Next: Classical Multidimensional Scaling Up: ch8 Previous: Factor Analysis and Expectation
The method of probabilistic PCA (PPCA) can be considered
as a special case of factor analysis based on the model
 , when the random noise
, when the random noise  is assumed to have an isotropic normal distributions with
covariance matrix
is assumed to have an isotropic normal distributions with
covariance matrix
 . More specially,
if we further let
. More specially,
if we further let
 approach zero, the
iteration of the EM algorithm for the PPCA becomes extremely
simple, as we will see below.
approach zero, the
iteration of the EM algorithm for the PPCA becomes extremely
simple, as we will see below.
Same as in Eqs. (125) and (127) for FA, here
we also have the normal distribution of both  and
:
and
:
 |
(150) |
, same as in Eq. (131):
 |
(151) |
 and
and  as
the model parameter, based on the observed data dataset
as
the model parameter, based on the observed data dataset
![${\bf X}=[{\bf x}_1,\cdots,{\bf x}_N]$](img6.svg) .
.
Now Eqs. (137) through (139) are rewritten as:
 |
(153) |
 |
(154) |
The two steps of the EM algorithm become:
 in Eq. (142) by
in Eq. (142) by
 :
:
![$\displaystyle Q =-\frac{dN}{2}\log\varepsilon-\frac{1}{2\varepsilon}
\sum_{n=1}...
... {\bf x}_n^T{\bf x}_n -2{\bf x}_n^T{\bf Wz}
+{\bf z}^T{\bf W}^T{\bf Wz} \right]$](img571.svg) |
(155) |
and
that maximize the expectation of the log likelihood
 above, by setting the derivative of with respect to the
parameters to zero and solve the resulting equations. For ,
the result is the same as Eq. (145):
where
To find
, we solve the equation
above, by setting the derivative of with respect to the
parameters to zero and solve the resulting equations. For ,
the result is the same as Eq. (145):
where
To find
, we solve the equation
![$\displaystyle \frac{\partial Q}{\partial \varepsilon}
=-\frac{dN}{2\varepsilon}...
...f x}_n^T{\bf x}_n -2{\bf x}_n^T {\bf Wz}
+ {\bf z}^T{\bf W}^T{\bf Wz} \right]=0$](img574.svg) |
(158) |
 .
.
In summary, here are the steps in the EM algorithm for PPCA:
 ;
;
 , find
, find
 and
and
 in Eq. (152), and
in Eq. (152), and
 and
and
 in Eq. (157);
in Eq. (157);
 by evaluating Eqs. (156) and (159);
by evaluating Eqs. (156) and (159);
 by
by
 and return to step 2.
and return to step 2.
Specially, if we further assume
and the latent variables in are deterministic, i.e.,
 . At the limit where
. At the limit where
 ,
,
 is simply a linear combination of the latent variables
in :
is simply a linear combination of the latent variables
in :
with Eq. (81)
 |
(161) |
![${\bf W}=[{\bf w}_1,\cdots,{\bf w}_{d'}]$](img588.svg) for the PPCA are similar to the column vectors of
for the PPCA are similar to the column vectors of  , the
eigenvector matrix of
, the
eigenvector matrix of
 , in the linear PCA, as both of
them can be viewed as the principal directions, an alternative set of
basis vectors that also span the same d-dimensional feature space in
which resides. When is expressed as a linear
combination of these basis vectors, it can be approximated by only
, in the linear PCA, as both of
them can be viewed as the principal directions, an alternative set of
basis vectors that also span the same d-dimensional feature space in
which resides. When is expressed as a linear
combination of these basis vectors, it can be approximated by only
 of the
of the  such basis vectors weighted by the
such basis vectors weighted by the  principal
components in
principal
components in
![${\bf y}=[y_1,\cdots,y_{d'}]^T$](img589.svg) in linear PCA, or the
factors in
in linear PCA, or the
factors in
![${\bf z}=[z_1,\cdots,z_{d'}]^T$](img467.svg) in PPCA.
in PPCA.
