Consider the a general constrained optimization problem:
 |
(237) |
By introducing slack variables
 , all inequality
constraints can be converted into equality constraints:
, all inequality
constraints can be converted into equality constraints:
 |
(238) |
which can then be combined with the equality constraints and still
denoted by
 , while the slack variables
, while the slack variables
 are also combined with the original variables and still
denoted by
are also combined with the original variables and still
denoted by  . We assume there are in total
. We assume there are in total  equality
constraints and
equality
constraints and  variables. Now the optimization problem can be
reformulated as:
variables. Now the optimization problem can be
reformulated as:
 |
(239) |
The Lagrangian is
 |
(240) |
The KKT conditions are
 |
(241) |
where
 ,
,
 ,
and
,
and
 is the Jacobian matrix of
is the Jacobian matrix of
 :
:
![$\displaystyle {\bf X}=\left[\begin{array}{ccc}x_1&\cdots&0\\
\vdots&\ddots&\vd...
...al x_1}&\cdots&
\frac{\partial h_m}{\partial x_n}\end{array}\right]_{M\times N}$](img1023.svg) |
(242) |
To simplify the problem, the non-negativity constraints can be removed
by introducing an indicator function:
 |
(243) |
which, when used as a cost function, penalizes any violation of the
non-negativity constraint  . Now the optimization problem can
be reformulated as shown below without the non-negative constants
. Now the optimization problem can
be reformulated as shown below without the non-negative constants
 :
:
 |
(244) |
However, as the indicator function is not smooth and therefore not
differentiable, it is approximated by the logarithmic barrier function
which approaches  when the parameter
when the parameter  approaches infinity:
approaches infinity:
 |
(245) |
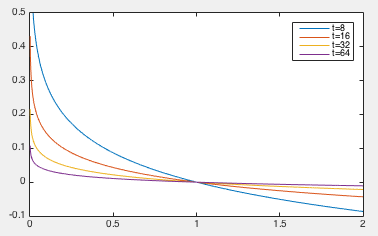
Now the optimization problem can be written as:
 |
(246) |
The Lagrangian is:
 |
(247) |
and its gradient is:
 |
(248) |
We define
 i.e. i.e. |
(249) |
and combine this equation with the KKT conditions of the new
optimization problem to get
 |
(250) |
The third condition is actually from the definition of  given above, but here it is labeled as complementarity, so that
these conditions can be compared with the KKT conditions of the
original problem. We see that the two sets of KKT conditions are
similar to each other, with the following differences:
given above, but here it is labeled as complementarity, so that
these conditions can be compared with the KKT conditions of the
original problem. We see that the two sets of KKT conditions are
similar to each other, with the following differences:
- The non-negativity
in the primal feasibility
of the original KKT is dropped;
- Consequently the inequality
 in the dual
feasibility of the original KKT conditions is also dropped;
in the dual
feasibility of the original KKT conditions is also dropped;
- There is an extra term
 in complementarity which
will vanish when
in complementarity which
will vanish when
 .
.
The optimal solution that minimizes the objective function
 can be found by solving the simultaneous equations in the modified
KKT conditions (with no inequalities) given above. To do so, we first
express the equations in the KKT conditions above as a nonlinear
equation system
can be found by solving the simultaneous equations in the modified
KKT conditions (with no inequalities) given above. To do so, we first
express the equations in the KKT conditions above as a nonlinear
equation system
 , and
find its Jacobian matrix
, and
find its Jacobian matrix
 composed of the partial
derivatives of the function
composed of the partial
derivatives of the function
 with respect to each of the three variables ,
with respect to each of the three variables ,
 ,
and :
,
and :
![$\displaystyle {\bf F}({\bf x},{\bf\lambda},{\bf\mu})=\left[ \begin{array}{c}
{\...
... h}({\bf x}) & {\bf0} & {\bf0} \\
{\bf M} & {\bf0} & {\bf X}\end{array}\right]$](img1042.svg) |
(251) |
where
is symmetric as the Hessian matrices  and
and
 are symmetric.
are symmetric.
