Next: t-Test for Linear Regression Up: StatisticTests Previous: Two-Way (Factorial) ANOVA
The method of regression can be used to model the relationship
between an independent variable  and a dependent variable
and a dependent variable  by a function
by a function  , based on a set of observed data pairs
, based on a set of observed data pairs
 . If there is the reason to
believe that this is a linear relationship, then we can assume
. If there is the reason to
believe that this is a linear relationship, then we can assume
 , where the two model parameters
, where the two model parameters  (intercept) and
(intercept) and  (slope) are to be found for the model to
fit the given data optimally, in the sense that the total
squared error below is minimized:
(slope) are to be found for the model to
fit the given data optimally, in the sense that the total
squared error below is minimized:
![$\displaystyle \varepsilon=\frac{1}{2}\sum_{i=1}^N r_i^2
=\frac{1}{2}\sum_{i=1}^N (y_i-\hat{y}_i)^2
=\frac{1}{2}\sum_{i=1}^N[y_i-(w_0+w_1\,x_i)]^2
$](img252.svg) (65)
(65)
 is the residual
of the ith data pair, assumed to be an i.i.d. sample of a normal
distribution
is the residual
of the ith data pair, assumed to be an i.i.d. sample of a normal
distribution
 .
To find the optimal coefficients and that minimize the
squared error
.
To find the optimal coefficients and that minimize the
squared error  , we set its derivatives with respect to
and to zero:
, we set its derivatives with respect to
and to zero:
 |
 |
 |
|
|
 |
||
 |
|
 |
|
|
 |

 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
The regression function becomes:


The univariate linear regression model considered above
can be generalized to multivariate linear regression, by
which the relationship between a dependent variable
and  independent variables
independent variables
 is
modeled by a linear function
is
modeled by a linear function
 (66)
(66)
 . We desire to find the
. We desire to find the  model parameters
model parameters
 so that the model fits optimally a
set of observed sample points
so that the model fits optimally a
set of observed sample points
 . Substituting the observed data into the
model we get
. Substituting the observed data into the
model we get  equations
equations
 (67)
(67)
 |
|
![$\displaystyle \left[\begin{array}{c}\hat{y}_1\\ \vdots\\ \hat{y}_N\end{array}...
...{\bf x}_D]
\left[\begin{array}{c} w_0\\ w_1\\ \vdots\\ w_D\end{array}\right]$](img282.svg) |
|
|
 |
![$\displaystyle {\bf w}=\left[\begin{array}{c}w_0\\ w_1\\ \vdots\\ w_D\end{array}...
...\;\;\;\;
{\bf X}=[{\bf x}_0={\bf 1},{\bf x}_1,\cdots,{\bf x}_D]_{N\times(D+1)}
$](img284.svg) (68)
(68)
 so that
so that
 , i.e.,
the observed
, i.e.,
the observed  can be expressed as a linear combination
of vectors
can be expressed as a linear combination
of vectors
 .
However, as this is an over determined equation system with
equations but only
.
However, as this is an over determined equation system with
equations but only  unknowns
unknowns
 ,
there does not exist an exact solution. We therefore can only
find the least square (LS) approximation that minimizes
the residual
,
there does not exist an exact solution. We therefore can only
find the least square (LS) approximation that minimizes
the residual
 , the squared
error:
, the squared
error:
 |
|
 |
|
|
 |
(69) |
To do so, we find its gradient (derivatives) with respect to
![${\bf w}=[w_0,w_1,\cdots,w_D]^T$](img295.svg) to zero:
to zero:
 (70)
(70)
 is the
is the
 pseudo-inverse
of
pseudo-inverse
of  .
.
We further consider some properties of the solution. First, we note that
![$\displaystyle {\bf X}^T{\bf r}=\left[\begin{array}{c}{\bf x}_0^T\\
{\bf x}_1^T\\ \vdots\\ {\bf x}_D^T\end{array}\right]{\bf r}={\bf0}
$](img301.svg) (72)
(72)
![$\displaystyle {\bf x}_0^T{\bf r}=[1,\cdots,1]{\bf r}=\sum_{n=1}^N r_n=0
$](img302.svg) (73)
residuals is zero. Now the regression
model can be written as
(73)
residuals is zero. Now the regression
model can be written as
 ,
and we have
,
and we have
 (74)
(74)
 |
|
 |
|
|
 |
 (75)
(75)
 (76)
(76)
 ,
,
 and
and
 are
perpendicular to vector
are
perpendicular to vector
![${\bf 1}=[1,\cdots,1]^T$](img313.svg) :
:
 |
|
 |
|
 |
|
 |
|
 |
|
 |
(77) |
The fact that the residual
is
perpendicular to indicates that among all linear
combinations of the vectors
 (all points on the hypersurface spanned by
these vectors),
(all points on the hypersurface spanned by
these vectors),
 is indeed the optimal
one with the minimum residual
is indeed the optimal
one with the minimum residual  .
