Next: Computation of the KLT Up: Principal Component Analysis Previous: Optimality of KLT
The optimality of the KLT discussed above can be demonstrated
geometrically, based on the assumption that the random vector
![${\bf x}=[x_1,\cdots,x_d]^T$](img2.svg) has a normal probability density
function:
has a normal probability density
function:
![$\displaystyle p(x_1,\cdots, x_d)=p({\bf x})
={\cal N}({\bf x}, {\bf m}_x, {\bf\...
...[ -\frac{1}{2}({\bf x}-{\bf m}_x)^T{\bf\Sigma}_x^{-1}({\bf x}-{\bf m}_x)\right]$](img264.svg) |
(72) |
 and covariance matrix
and covariance matrix
 . The
shape of this normal distribution in the d-dimensional space can be
represented by the iso-hypersurface in the space determined by the
equation
. The
shape of this normal distribution in the d-dimensional space can be
represented by the iso-hypersurface in the space determined by the
equation
 |
(73) |
 is some constant. This equation can be converted into an
equivalent equation:
where
is some constant. This equation can be converted into an
equivalent equation:
where  is another constant related to .
As
is another constant related to .
As
 is positive definite as well as
is positive definite as well as
 ,
this equation represents an hyper ellipsoid in the d-dimensional space.
In particular, when
,
this equation represents an hyper ellipsoid in the d-dimensional space.
In particular, when  ,
,
![${\bf x}=[x_1,\,x_2]^T$](img271.svg) , with positive definite
, with positive definite
 :
:
![$\displaystyle {\bf\Sigma}_x^{-1}=\left[ \begin{array}{cc} A & B/2 \\ B/2 & C \end{array} \right]
\;\;\;\;\;\;$](img272.svg) and and |
(75) |
 |
 |
![$\displaystyle [x_1-\mu_{x_1}, x_2-\mu_{x_2}]
\left[ \begin{array}{cc} A & B/2 \...
...ght]
\left[ \begin{array}{c} x_1-\mu_{x_1} \\ x_2-\mu_{x_2} \end{array} \right]$](img275.svg) |
|
|
 |
![${\bf m}_x=[\mu_1,\;\mu_2]^T$](img277.svg) . When
. When
 , the quadratic equation represents an ellipsoid. In general when
, the quadratic equation represents an ellipsoid. In general when
 , the equation
, the equation
 represents a hyper-ellipsoid in the d-dimensional space.
represents a hyper-ellipsoid in the d-dimensional space.
Substituting
 and
and
 into
the iso-surface equation Eq. (74), we get the equation
for the hyper-ellipsoid after the KLT
into
the iso-surface equation Eq. (74), we get the equation
for the hyper-ellipsoid after the KLT
 :
:
![$\displaystyle ({\bf x}-{\bf m}_x)^T {\bf\Sigma}_x^{-1} ({\bf x}-{\bf m}_x)
=[{\bf V}({\bf y}-{\bf m}_y)]^T{\bf\Sigma}_x{\bf V}({\bf y}-{\bf m}_y)$](img283.svg) |
|||
|
 |
||
|
 |
(76) |
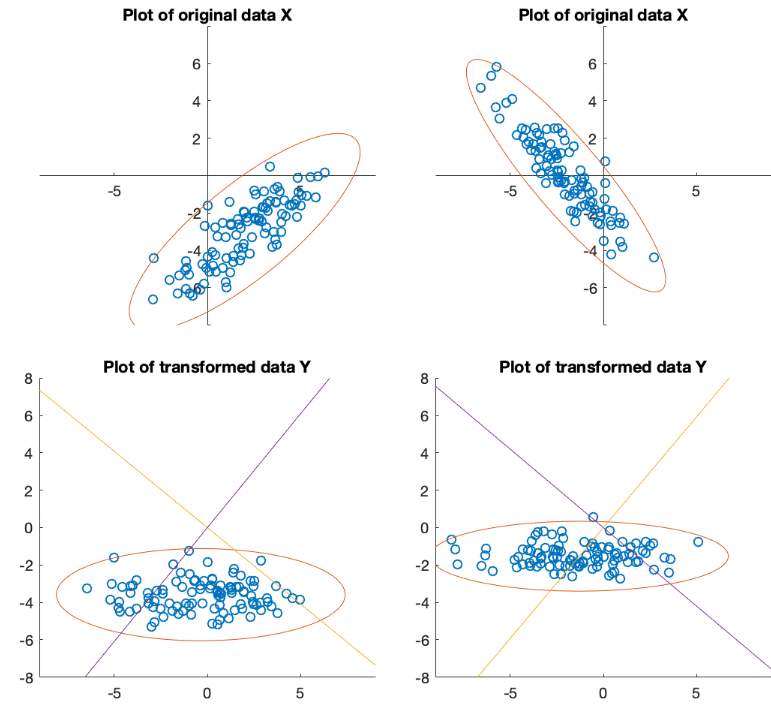
is actually a rotation of the
coordinate system of the d-dimensional space, which is spanned by
the standard basis
 before the KLT
and the eigenvectors
before the KLT
and the eigenvectors
 as the basis
vectors after the KLT.
as the basis
vectors after the KLT.
As the result, the principal semi-axes of the ellipsoid representing
the Gaussian distribution of the dataset become in parallel with
the axes of the new coordinate system, i.e., the ellipsoid becomes
standardized. Moreover, the length of the ith principal semi-axis
is proportional to the standard deviation
 of the ith variable
of the ith variable  . This is the reason why KLT possesses
the two desirable properties: (a) the decorrelation of the signal
components, and (b) redistribution and compaction of the energy or
information contained in the signal, as illustrated in the figure
below.
. This is the reason why KLT possesses
the two desirable properties: (a) the decorrelation of the signal
components, and (b) redistribution and compaction of the energy or
information contained in the signal, as illustrated in the figure
below.
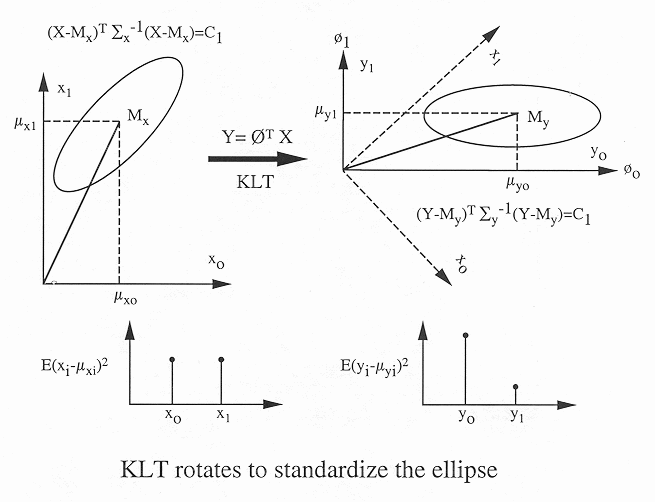
Examples