Next: Linear Least Squares Regression Up: Regression Analysis and Classification Previous: Regression Analysis and Classification
The goal of regression analysis is to model the relatiionship
between a dependent variable  , typically a scalor, and a set
of independent variables or predictors
, typically a scalor, and a set
of independent variables or predictors
 ,
represented as a column vector
,
represented as a column vector
![${\bf x}=[x_1,\cdots,x_d]^T$](img491.svg) in a
d-dimensional space. Here both and the components in
in a
d-dimensional space. Here both and the components in  take numerical values.
take numerical values.
Regression can be considered as a supervised learning method that
learns the essential relationship between the dependent and independent
variables, based on the training dataset containing  observed data
samples
observed data
samples
 |
(99) |
 is labeld by
is labeld by  , the ground truth
value corresponding to . We also represent the training set
as
, the ground truth
value corresponding to . We also represent the training set
as
 in terms of a
in terms of a  matrix
matrix
![${\bf X}=[{\bf x}_1,\cdots,{\bf x}_N]$](img498.svg) containing the sample
points and an N-dimensional vector
containing the sample
points and an N-dimensional vector
![${\bf y}=[y_1,\cdots,y_N]^T$](img499.svg) for
their labelings.
for
their labelings.
More specifically, a regression algorithm is to model the relationship
between independent variable and the dependent variable
by a hypothesized regression function
 , containing a set of parameters
symbolically denoted by
, containing a set of parameters
symbolically denoted by
![${\bf\theta}=[\theta_1,\cdots,\theta_M]^T$](img501.svg) .
Geometrically this regression function
.
Geometrically this regression function
 represents curve
if
represents curve
if  , a surface if
, a surface if  or a hypersurface if
or a hypersurface if  .
.
Typically, the form of the function
 (e.g.,
linear, polynomial, or exponential) is determined is assumed to be
known based on prior knowledge, while the parameter
(e.g.,
linear, polynomial, or exponential) is determined is assumed to be
known based on prior knowledge, while the parameter
 is
to be estimated by the regression algorithm, so that the predicted
value
is
to be estimated by the regression algorithm, so that the predicted
value  is to match the ground truth optimally is some
sense, but not affected by the inevitable observation noise in the
data. In other words, a regression algorithm should neither
overfit nor underfit the data.
is to match the ground truth optimally is some
sense, but not affected by the inevitable observation noise in the
data. In other words, a regression algorithm should neither
overfit nor underfit the data.
Regression analysis can also be interpreted as
system modeling/identification, when the independent variable
and the dependent variable are treated respectively as
the input (stimuli) and output (responses) of a system, the behavior
of which is described by the relationship between such input and
output modeled by the regression function
 .
.
Regression analysis is also closely related to
pattern recognition/classification, when the independent
vector variable in the data is treated as a set of
features that characterize a pattern or opject of
interest, and the corresponding dependent variable is treated
as a categorical label indicating to which of a set of  classes
classes
 a pattern belongs. In this case,
the modeling process of the relationship between and
becomes supervised pattern classification or recognition, to be
discussed in a later chapter.
a pattern belongs. In this case,
the modeling process of the relationship between and
becomes supervised pattern classification or recognition, to be
discussed in a later chapter.
In general the regression problem can be addressed based on
different philosophical viewpoints. In the frequentist
point of view, the unknown model parameters in
are fixed deterministic variables that can be estimated based
on the observed data, and a typical method based on this
viewpoint is the least squares method.
Alternatively, in the Bayesian inferenceoint of view, the model parameters in
are random
variables. Their prior probability distribution
 before any data are observed can be estimated based on some prior
knowledge. If no such prior knowledge is available,
before any data are observed can be estimated based on some prior
knowledge. If no such prior knowledge is available,
 can be simply a uniform distribution, i.e., all possible values
of
can be simply a uniform distribution, i.e., all possible values
of  are equally likely. Once the training set
are equally likely. Once the training set  becomes available, we can further get the posterior probability
based on Bayes' theorem:
becomes available, we can further get the posterior probability
based on Bayes' theorem:
of
such a regression model based Bayesian inference is no longer
a deterministic value, but a random variable described by its
mean and variance.
Based on either of these two viewpoints, different regression
algorithms can be used to find the parameters
for the model function
to
fit the observed dataset
 in
some optimal way based on different criteria, as shown below.
in
some optimal way based on different criteria, as shown below.
This frequentist method measures how well the regression
function models the training data by the residual
defined as
 , defined
as the difference between the model prediction
, defined
as the difference between the model prediction
 and the ground
truth labeling value corresponding to , for each
of the data points in the observed data:
and the ground
truth labeling value corresponding to , for each
of the data points in the observed data:
![$\displaystyle {\bf r}({\bf\theta})
=\left[\begin{array}{c}r_1\\ \vdots\\ r_N\en...
...\ \vdots\\
y_N-f({\bf x}_N,{\bf\theta})\end{array}\right]
={\bf y}-\hat{\bf y}$](img519.svg) |
(101) |
 ,
and we can find the
,
and we can find the  model parameters by solving this equation
system of equations of unknowns in
. However,
as in general
model parameters by solving this equation
system of equations of unknowns in
. However,
as in general  , this system is overconstrained without a
solution. We therefore can only use least squares method to find
the optimal solution that minimizes the
sum of squared error (SSE):
Here the coefficent
, this system is overconstrained without a
solution. We therefore can only use least squares method to find
the optimal solution that minimizes the
sum of squared error (SSE):
Here the coefficent  is included for mathematical
convenience. When divide by the total number of samples ,
this SSE becomes the average of all squared errors, and
the error becomes the mean squared error (MSE).
is included for mathematical
convenience. When divide by the total number of samples ,
this SSE becomes the average of all squared errors, and
the error becomes the mean squared error (MSE).