Here are the two EM steps for the PPCA:
, Eq. (152) can
be written as:
 |
 |
 |
|
 |
 |
(162) |
 such equations can be written in matrix form as
such equations can be written in matrix form as
![$\displaystyle {\bf Z}=[{\bf z}_1,\cdots,{\bf z}_n]
={\bf W}^T({\bf WW}^T)^{-1}[{\bf x}_1,\cdots,{\bf x}_N]
={\bf W}^T({\bf WW}^T)^{-1}{\bf X}$](img594.svg) |
(163) |
is a
 matrix (), the rank of
the
matrix (), the rank of
the  matrix
matrix
 is at most , i.e., the
inverse of
does not exist and we cannot find
is at most , i.e., the
inverse of
does not exist and we cannot find
 . In
fact the transformation matrix
. In
fact the transformation matrix
 is the
right psedo inverse
of the
matrix , which exists only if
is the
right psedo inverse
of the
matrix , which exists only if  .
.
However, we note that the model
 is an
over-constraned linear system of equations but only
variables in
, and the least-squares
solution that minimizes the squared error
is an
over-constraned linear system of equations but only
variables in
, and the least-squares
solution that minimizes the squared error
 can be found by the
left pseudo inverse
of :
can be found by the
left pseudo inverse
of :
 |
(164) |
![${\bf Z}=[{\bf z}_1,\cdots,{\bf z}_N]$](img413.svg) given all data points in
:
given all data points in
:
 |
(165) |
previously estimated.
 |
|
 |
|
|
![$\displaystyle [{\bf x}_1,\cdots,{\bf x}_N]\left[\begin{array}{c}
{\bf z}_1^T\\ ...
...d{array}\right]\right)^{-1}
={\bf X}{\bf Z}^T({\bf ZZ}^T)^{-1}={\bf X}{\bf Z}^-$](img605.svg) |
(166) |
is uptated based on  found previously
in the E-step. We note that
found previously
in the E-step. We note that
 is the right
pseudo inverse of the
is the right
pseudo inverse of the  matrix , which exists
if
matrix , which exists
if  .
.
Again, as the E-step and M-steps are interdependent on each other,
they need to be carried out iteratively:
| E-step: |  |
|
|
| M-Step: | |
 |
(167) |
 , the FA model
can be expressed as an over-determined matrix
equation
, the FA model
can be expressed as an over-determined matrix
equation
![$\displaystyle {\bf X}_{d\times N}=[{\bf x}_1,\cdots,{\bf x}_N]
={\bf W}_{d\times d'}[{\bf z}_1,\cdots,{\bf z}_N]
={\bf W}_{d\times d'}{\bf Z}_{d'\times N}$](img612.svg) |
(168) |
 |
(169) |
, this equation can be interpreted in two ways:
is available, this is a system of equations
but unknowns in each of the columns of , which
is solved as in the E-step above;
is available, this is a system of equations
but  unknowns in each of the rows of , which
is solved as in the M-step above.
unknowns in each of the rows of , which
is solved as in the M-step above.
 .
.
When compared to the regular PCA method that finds all
eigenvalues and the corresponding eigenvectors all at once by
solving the eigenequation
 ,
the PPCA method only finds the column vectors of matrix
as the basis vectors, as the basis vectors that span
a subspace with much reduced dimensionality but containing the
most essential information in the data. However, unlike the PCA,
the basis vectors in PPCA are not necessarily orthogonal to each
other.
,
the PPCA method only finds the column vectors of matrix
as the basis vectors, as the basis vectors that span
a subspace with much reduced dimensionality but containing the
most essential information in the data. However, unlike the PCA,
the basis vectors in PPCA are not necessarily orthogonal to each
other.
The implementation of the PPCA is extremely simple, as shown
in the Matlab code below. Based on some initialized ,
the EM iteration is composed of the E-step and M-step:
while er>tol
Z=inv(W'*W)*W'*X; % find Z given W in E-step
Wnew=X*Z'*inv(Z*Z'); % find W given Z in M-step
er=norm(Wnew-W); % the LS error
W=Wnew;
end
Example 1:
The figure below shows the first few iterations of the PPCA based
on the EM method presented above, for a set of  data
points in
the
data
points in
the  dimensional
space. The stright line in the plots indicates the direction of
dimensional
space. The stright line in the plots indicates the direction of
 , which is initially set along a random direction, but
quickly approaches the direction corresponding to the principal
component obtained by the PCA method, along which the data points
are most widely spread.
, which is initially set along a random direction, but
quickly approaches the direction corresponding to the principal
component obtained by the PCA method, along which the data points
are most widely spread.
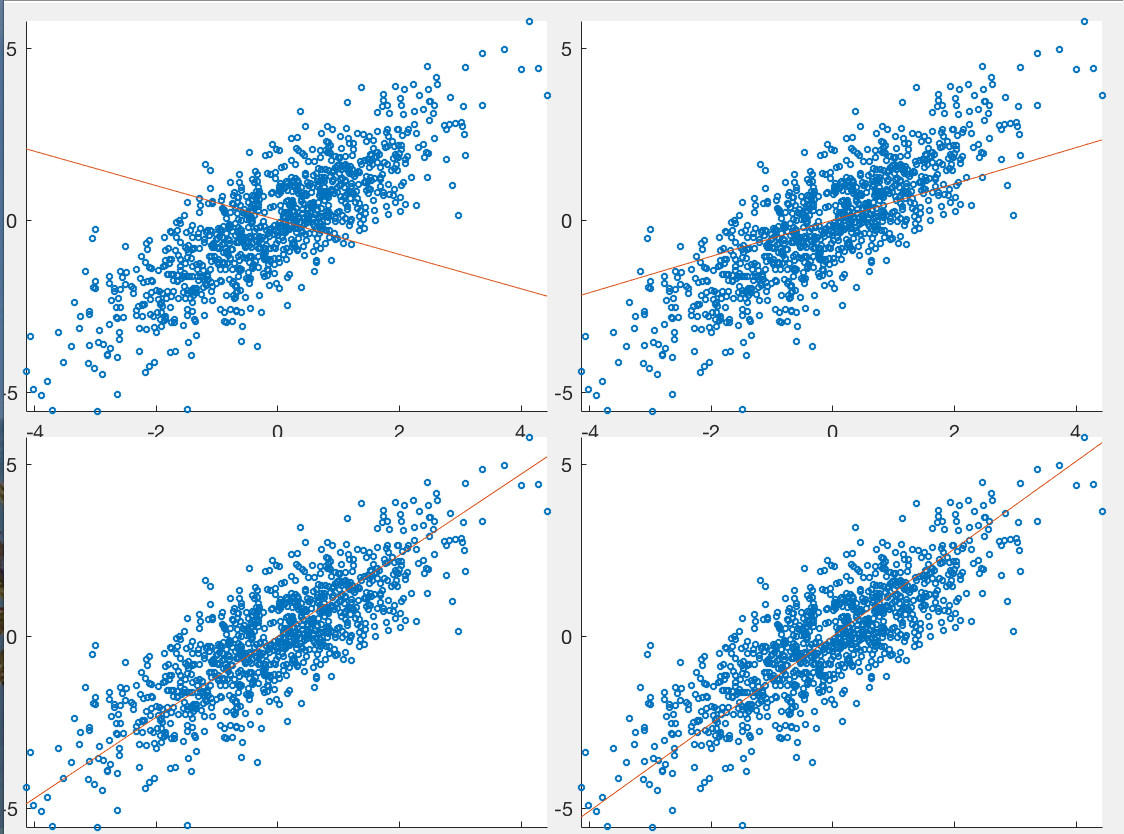
Example 2:
The figure below shows the first few iterations of the PPCA EM
algorithm for a set of data points in  dimensional space.
The stright lines in the plots indicates the direction of the
principal components when
dimensional space.
The stright lines in the plots indicates the direction of the
principal components when  .
.
