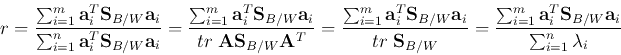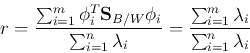Next: Suboptimal feature selection
Up: Feature Selection
Previous: Optimal transformation for maximizing
The percentage of separability information (energy) contained in the m-D space
after feature selection can be found as
where 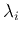 's are the eigenvalues of
's are the eigenvalues of 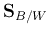 . When KLT is used, the
above can be further written as
. When KLT is used, the
above can be further written as
as here
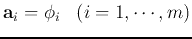 are the eigenvectors of
(corresponding to the m largest eigenvalues
are the eigenvectors of
(corresponding to the m largest eigenvalues
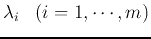 ).
).
Ruye Wang
2016-11-30