


Next: The middle layer
Up: The Models
Previous: The Models
The input layer is composed of MT nodes each responding preferentially to a
local translational motion of a particular direction. The visual area under
consideration can be considered as being composed of
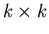 patches
of the same size as the receptive field of the MT neurons. Each patch is
represented by 8 MT nodes of 8 different preferred motion directions. These MT
nodes are binary and they are usually off unless a local motion is detected
in the patch, in which case one of the 8 nodes whose preferred direction is
closest to the motion direction is turned on. For simplicity, only the
direction of each vector of the flow field was used in the model to represent
the motion. The magnitude of the vector was ignored. Among all possible
patterns that may be formed in the k by k array of vectors, we are only
interested in those that represent optic flow patterns such as the different
types of motions shown in Fig.
patches
of the same size as the receptive field of the MT neurons. Each patch is
represented by 8 MT nodes of 8 different preferred motion directions. These MT
nodes are binary and they are usually off unless a local motion is detected
in the patch, in which case one of the 8 nodes whose preferred direction is
closest to the motion direction is turned on. For simplicity, only the
direction of each vector of the flow field was used in the model to represent
the motion. The magnitude of the vector was ignored. Among all possible
patterns that may be formed in the k by k array of vectors, we are only
interested in those that represent optic flow patterns such as the different
types of motions shown in Fig. ![[*]](/usr/local/latex2html/icons.gif/cross_ref_motif.gif) . There are in total
8+8k2 input patterns including 8 translations of different directions, and
8 radial, circular and spiral motion patterns each of k2 COM locations.
. There are in total
8+8k2 input patterns including 8 translations of different directions, and
8 radial, circular and spiral motion patterns each of k2 COM locations.
Similar to the MT model, here again we need to account for the noises of
different types in the real image, caused by missing or false local motion
information, due to either homogeneous luminance, or the aperture problem.
These noises are simulated the same way as in the MT model case.
Next: The middle layer
Up: The Models
Previous: The Models
Ruye Wang
2000-04-25