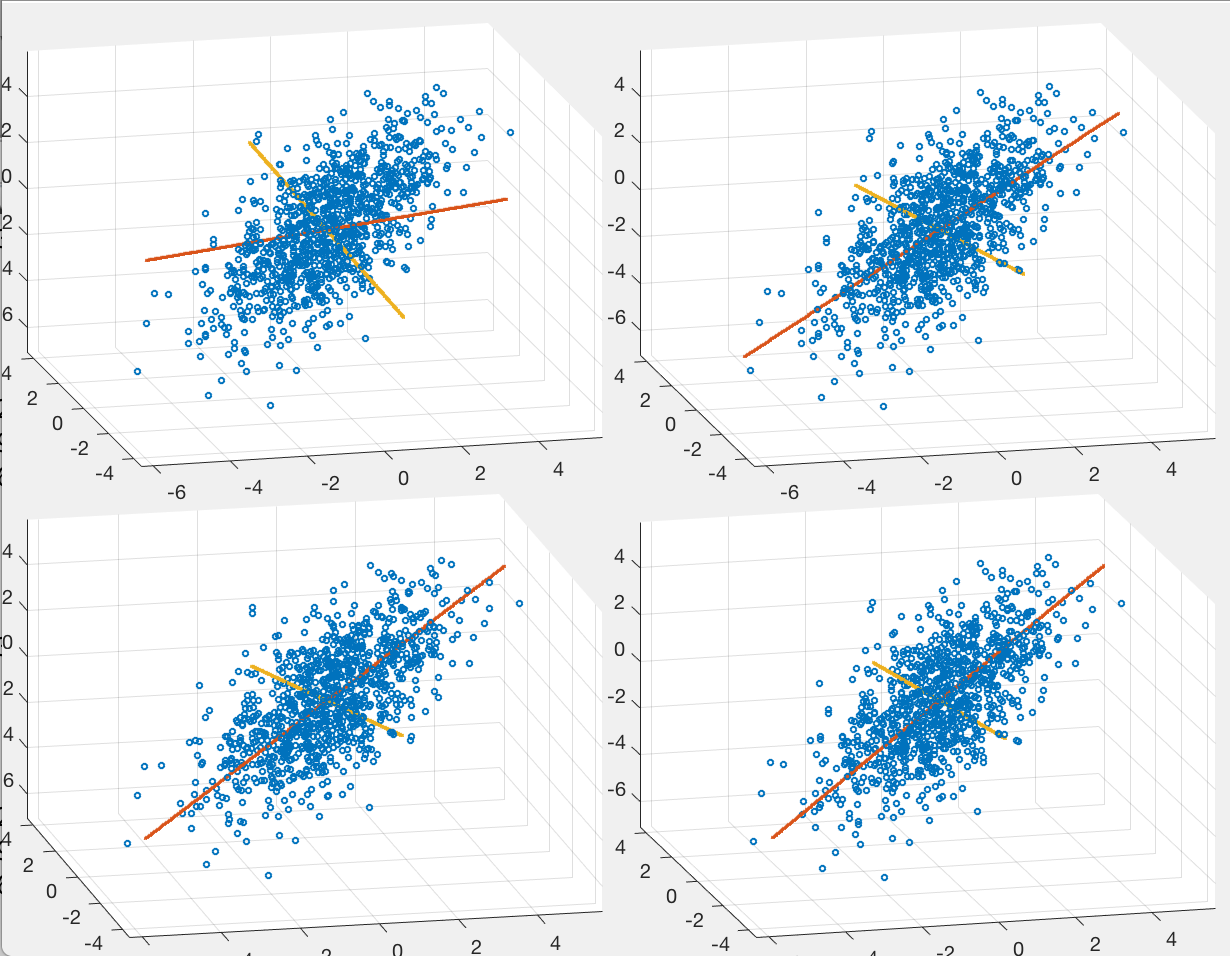
Example 3:
The figure below shows the visualization of the dataset for
the hand-written numbers from 0 to 9, containing 2240 data
points in a 256-D space, but now linearly mapped to a 3-D
space spanned by  factors found by the PPCA method.
factors found by the PPCA method.


![$\displaystyle {\bf W}_{new}=\left(\sum_{n=1}^N {\bf x}_n E_{z\vert x_n}[{\bf z}^T]\right)\;
\left(\sum_{n=1}^N E_{z\vert x_n}[{\bf zz}^T] \right)^{-1}$](img572.svg)
![$\displaystyle \left\{\begin{array}{lll}
E_{z\vert x_n}[{\bf z}]&=&{\bf m}_{z\ve...
...gma}_{z\vert x_n}+{\bf m}_{z\vert x_n}{\bf m}_{z\vert x_n}^T
\end{array}\right.$](img573.svg)

![$\displaystyle \frac{1}{dN} \sum_{n=1}^N \left[
{\bf x}_n^T{\bf x}_n -2{\bf x}_n...
...\vert x_n}({\bf z})
+ tr ({\bf W}^T E_{z\vert x_n} ({\bf zz}^T){\bf W}) \right]$](img576.svg)
![$\displaystyle \frac{1}{dN} \sum_{n=1}^N \left[
\vert\vert{\bf x}_n\vert\vert^2 ...
...T){\bf W}^T{\bf x}_n
+ tr (E_{z\vert x_n} ({\bf zz}^T){\bf W}^T{\bf W}) \right]$](img577.svg)
![$\displaystyle {\bf x}={\bf Wz}+\varepsilon{\bf I}
\;\;\stackrel{\varepsilon\rig...
...{array}{c}z_1\\ \vdots\\ z_{d'}\end{array}\right]
=\sum_{i=1}^{d'} z_i{\bf w}_i$](img586.svg)