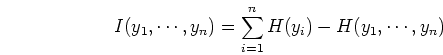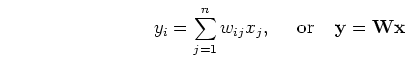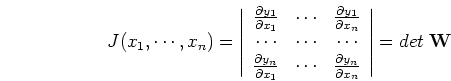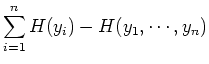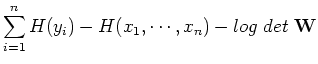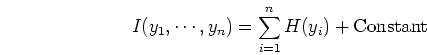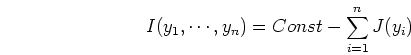Next: Preprocessing for ICA
Up: Methods of ICA Estimations
Previous: Measures of Non-Gaussianity
The mutual information 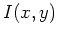 of two random variables
of two random variables 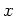 and
and 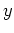 is
defined as
is
defined as
Obviously when and are independnent, i.e., 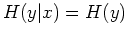 and
and
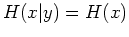 , their mutual information is zero.
, their mutual information is zero.
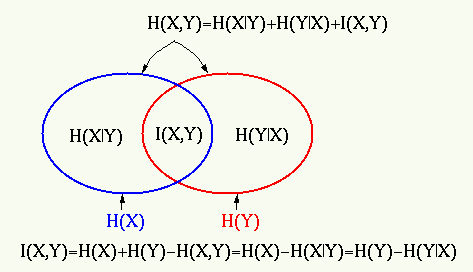
Similarly the mutual information
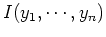 of a set of
of a set of 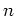 variables
variables 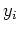 (
(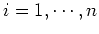 ) is defined as
) is defined as
If random vector
![${\mathbf y}=[y_1,\cdots,y_n]^T$](img80.png) is a linear transform of
another random vector
is a linear transform of
another random vector
![${\mathbf x}=[x_1,\cdots,x_n]^T$](img81.png) :
:
then the entropy of 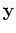 is related to that of
is related to that of 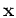 by:
by:
where
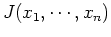 is the Jacobian of the above transformation:
is the Jacobian of the above transformation:
The mutual information above can be written as
We further assume to be uncorrelated and of unit variance, i.e., the
covariance matrix of is
and its determinant is
This means
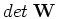 is a constant (same for any
is a constant (same for any 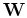 ). Also,
as the second term in the mutual information expression
). Also,
as the second term in the mutual information expression
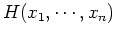 is
also a constant (invariant with respect to ), we have
is
also a constant (invariant with respect to ), we have
i.e., minimization of mutual information
is achieved by
minimizing the entropies
As Gaussian density has maximal entropy, minimizing entropy is equivalent to
minimizing Gaussianity.
Moreover, since all have the same unit variance, their negentropy becomes
where 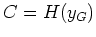 is the entropy of a Gaussian with unit variance, same for
all . Substituting
is the entropy of a Gaussian with unit variance, same for
all . Substituting
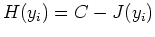 into the expression of mutual
information, and realizing the other two terms
into the expression of mutual
information, and realizing the other two terms
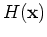 and
and
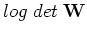 are both constant (same for any ), we get
are both constant (same for any ), we get
where 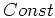 is a constant (including all terms
is a constant (including all terms 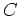 ,
and
)
which is the same for any linear transform matrix
,
and
)
which is the same for any linear transform matrix 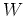 . This is the fundamental
relation between mutual information and negentropy of the variables
. This is the fundamental
relation between mutual information and negentropy of the variables 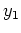 . If
the mutual information of a set of variables is decreased (indicating the
variables are less dependent) then the negentropy will be increased, and
are less Gaussian. We want to find a linear transform matrix to minimize
mutual information
, or, equivalently, to maximize negentropy
(under the assumption that are uncorrelated).
. If
the mutual information of a set of variables is decreased (indicating the
variables are less dependent) then the negentropy will be increased, and
are less Gaussian. We want to find a linear transform matrix to minimize
mutual information
, or, equivalently, to maximize negentropy
(under the assumption that are uncorrelated).
Next: Preprocessing for ICA
Up: Methods of ICA Estimations
Previous: Measures of Non-Gaussianity
Ruye Wang
2018-03-26