Given a 2-D function ![]() , the gradient descent method finds
, the gradient descent method finds ![]() so that
so that
![]() .
.
First consider 1D case. We see that ![]() is always in the opposite
direction of the increasing direction of
is always in the opposite
direction of the increasing direction of ![]() :
:
Then consider 2D case where the derivative used in 1D case becomes gradient
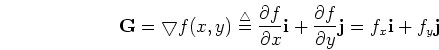
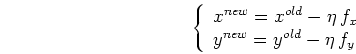
Obviously the gradient descent method can be generalized to minimize high
dimensional functions
![]() .
.