Next: Competitive Learning Networks Up: Introduction to Neural Networks Previous: The AdaBoost Algorithm
The radial basis function (RBF) networks are inspired by biological neural systems, in which neurons are organized hierarchically in various pathways for signal processing, and they are tuned to respond selectively to different features/characteristics of the stimuli within their respective fields. In general, neurons in higher layers have larger receptive fields and they selectively respond to more global and complex patterns.
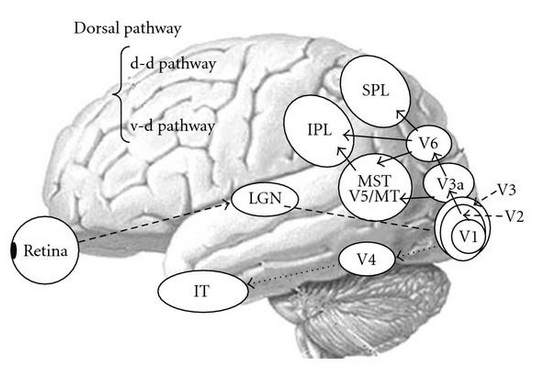
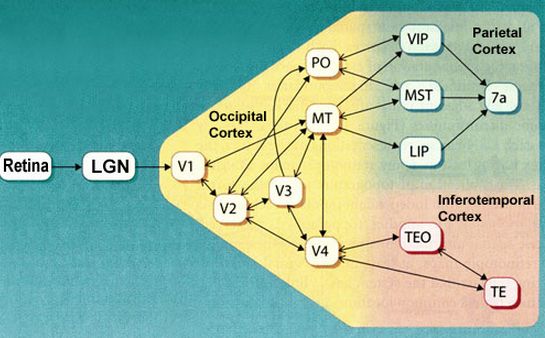
For example, neurons at different levels along the visual pathway respond selectively to different types of visual stimuli:
The tuning curves, the local response functions, of these neurons are typically Gaussian, i.e., the level of response is reduced when the stimulus becomes less similar to what the cell is most sensitive and responsive to (the most preferred).
These Gaussian-like functions can also be treated as a set of basis functions (not necessarily orthogonal and over-complete) that span the space of all input patters. Based on such local features represented by the nodes, a node in a higher layer can be trained to selectively so that it is specialized to respond to some specific patterns/objects (e.g., “grandmother cell”), based on the outputs of the nodes in the lower layer.
Applications:
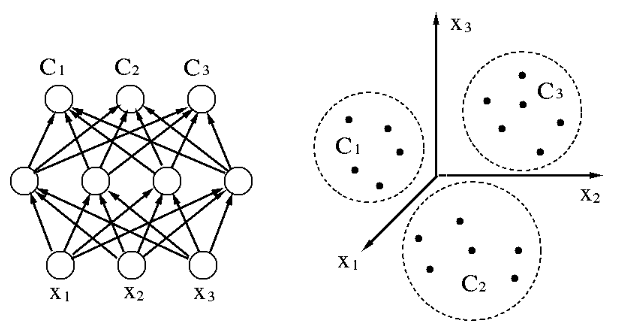
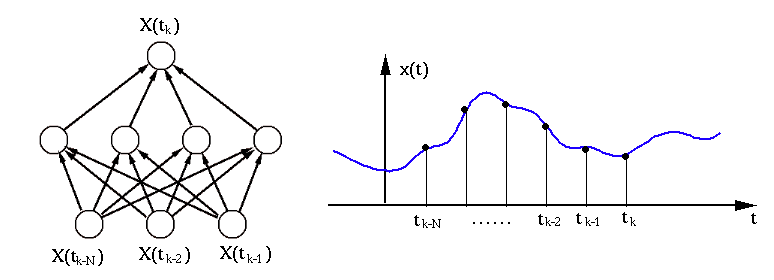
As seen in the examples above, an RBF network is typically composed of three
layers, the input layer composed of ![]() nodes that receive the input signal
nodes that receive the input signal
![]() , the hidden layer composed of
, the hidden layer composed of ![]() nodes that simulate the neurons
with selective tuning to different features in the input, and the output
layer composed of
nodes that simulate the neurons
with selective tuning to different features in the input, and the output
layer composed of ![]() nodes simulating the neurons at some higher level that
respond to features at a more global level, based on the output from the
hidden layer representing different features at a local level. (This could
be considered as a model for the visual signal processing in the pathway
nodes simulating the neurons at some higher level that
respond to features at a more global level, based on the output from the
hidden layer representing different features at a local level. (This could
be considered as a model for the visual signal processing in the pathway
![]() .)
.)
Upon receiving an input pattern vector ![]() , the jth hidden node reaches
the activation level:
, the jth hidden node reaches
the activation level:
![$\displaystyle h_j({\bf x})=exp[-({\bf x}-{\bf c}_j)^T {\bf\Sigma}_j^{-1}({\bf x}-{\bf c}_j)]
$](img98.svg)
![$\displaystyle h_j({\bf x})=exp[-({\bf x}-{\bf c}_j)^2/\sigma^2]
$](img99.svg)
In the output layer, each node receives the outputs of all nodes in the hidden layer, and the output of the ith output node is the linear combination of the net activation:
![$\displaystyle f_i({\bf x})=\sum_{j=1}^L w_{ij} h_j({\bf x})
=\sum_{j=1}^L w_{ij}\; exp[-({\bf x}-{\bf c}_j)^T {\bf\Sigma}_j^{-1}({\bf x}-{\bf c}_j)]
$](img100.svg)
Learning Rules
Through the training stage, various system parameters of an RBF network will
be obtained, including the ![]() and
and ![]() (
(![]() )
of the
)
of the ![]() nodes of the hidden layer, as well as the weights
nodes of the hidden layer, as well as the weights ![]() (
(
![]() ) for the
) for the ![]() nodes of the output layer, each
fully connected to all
nodes of the output layer, each
fully connected to all ![]() hidden nodes.
hidden nodes.
The centers ![]() (
(![]() ) of the
) of the ![]() nodes of the hidden
layer can be obtained in different ways, so long as the entire data space
can be well represented.
nodes of the hidden
layer can be obtained in different ways, so long as the entire data space
can be well represented.
Once the parameters ![]() and
and ![]() are available, we
can concentrate on finding the weights
are available, we
can concentrate on finding the weights ![]() of the output layer, based on
the given training data containing
of the output layer, based on
the given training data containing ![]() data points
data points
![]() , i.e., we need to solve the equation system for the
, i.e., we need to solve the equation system for the ![]() weights
weights ![]() (
(![]() ):
):


![$\displaystyle {\bf H}=\left[\begin{array}{ccc}h_1({\bf x}_1)&\cdots&h_1({\bf x}...
...dots \\
h_L({\bf x}_1)&\cdots&h_L({\bf x}_K) \end{array}\right]_{L\times K}
$](img103.svg)
![$\displaystyle MSE=\vert\vert{\bf y}-\hat{\bf y}\vert\vert^2=\vert\vert{\bf y}-{...
...x}_k) ]^2
=\sum_{k=1}^K \left[y_k-\sum_{j=1}^L w_j h_j({\bf x}_k)\right]^2
$](img104.svg)

In some cases (e.g., for the model of ![]() to be smooth), it is
desirable for the weights to be small. To achieve this goal, a cost
function can be constructed with an additional term added to the MSE:
to be smooth), it is
desirable for the weights to be small. To achieve this goal, a cost
function can be constructed with an additional term added to the MSE:

