A generic data modeling problem can be formulated as the following: given
a set of  pairs of observed data points
pairs of observed data points
 ,
find a model
,
find a model
 to fit the relationship between the two
variables
to fit the relationship between the two
variables  and
and  :
:
 |
(17) |
where
![${\bf a}=[a_1,\cdots,a_M]^T$](img71.svg) is a set of
is a set of  parameters. We
assume there are more data points than the number of parameters,
i.e.,
parameters. We
assume there are more data points than the number of parameters,
i.e.,  . In practice, is much greater than . The error
of the model for the ith data point is
. In practice, is much greater than . The error
of the model for the ith data point is
 |
(18) |
Given the assumed function
, the goal is to find
the optimal parameters for the model to best fit the data set, so
that the following least squares (LS) error is minimized:
![$\displaystyle \varepsilon({\bf a})=\sum_{i=1}^Ne_i^2=\sum_{i=1}^N[y_i-f(x_i,{\bf a})]^2$](img75.svg) |
(19) |
If the data points  can be assumed to be normally distributed
random variables, then the LS-error is a random variable with
chi-squared
can be assumed to be normally distributed
random variables, then the LS-error is a random variable with
chi-squared  -distribution of
-distribution of  degrees of freedom.
degrees of freedom.
For the LS-error
 to be minimized, the optimal
parameters
to be minimized, the optimal
parameters
 need to satisfy the following equations:
need to satisfy the following equations:
where
 .
We define
.
We define
![${\bf y}=[y_1,\cdots,y_N]^T$](img8.svg) and
and
![$\displaystyle {\bf f}({\bf a})=\left[\begin{array}{c}f(x_1,{\bf a})\\ \vdots\\
f(x_N,{\bf a})\end{array}\right]_{N\times 1}$](img85.svg) |
(21) |
then the equations above can be written in vector form as the gradiant
of
:
 |
(22) |
where
 is an N-D vector, and
is an N-D vector, and  is the
is the
 Jacobian matrix
Jacobian matrix
![$\displaystyle {\bf J}=\frac{d {\bf f}({\bf a})}{d{\bf a}}
=\left[\begin{array}{...
...a_1 &\cdots&
\partial f(x_N,{\bf a})/\partial a_M\end{array}\right]_{N\times M}$](img90.svg) |
(23) |
The optimal parameters can be obtained by solving a set of N nonlinear
equations:
 |
(24) |
We first consider the special case of a linear model
 ,
with the LS error:
,
with the LS error:
![$\displaystyle \varepsilon=\sum_{i=1}^N[y_i-f(x_i,a,b)]^2 =\sum_{i=1}^N[y_i-(a+bx_i)]^2$](img93.svg) |
(25) |
The two parameters  and
and  can be found by solving these two equations:
can be found by solving these two equations:
![$\displaystyle \left\{ \begin{array}{l}
\frac{\partial \varepsilon}{\partial a}=...
...on}{\partial b}=-2\left[\sum_{i=1}^N(y_i-a-bx_i)x_i\right]=0
\end{array}\right.$](img96.svg) |
(26) |
i.e.,
 |
(27) |
Dividing both sides by , we get
 |
(28) |
where  and
and  are repectively the estimated means of
and :
are repectively the estimated means of
and :
 |
(29) |
Substituting the first equation
 into the second,
we get
into the second,
we get
 |
(30) |
Solving for we get
 |
(31) |
where
 and
and
 are the estimated variance
of and the estimated covariance of and , respectively:
are the estimated variance
of and the estimated covariance of and , respectively:
 |
(32) |
Now we get
 |
(33) |
We next consider solving the least squares problems for nonlinear
multi-variable models by the Gauss-Newton algorithm. Recall that to
model the observed dataset
 by some
model
by some
model
 , we need to find the parameters in
, we need to find the parameters in  that minimizes the squared error in Eq. (19), by solving
the following equation (Eq. (24)):
that minimizes the squared error in Eq. (19), by solving
the following equation (Eq. (24)):
|
(34) |
This nonlinear equation system can be solved iteratively based on
some initial guess  :
:
 |
(35) |
To find the increment
 in the iteration, we consider the first two terms of the Taylor
expansion of the function
in the iteration, we consider the first two terms of the Taylor
expansion of the function
 :
:
 |
(36) |
where  is the Jacobian matrix. Substituting
this expression for
is the Jacobian matrix. Substituting
this expression for
 into Eq. (34), we get
into Eq. (34), we get
 |
(37) |
i.e.,
 |
(38) |
Solving for
 we get
we get
 |
(39) |
where
 is the pseudo
inverse of . Now the iteration becomes:
is the pseudo
inverse of . Now the iteration becomes:
 |
(40) |
Comparing this with the iteration used in
Newton's method
for solving a
multivariate non-linear equation system
 :
:
 |
(41) |
we see that the Gauss-Newton algorithm is essentially solving an
over-constrained nonlinear equation system
 .
The optimal solution
.
The optimal solution  will minimize
will minimize
 .
.
