Next: Median Filter Up: smooth_sharpen Previous: smooth_sharpen
Image sensors and transmission channels may produce certain type of noise characterized by random and isolated pixels with out-of-range gray levels, which are either much lower or higher than the gray levels of the neighboring pixels. Such noise can be treated as some impulses corresponding to high spatial frequencies.
For example, digital photos taken under low illumination have low signal-to-noise ratio and are characterized by such random noisy pixels.
The challenge of suppressing and removing such noise is to distinguish between this type of isolated and out-of-range noise and other legitimate signal components such as the details, edges, lines, small features, etc. in the image, as both correspond to high frequency components in the image data, so that we can preserve the former while suppressing the latter.
One way to remove such noise is to replace each pixel by the average of the pixels in a small neighborhood so that the noise of out-of-range gray levels are reduced. Equivalently, this averaging operation in spatial domain corresponds to low-pass filtering in the spatial frequency domain, by which the high-frequency components are removed.
The averaging operation is a weighted sum of the pixels in a small
neighborhood, typically of odd size in each dimension, i.e.,
 such as 3x3, 5x5, 7x7, although even-sized
neighborhood can also be used. Such operation is typically implemented
as a convolution with a symmetric kernel
such as 3x3, 5x5, 7x7, although even-sized
neighborhood can also be used. Such operation is typically implemented
as a convolution with a symmetric kernel
![$w[m,n]=w[-m,-n]$](img2.svg) of certain
shapes and values:
of certain
shapes and values:
![$\displaystyle y[m,n]$](img3.svg) |
 |
![$\displaystyle \sum \sum_{-k\le i,j \le k} w[i,j]\;x[m-i,n-j]
=\sum \sum_{-k\le i,j \le k} w[-i,-j]\;x[m+i,n+j]$](img5.svg) |
|
|
![$\displaystyle \sum \sum_{-k\le i,j \le k} w[i,j]\;x[m+i,n+j]$](img6.svg) |
(1) |
![$w[i,j]=w[-i,-i]$](img7.svg) is a symmetric kernel of a limited size (typically
odd). Some common kernels are shown below:
is a symmetric kernel of a limited size (typically
odd). Some common kernels are shown below:
![$\displaystyle w_1=\frac{1}{4}\left[ \begin{array}{cc} 1 & 1 \\ 1 & 1 \end{array...
...ft[ \begin{array}{ccc} 1 & 1 & 1 \\ 1 & 1 & 1 \\
1 & 1 & 1 \end{array} \right]$](img8.svg) |
(2) |
![$\displaystyle w_4=\frac{1}{10}\left[ \begin{array}{ccc} 1 & 1 & 1 \\ 1 & 2 & 1 ...
...ft[ \begin{array}{ccc} 1 & 2 & 1 \\ 2 & 4 & 2 \\
1 & 2 & 1 \end{array} \right]$](img9.svg) |
(3) |
The weighting of these convolution kernels is based on the assumption of spatial locality, i.e., the closer two pixels are, the more they are correlated. Consequently, closer neighbors of a pixel should be weighted more than those that are farther away.
These convolution kernels can be considered as the approximations of some continuous 2D functions such as a rectangular function
 |
(4) |
 |
(5) |
 is equivalent
to the filtering in spatial frequency domain
is equivalent
to the filtering in spatial frequency domain  with the Fourier
transforms of the kernel functions:
with the Fourier
transforms of the kernel functions:
 |
(6) |
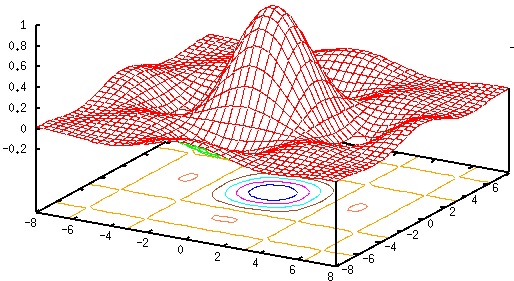 and
and
 |
(7) |
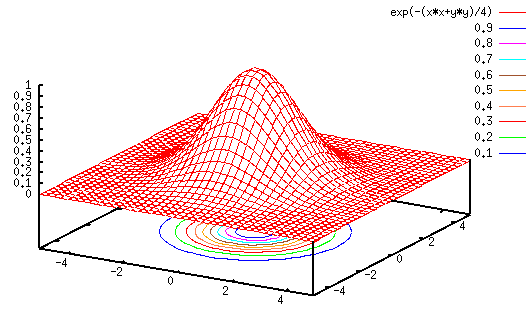
In general the Gaussian function is a preferred method for the following reasons:
The algorithms below represent various efforts made to distinguish noise components from legitimate signal components.