We can now use the
Newton-Raphson method
to find the solution of the nonlinear equation
iteratively:
![$\displaystyle \left[\begin{array}{c}{\bf x}_{n+1}\\ {\bf\lambda}_{n+1}\\
{\bf\...
...{c}\delta{\bf x}_n\\ \delta{\bf\lambda}_n\\
\delta{\bf\mu}_n\end{array}\right]$](img1047.svg) |
(253) |
where  is a parameter that controls the step size and
is a parameter that controls the step size and
![$[\delta{\bf x}_n,\delta{\bf\lambda}_n,\delta{\bf\mu}_n]^T$](img1048.svg) is the
search direction (Newton direction), which can be found by
solving the following equation:
is the
search direction (Newton direction), which can be found by
solving the following equation:
To get the initial values for the iteration, we first find any point
inside the feasible region  and then
and then
 ,
based on which we further find
,
based on which we further find
 by solving the first
equation in the KKT conditions in Eq. (250).
by solving the first
equation in the KKT conditions in Eq. (250).
Actually this equation system above can be separated into two
subsystems, which are easier to solve. Pre-multiplying
 to the third equation:
to the third equation:
 |
(255) |
we get
 |
(256) |
Adding this to the first equation:
 |
(257) |
we get
 |
(258) |
Combining this equation with the second one, we get an equation system
of two vector variables
 and
and
 with
symmetric coefficient matrix:
with
symmetric coefficient matrix:
![$\displaystyle \left[\begin{array}{ccc}
{\bf W}+{\bf X}^{-1}{\bf M} & {\bf J}^T_...
..._{\bf x}L({\bf x},{\bf\lambda},{\bf\mu})\\
{\bf h}({\bf x})
\end{array}\right]$](img1060.svg) |
(259) |
Solving this equation system we get
and
,
and we can further find
 by solving the third equation
by solving the third equation
 |
(260) |
to get
 |
(261) |
We now consider the two special cases of linear and quadratic
programming:
- Linear programming:
 |
(262) |
We have
The Lagrangian is
 |
(263) |
The KKT conditions are:
The search direction of the iteration can be found by solving the
this equation system:
![$\displaystyle \left[\begin{array}{ccc}
{\bf0} & {\bf A}^T & -{\bf I}\\
{\bf A}...
...f\lambda}-{\bf\mu}\\
{\bf Ax}-{\bf b}\\ {\bf XM1}-{\bf 1}/t
\end{array}\right]$](img1070.svg) |
(264) |
By solving the equation
 we get the initial value
. The Matlab code for the interior
point method for the LP problem is listed below:
we get the initial value
. The Matlab code for the interior
point method for the LP problem is listed below:
function x=InterierPointLP(A,c,b,x)
% given A,b,c of the LP problem and inital value of x,
% find optimal solution x that minimizes c'*x
[m n]=size(A); % m constraints, n variables
z1=zeros(n);
z2=zeros(m); % zero matrices in coefficient matrix
z3=zeros(m,n);
I=eye(n); % identity matrix in coefficient matrix
y=ones(n,1);
t=9; % initinal value for parameter t
alpha=0.3; % small enough not to exceed boundary
mu=x./t;
lambda=pinv(A')*(mu-c); % initial value of lambda
w=[x; lambda; mu]; % initial values for all three
B=[c+A'*lambda-mu; A*x-b; x.*mu-y/t];
p=[x(1) x(2)]; % initial guess of solution
while norm(B)>10^(-7)
t=t*9; % increase parameter t
X=diag(x);
M=diag(mu);
C=[z1 A' -I; A z2 z3; M z3' X];
B=[c+A'*lambda-mu; A*x-b; x.*mu-y/t];
dw=-inv(C)*B; % find search direction
w=w+alpha*dw; % step forward
x=w(1:n);
lambda=w(n+1:n+m);
mu=w(n+m+1:length(w));
p=[p; x(1), x(2)];
end
scatter(p(:,1),p(:,2)); % plot trajectory of solution
end
Example:
A given linear programming problem shown below is first
converted into the standard form:
or in matrix form:
with
where
 are the slack variables.
are the slack variables.
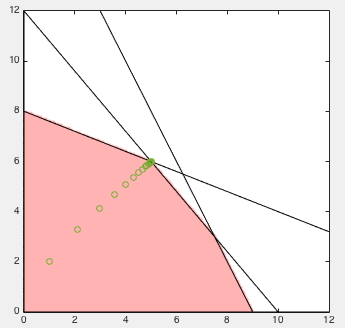
We choose an initial value
![${\bf x}_0=[1,\,2,\,1,\,1,\,1]^T$](img1076.svg) , and
an initial parameter
, and
an initial parameter  , which is scaled up by a factor of
, which is scaled up by a factor of  in each iteration. We also used full Newton step size of
in each iteration. We also used full Newton step size of  .
After 8 iterations, the algorithm converged to the optimal solution
.
After 8 iterations, the algorithm converged to the optimal solution
![${\bf x}^*=[5,\;6]^T$](img1079.svg) corresponding to the maximum function value
corresponding to the maximum function value
 :
:
At the end of the iteration, we also get the values of the slack
variables:
 .
.
- Quadratic programming:
 |
(265) |
We have
The Lagrangian is
 |
(266) |
The KKT conditions are:
The equation system for the Newton-Raphson method is:
![$\displaystyle \left[\begin{array}{ccc}
{\bf Q} & {\bf A}^T & -{\bf I}\\
{\bf A...
...f\lambda}-{\bf\mu}\\
{\bf Ax}-{\bf b}\\ {\bf XM1}-{\bf 1}/t
\end{array}\right]$](img1087.svg) |
(267) |
The Matlab code for the interior point method for the QP problem is
listed below:
function [x mu lambda]=InteriorPointQP(Q,A,c,b,x)
n=length(c); % n variables
m=length(b); % m constraints
z2=zeros(m);
z3=zeros(m,n);
I=eye(n);
y=ones(n,1);
t=9; % initinal value for parameter t
alpha=0.1; % stepsize, small enough not to exceed boundary
mu=x./t;
lambda=pinv(A')*(mu-c-Q*x); % initial value of lambda
w=[x; lambda; mu]; % initial value
B=[Q*x+c+A'*lambda-mu; A*x-b; x.*mu-y/t];
while norm(B)>10^(-7)
t=t*9; % increase parameter t
X=diag(x);
M=diag(mu);
C=[Q A' -I; A z2 z3; M z3' X];
B=[Q*x+c+A'*lambda-mu; A*x-b; x.*mu-y/t];
dw=-inv(C)*B; % find search direction
w=w+alpha*dw; % step forward
x=w(1:n);
lambda=w(n+1:n+m);
mu=w(n+m+1:length(w));
end
end
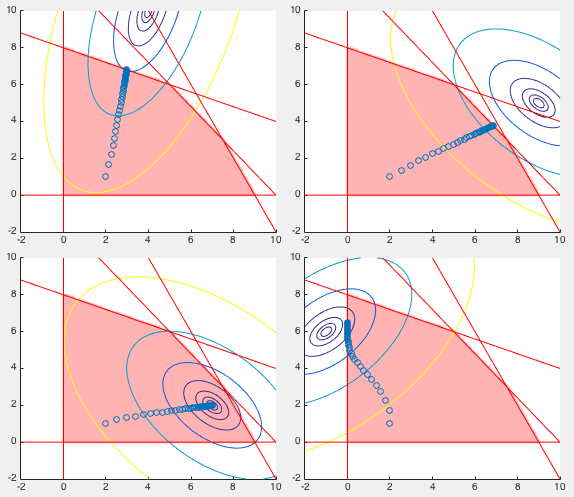
Example:
A 2-D quadratic programming problem shown below is to minimize
four different quadratic functions under the same linear
constraints as the liniear programming problem in the previous
example. In general, the quadratic function is given in the
matrix form:
with following four different sets of function parameters:
As shown in the four panels in the figure below, the iteration of
the interior point algorithm brings the solution from the same
initial position at
![${\bf x}_0=[2,\;1]^T$](img1091.svg) to the final position
for each of the four objective functions
, the optimal
solution, which is on the boundary of the feasible region in all
cases except the third one, where the optimal solution is inside
the feasible region, i.e., the optimization problem is not constrained.
