Next: Hopfield Network Up: Introduction to Neural Networks Previous: Paradigms of Learning
Donald Hebb (Canadian Psychologist) speculated in 1949 that
“When neuron A repeatedly and persistently takes part in exciting neuron B, the synaptic connection from A to B will be strengthened.”Simultaneous activation of neurons leads to pronounced increases in synaptic strength between them. In other words, "Neurons that fire together, wire together. Neurons that fire out of sync, fail to link". So a Hebbian network can be used as an associator which will establish the association between two sets of patterns
The classical conditioning (Pavlov, 1927) could be explained by Hebbian learning:

The structure
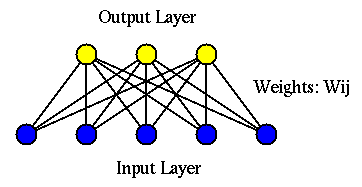
The Hebbian network is a supervised method with an input layer of ![]() nodes that take an input
nodes that take an input
![]() and an output
layer of
and an output
layer of ![]() nodes that generate output
nodes that generate output
![]() .
Each output node
.
Each output node ![]() is connected to each of the
is connected to each of the ![]() input nodes
input nodes
![]() by a weight
by a weight ![]() :
:


The learning law


Training
If we assume ![]() initially,
initially, ![]() and a set of
and a set of ![]() pairs of patterns
pairs of patterns
![]() are presented repeatedly in
random order during training, we have
are presented repeatedly in
random order during training, we have

![$\displaystyle {\bf W}_{m\times n}=\sum_{k=1}^K {\bf y}_k {\bf x}_k^T = \sum_{k=...
... \\ \vdots \\ y_m^{(k)} \end{array} \right]
[ x_1^{(k)}, \cdots, x_n^{(k)} ]
$](img18.svg)
Classification
When presented with one of the patterns ![]() , the network will produce
the output:
, the network will produce
the output:


This condition implies that the ![]() input patterns are totally unrelated
or uncorrelated to each other. How much two vectors are correlated to each
other can be measured by the angular difference
input patterns are totally unrelated
or uncorrelated to each other. How much two vectors are correlated to each
other can be measured by the angular difference ![]() between them. If
between them. If ![]() is close to 0, the two vectors are closely correlated, as their elements are
very similar to each other so that they almost coincide. When negative values
are allowed for the elements and
is close to 0, the two vectors are closely correlated, as their elements are
very similar to each other so that they almost coincide. When negative values
are allowed for the elements and ![]() is close to 180 degrees, the vectors
are also highly correlated as their elements are opposite to each other. In
either case,
is close to 180 degrees, the vectors
are also highly correlated as their elements are opposite to each other. In
either case, ![]() is close to 1 and the inner product is maximized,
indicating that the two vectors are either positively or negatively related
to each other. On the other hand, if the two vectors are perpendicular to each
other (
is close to 1 and the inner product is maximized,
indicating that the two vectors are either positively or negatively related
to each other. On the other hand, if the two vectors are perpendicular to each
other (
![]() ,
, ![]() ), the inner product of the two vectors
is zero, indicating the elements of the two vectors are irrelevant to those of
the other.
), the inner product of the two vectors
is zero, indicating the elements of the two vectors are irrelevant to those of
the other.
How much two patterns ![]() and
and ![]() are related to each other
can also be measured quantitatively, we define correlation coefficient
as:
are related to each other
can also be measured quantitatively, we define correlation coefficient
as:

In other words, if ![]() and
and ![]() are totally uncorrelated,
then
are totally uncorrelated,
then ![]() and they are orthogonal to each other.
and they are orthogonal to each other.
If these conditions are true, then the response of the network to ![]() will be
will be

Although two patterns ![]() and
and ![]() don't have causal
relationship (as
don't have causal
relationship (as ![]() is caused by another pattern
is caused by another pattern ![]() ), if they
always appear simultaneously, an association relationship can be
established in the Hebbian network.
), if they
always appear simultaneously, an association relationship can be
established in the Hebbian network.
{kind=link}