connecting the two squares. We see that the weight
vectors randomly initialized are iteratively modified one at a time, and
after these 16 iterations, they each move to the center of one of the
four clusters. The saperability of the clustering result measured by
 is 1.0. When the number of output nodes is
reduced to 3 and 2, the saperability is also reduced to 0.76 and 0.46,
respectively. When
is 1.0. When the number of output nodes is
reduced to 3 and 2, the saperability is also reduced to 0.76 and 0.46,
respectively. When  output nodes are used, one of the four clusters
is represented by two output nodes.
output nodes are used, one of the four clusters
is represented by two output nodes.
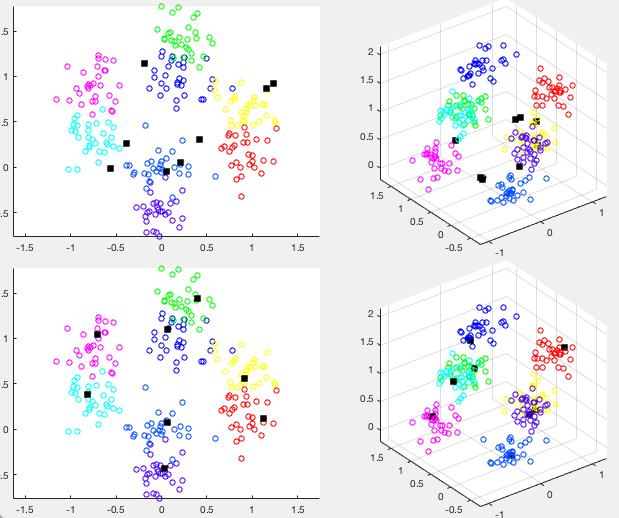
The same method is applied to a set of 3-D data of eight clusters. The results are shown in the figure below, where the top and bottom rows show the data and weight vectors before and after clustering, respectively. The left column shows the 2-D space spanned by the first two principal components, while the right column shows the original 2-D space. Again we see that the weight vectors move from their random initial locations to the centers of the eight clusters as the result of the clustering.
The competitive learning algorithm is also applied to the dataset of
handwritten digits from 0 to 9, and the clustering result is shown
as the average of all samples in each cluster in
 image
form shown in the figure below.
image
form shown in the figure below.