This Bayesian inference method measures how well the
regression function models the training data
 in terms of the
likelihood
in terms of the
likelihood
of the model parameter
based on the observed dataset
,
which is proportional to the conditional probability of
 given
:
given
:
 |
(103) |
can be found as those that maximize the likelihood function, or
equivalently the log likelihood function, for computational
convenience:
 |
(104) |
 is assumed
to be zero-mean random variable with a normal probability density
function (pdf):
is assumed
to be zero-mean random variable with a normal probability density
function (pdf):
 |
 |
 |
|
|
 |
(105) |
 only, such an assumption
of normal pdf imposes least amount of constraint and thereby
minimum bias.
only, such an assumption
of normal pdf imposes least amount of constraint and thereby
minimum bias.
The zero-mean pdf of
can also be
considered as the pdf of with mean
,
the conditional pdf
 of given
as well as , based on the assumption
that and are indeed related by
of given
as well as , based on the assumption
that and are indeed related by
 . Then we can find the likelihood
of the model parameter
given the samples
in in the training set, all assumed to be
independent and identically distributed (i.i.d.):
. Then we can find the likelihood
of the model parameter
given the samples
in in the training set, all assumed to be
independent and identically distributed (i.i.d.):
 in the second
term are both independent of
in the second
term are both independent of  and can therefore be
dropped. We note that this result is equivalent to that in
Eq. (#_#> by either maximizing the likelihood
, or equivalently minimizing the
sum of squares error
and can therefore be
dropped. We note that this result is equivalent to that in
Eq. (#_#> by either maximizing the likelihood
, or equivalently minimizing the
sum of squares error
 .
.
This is also a Bayesian inference method that measures how
well the regression function models the training data by the
posterior probability of the parameter
given
in Eq. (100), proportional to the product
of the likelihood
 and the prior
. If no prior knowledge about
is available, then
is a uniform
distribution, then MAP is equivalent to MLE. However, if certain
prior knowledge regarding
does exist, and the
prior is not uniform, then the posterior better characterizes
than the likelihood and MAP may produce better
result than MLE.
and the prior
. If no prior knowledge about
is available, then
is a uniform
distribution, then MAP is equivalent to MLE. However, if certain
prior knowledge regarding
does exist, and the
prior is not uniform, then the posterior better characterizes
than the likelihood and MAP may produce better
result than MLE.
We see that regression analysis can be treated as an optimization problem, in which either the sum of squares error is minimized or the likelihood function is maximized. Also, the optimization problem is in general over-determined, as there are typically many more observed data points in the training data than the number of unknown parameters. Algorithms based on these different methods are to be considered in detail in later sections in this chapter.
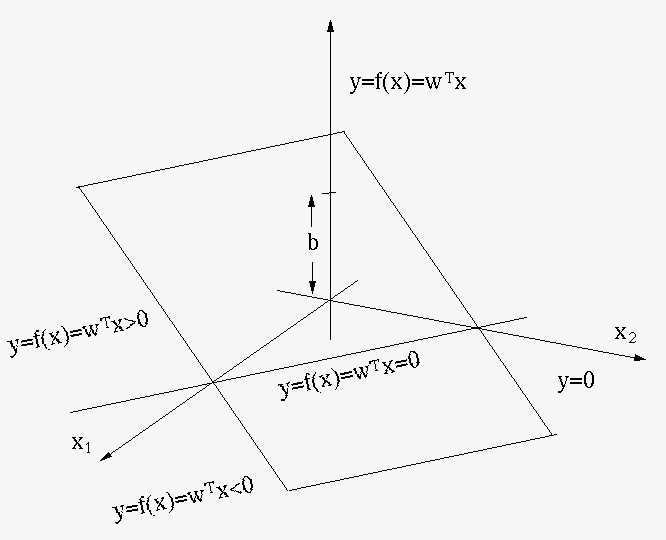
We further note that regression analysis can be considered as a
binary classification, when the regression function
,
as a hypersurface in a  dimensional space spanned by
dimensional space spanned by
 , is thresholded by a constant
, is thresholded by a constant  (e.g.,
(e.g.,
 ). The resulting equation
). The resulting equation
 defines a hypersurface
in the
defines a hypersurface
in the  dimensional space spanned by
, which
partitions the space into two parts in such a way that all points on
one side of the hypersurface satisfy
dimensional space spanned by
, which
partitions the space into two parts in such a way that all points on
one side of the hypersurface satisfy
 , while all points
on the other side satisfy
, while all points
on the other side satisfy
 . In other words, the regression
function is a binary classifier that separates every point
in the dimensional space into two classes
. In other words, the regression
function is a binary classifier that separates every point
in the dimensional space into two classes  and
and  , depending
on whether
is greater or smaller than C. Now each
corresponding to in the given dataset
can be treated as a label indicating
belong to class if
, depending
on whether
is greater or smaller than C. Now each
corresponding to in the given dataset
can be treated as a label indicating
belong to class if  , or if
, or if  , and
the regression problem becomes a binary classification problem.
, and
the regression problem becomes a binary classification problem.






![$\displaystyle -\log L({\bf\theta}\vert{\bf X},{\bf y})
=-\log\left[\prod_{n=1}^...
...}}\exp
\left(-\frac{(y_n-f({\bf x}_n,{\bf\theta}) )^2}{2\sigma^2}\right)\right]$](img540.svg)
![$\displaystyle -\sum_{n=1}^N \log\left[\frac{1}{\sqrt{2\pi\sigma^2}}\exp
\left(-\frac{(y_n-f({\bf x},{\bf\theta}))^2}{2\sigma^2}\right)\right]$](img541.svg)