Also note that the trajectories of the solution during the iteration
go straightly from the initial guess to the final optimal solution
by following the negative gradient direction of the quadratic function
in all cases execpt in the last one, where it makes a turn while
approaching the vertical boundary, due obviously to the significantly
greater value of the log barrier function close to the boundary.
to the final position
for each of the four objective functions
, the optimal
solution, which is on the boundary of the feasible region in all
cases except the third one, where the optimal solution is inside
the feasible region, i.e., the optimization problem is not constrained.
Also note that the trajectories of the solution during the iteration
go straightly from the initial guess to the final optimal solution
by following the negative gradient direction of the quadratic function
in all cases execpt in the last one, where it makes a turn while
approaching the vertical boundary, due obviously to the significantly
greater value of the log barrier function close to the boundary.


![$\displaystyle \bigtriangledown_{\bf x}
\left[{\bf g}_f({\bf x})+{\bf J}_{\bf h}^T({\bf x}){\bf\lambda}
-{\bf\mu}\right]$](img1044.svg)
![$\displaystyle \bigtriangledown_{\bf x} {\bf g}_f({\bf x})
-\bigtriangledown_{\b...
...l x_N}\right]^T
={\bf H}_f({\bf x})-\sum_{i=1}^M\lambda_i{\bf H}_{h_i}({\bf x})$](img1045.svg)
![$\displaystyle {\bf J}_{\bf F}({\bf x}_n,{\bf\lambda}_n,{\bf\mu}_n)
\left[\begin...
...c}
\delta{\bf x}_n\\ \delta{\bf\lambda}_n\\ \delta{\bf\mu}_n
\end{array}\right]$](img1049.svg)
![$\displaystyle -{\bf F}({\bf x}_n,{\bf\lambda}_n,{\bf\mu}_n)
=-\left[\begin{arra...
...bda}_n-\mu_n\\
{\bf h}({\bf x}_n)\\ {\bf X_nM_n1}-{\bf 1}/t
\end{array}\right]$](img1050.svg)

 .
.
 .
.



![$\displaystyle {\bf x}=\left[\begin{array}{c}x_1\\ x_2\\ x_3\\ x_4\\ x_5\end{arr...
...y}\right],\;\;\;\;
{\bf b}=\left[\begin{array}{c}18\\ 60\\ 40\end{array}\right]$](img1074.svg)


 .
.
![$\displaystyle \begin{tabular}{ll}
min: & $f({\bf x})=[{\bf x}-{\bf m}]^T{\bf Q}...
... h}({\bf x})={\bf A}{\bf x}-{\bf b}={\bf0},\;\;{\bf x}\ge {\bf0}$
\end{tabular}$](img1088.svg)
![$\displaystyle {\bf Q}=\left[\begin{array}{rr}4 & -1\\ -1 & 4\end{array}\right],...
...d{array}\right],\;\;\;
\left[\begin{array}{rr}3 & -1\\ -1 & 3\end{array}\right]$](img1089.svg)
![$\displaystyle {\bf m}=\left[\begin{array}{r}4\\ 10\end{array}\right],\;\;\;
\le...
...r}7\\ 2\end{array}\right],\;\;\;
\left[\begin{array}{r}-1\\ 6\end{array}\right]$](img1090.svg)