Next: About this document ... Up: Support Vector Machines (SVM) Previous: Support Vector Machine
The algorithm above converges only for linearly separable data. If
the data set is not linearly separable, we can map the the samples
![]() into a feature space of higher or even infinite dimensional
space:
into a feature space of higher or even infinite dimensional
space:



Definition: A kernel is a function that takes two vectors ![]() and
and ![]() as arguments and returns the value of the inner product of
their images
as arguments and returns the value of the inner product of
their images
![]() and
and
![]() :
:

The learning algorithm in the kernel space can be obtained by replacing all inner products in the learning algorithm in the original space with the kernels:

Example 1: linear kernel
Assume
![]() ,
,
![]() ,
,

Example 2: polynomial kernels
Assume
![]() ,
,
![]() ,
,
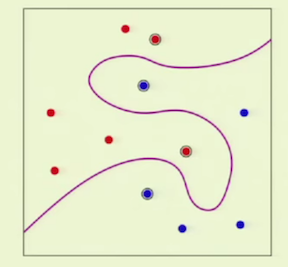
Example 3:

If the two classes are not linearly separable in the original n-D
space of ![]() , they are more likely to be linearly separable in
the higher dimensional space of
, they are more likely to be linearly separable in
the higher dimensional space of ![]() . When mapped back to the
original space, the two classes can be completely separated.
. When mapped back to the
original space, the two classes can be completely separated.
Caltech machine learning course