.
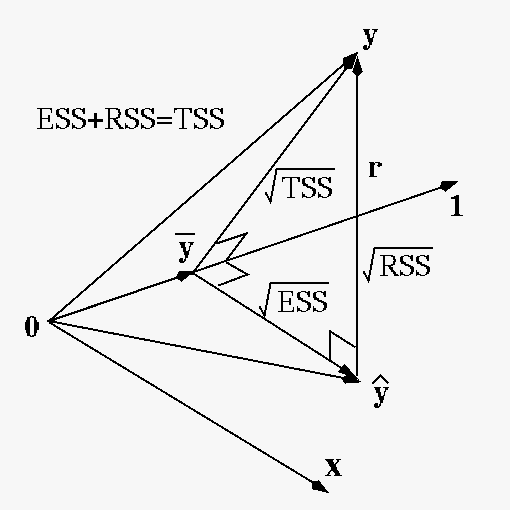
How well the regression model fits the observed data can be quantitatively measured based on the following sums of squares:
 (78)
(78)
 (79)
(79)
 (80)
(80)
We can show that the total sum of squares is the sum of the
explained sum of squares and the residual sum of squares:
 |
|
 |
|
|
 |
||
|
 |
||
|
 |
 (81)
(81)
 (R-squared) as a measure for the goodness of the model
as the percentage of variance explained by the model:
(R-squared) as a measure for the goodness of the model
as the percentage of variance explained by the model:
 (82)
is large, indicating a good
fit of the model to the data.
(82)
is large, indicating a good
fit of the model to the data.
In particular, when  , we find the parameters of the linear
regression model
, we find the parameters of the linear
regression model
 , the slope
, the slope
 and the intercept
and the intercept
 . We may ask
two different questions regarding the data and the model:
. We may ask
two different questions regarding the data and the model:
and related
to each other? This question can be addressed by the
correlation coefficient defined as:
 (83)
(83)
discussed above.
In fact,  for correlation and for regression are
closely related. Specifically, consider
for correlation and for regression are
closely related. Specifically, consider
 |
|
 |
|
|
![$\displaystyle \sum_{n=1}^N[(y_n-\bar{y})-w_1(x_n-\bar{x})]^2
=\sum_{n=1}^N[(y_n-\bar{y})^2-2w_1(y_n-\bar{y})(x_n-\bar{x})
+w_1^2(x_n-\bar{x})^2]$](img341.svg) |
||
|
 |
(84) |
is large, indicating the two variables
and are highly correlated, then SSR is small, i.e., the error
of the model is small, therefore is large, indicating the
model is a good fit of the data.
Although correlation and regression are closely related to each other, they are different in several aspects:
and are correlated will
regression analysis be meaningful.
is a dependent variable, possibly
random, a function of  , a deterministic independent
variable. But they are treated equally (both possibly random)
in correlation.
, by which the given samples can be interpolated
and extrapolated; but correlation cannot.
, a deterministic independent
variable. But they are treated equally (both possibly random)
in correlation.
, by which the given samples can be interpolated
and extrapolated; but correlation cannot.
Examples:
 (85)
(85)
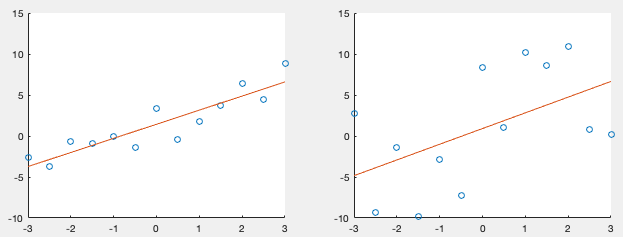
 (86)
(86)
 (
(