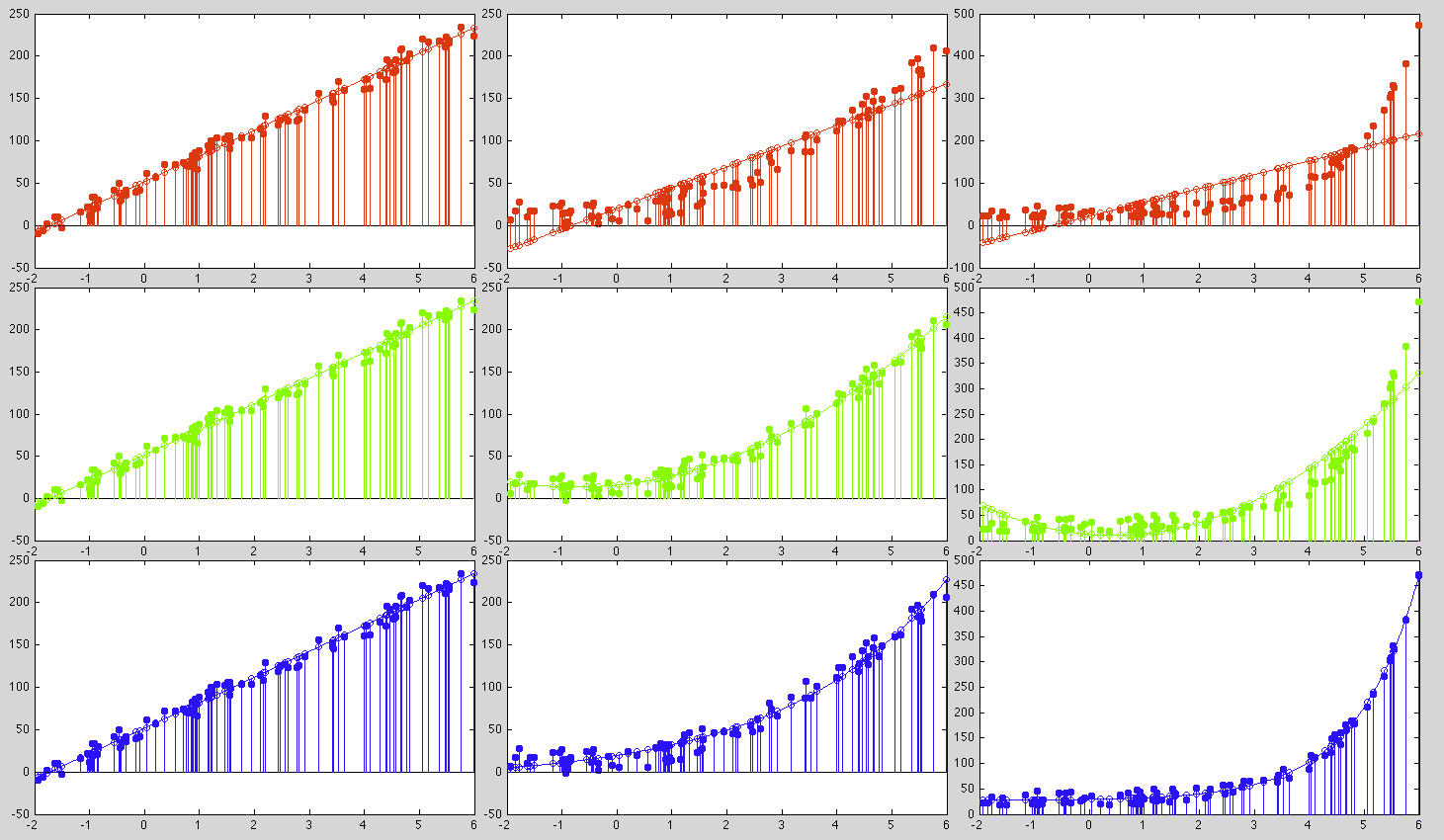
Example
Three sets of data (shown as the solid dots in the three columns in
the plots below) are fitted by three different models (shown as the
open circles in the plots):
- Linear model:
 |
(42) |
- quadratic model:
 |
(43) |
- Exponential model:
 |
(44) |
These are the parameters for the three models to fit each of the three
data sets:
 |
(45) |
We see that the first data set can be fitted by all three models equally
well with similar error (when
 in model 2, it is approximately
a linear functions), the second dataset can be well fitted by either the
second or the third model, while the third dataset can only be fitted
by the third exponential model.
in model 2, it is approximately
a linear functions), the second dataset can be well fitted by either the
second or the third model, while the third dataset can only be fitted
by the third exponential model.


![$\displaystyle \frac{\partial}{\partial a_j}\sum_{i=1}^N \left[y_i-f(x_i,{\bf a}...
...2\sum_{i=1}^N [y_i-f(x_i,{\bf a})] \frac{\partial f(x_i,{\bf a})}{\partial a_j}$](img82.svg)
![$\displaystyle -2\sum_{i=1}^N [y_i-f(x_i,{\bf a})] J_{ij}=0,\;\;\;\;\;(j=1,\cdots,M)$](img83.svg)