Weymouth-Overton's algorithm
This algorithm is based on the idea that in the averaging process, greater weight should be assigned to pixels that are
 for the distance and
for the distance and  for the pixel value:
for the pixel value:
![$x[i,j]$](img18.svg) in the neighborhood W of the pixel
in the neighborhood W of the pixel
![$x[m,n]$](img19.svg) under consideration. The distance weight is defined as:
under consideration. The distance weight is defined as:
![$\displaystyle w_d[i,j]=\frac{1}{1+\sqrt{(m-i)^2+(n-j)^2}}$](img20.svg) |
(8) |
![$\displaystyle w_v[i,j]=\frac{1}{1+[x[i,j]-x[m,n]]^\alpha}$](img21.svg) |
(9) |
 is a user specified parameter. The overall weight for pixel
is defined as
is a user specified parameter. The overall weight for pixel
is defined as
![$\displaystyle w[i,j]=w_d[i,j]\; w_v[i,j]$](img23.svg) |
(10) |
in both distance and gray scale value will be
assigned larger weights.
by
![$\displaystyle y[m,n]=\frac{\sum_{(i,j)\in W} w[i,j] x[i,j]}{\sum_{(i,j)\in W} w[i,j] }$](img24.svg) |
(11) |
Statistical thresholding
First find the mean  and the variance
and the variance  of all pixels
in the neighborhood
of all pixels
in the neighborhood  of a given pixel of the input image:
of a given pixel of the input image:
![$\displaystyle \mu=\frac{1}{N} \sum_{(i,j) \in W} x[i,j]$](img28.svg) |
(12) |
![$\displaystyle \sigma^2=\frac{1}{N} \sum_{(i,j) \in W} [x[i,j]-\mu]^2$](img29.svg) |
(13) |
 is the number of pixels in the neighborhood .
is the number of pixels in the neighborhood .
Then find the corresponding pixel for the output image:
![$\displaystyle y[m,n]=\left\{ \begin{array}{ll}
x[m,n] & \mbox{if $\vert x[m,n]-\mu\vert < \sigma T$} \\ \mu & \mbox{else}
\end{array} \right.$](img31.svg) |
(14) |
 is a user specified threshold value.
is a user specified threshold value.
Nagao's algorithm
under consideration,
for example, the eight 3x3 neighborhoods in N, NE, E, SE, S, SW, W, and NW directions.
The pixel should be included as a corner in each of these neighborhoods.
 and variance
and variance
 for each of the K neighborhoods.
for each of the K neighborhoods.
by the mean value of the neighborhood having the smallest
and therefore most reliable:
![$\displaystyle y[m,n]=\mu_i, \;\;\;\;\;$](img35.svg) iff iff |
(15) |
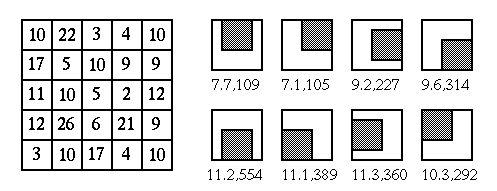
In this example, the pixel in question ![$x[m,n]=5$](img37.svg) is replaced by the mean 7.1 from
the northeast neighborhood with minimum variance 105.
is replaced by the mean 7.1 from
the northeast neighborhood with minimum variance 105.