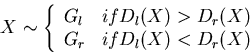Next: About this document ...
Tree Classifiers
When both the number of classes c and the number of features n are large,
the feature selection and classification discussed before encounter
difficulties because
- feature selection is no longer effective as it is difficult to find
m features from n which are suitable for separating all the c classes
(some features may be good from some classes but not good for others).
- classification is costly as a large number of features are necessary.
The solution is to do classification in several steps implemented as a tree classifier. One method to design the tree classifier in the bottom-up
merge algorithm described in the following steps, which is considered as the
training process.
- From the training samples of each class
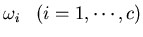 ,
estimate the mean and covariance:
,
estimate the mean and covariance:
and
- Compute pair-wise Bhattacharrya distances between classes for all
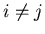 (c(c-1)/2 of them in total):
(c(c-1)/2 of them in total):
- Merge the two classes with the smallest Dij to form a combined
class:
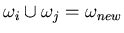 with the following
mean and covariance:
with the following
mean and covariance:
and
Delete the old classes 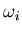 and
and 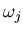 .
.
- Compute the distance between the new class
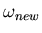 and all the
remaining classes (excluding
and ).
and all the
remaining classes (excluding
and ).
- Repeat the above steps until eventually all classes are merged into one
and a binary tree structure is thus obtained.
- At each node of the tree build a 2-class classifier to be used to
classify a sample into one of the two children Gl and Gr
representing the two groups of classes. According to the classification
method used, we find the discriminant functions Dl(X) and Dr(X).
- At each node of the tree adaptively select features that are best
for separating the two groups of classes Gl and Gr. Any feature
selection method can be used here, such as between-class distance
(Mahananobis distance), or orthogonal transform (KLT, DFT, WHT, etc.).
A small number of selected features may be needed as here only
two groups of classes need to be distinguished.
After the classifier is built and trained, the classification is carried out
in the following manner:
A testing sample X of unknown class enters the classifier at the root of
the tree and is classified to either the left or the right child of the node
according to
This process is repeated recursively in the same fashion at the child node
(either Gl or Gr) and its child and so on, until eventually X reaches
a leaf node corresponding to a single class, to which the sample X is
therefore classified. In this classification method.
Next: About this document ...
Ruye Wang
1999-06-10
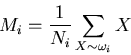
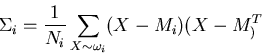
![\begin{displaymath}D_{ij}=\frac{1}{4}(M_i-M_j)^T\left[\frac{\Sigma_i+\Sigma_j}{2...
...gma_i\right\vert\;\left\vert\Sigma_j\right\vert)^{1/2}}\right]
\end{displaymath}](img6.gif)
![\begin{displaymath}M_{new}=\frac{1}{N_i+N_j}[N_i M_i+N_j M_j] \end{displaymath}](img8.gif)
![\begin{displaymath}\Sigma_{new}=\frac{1}{N_i+N_j}
[N_i (\Sigma_i+(M_i-M_{mew})(M_i-M_{mew})^T)+
N_j (\Sigma_j+(M_j-M_{mew})(M_j-M_{mew})^T ) ]
\end{displaymath}](img9.gif)