The goal of the M-H algorithm is to design a Markov chain so that its
stationary distribution is the same as the desired distribution ![]() ,
i.e., after the ``burn-in'' peroid of some
,
i.e., after the ``burn-in'' peroid of some ![]() iterations, the
consecutive states
iterations, the
consecutive states ![]()
![]() of the chain are statistically
equivalent to samples drawn from
of the chain are statistically
equivalent to samples drawn from ![]() .
.
An arbitrary proposal distribution ![]() , for example,
a multivariate normal distribution with some mean vector and covariance
matrix is first assumed. A candidate state
, for example,
a multivariate normal distribution with some mean vector and covariance
matrix is first assumed. A candidate state ![]() generated by the proposal
distribution is accepted with the probability:
generated by the proposal
distribution is accepted with the probability:
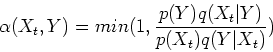
Initialize X_0, set t=0.
Repeat {
get a sample point Y from q(.|X_t)
get a sampel value u from a Uniform(0,1)
if u < \alpha(X_t, Y) then X_{t+1}=Y (Y accepted)
else X_{t+1}=X_t (Y rejected)
t=t+1
}
Proof
Now we show that the states of the Markov chain generated by the M-H
algorithm do satisfy the requirement. First we denote the probability
of the transition from a given state ![]() to the next
to the next ![]() by
by
Step 1: First we show that the detailed balance equation
defined below always holds:
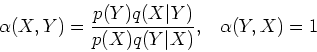
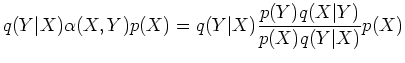 |
|||
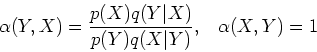
Step 2: Next we show that if ![]() is from
is from ![]() , then
, then ![]() generated by M-H method will also be from the same
generated by M-H method will also be from the same ![]() . Rewrite the
balance equation as
. Rewrite the
balance equation as